Blog
新規プロダクトでKubernetesを中心にCloudNativeなアーキテクチャのインフラを導入した話
はじめに
アドテク本部Airtrackチームの横山(@nnao45)です。
チーム内ではScala書いたり〜K8Sと遊んだり〜AWSったり〜しています。
この度Airtrackチームの新規プロダクトでKubernetesを採用し、本番環境に投入したのでその知見を共有させた頂きます。
おしながき
- 目指したアーキテクチャ
- Kubernetes周り
- ミドルウェア
- CI/CD
- 監視
- 感想
目指したアーキテクチャ
妥協はしないが身の丈にあったコンテナプラットフォーム って感じですかね。
Kubernetes周り
サービスレイヤひとまわり
Airtrackチームで広告系完全新規プロジェクトの立ち上げに
Kubernetes中心にクラウドネイティブなアーキテクチャ意識して設計しました。
描れている4つの六角形のやつが今回僕らの広告系のプロダクトでサービスとして動かしているサーバで、このうち2つをフロント、2つをサーバサイドの関係にあります。
このサービスを中心に組み立てるにあたって設計で迷った次の点をまずは紹介させて頂きます。

お悩みポイント
- 結構スモールスタートだけど、なんでk8sで採用したの?
- KubernetesのサービスはIngress?Nodeport?
- ログの置き場所をどうするか in AWS
結構スモールスタートだけど、なんでk8sで採用したの?どうだった?
とりあえず全く新規で始めるので、ワークロードはコンテナで考えたかったのは間違いないです。インフラの依存性を安全に切り離せるのはもちろん、特にDockerはアプリをリリースするのとインフラの(上澄みの)ライフサイクルを併せられるので、アプリエンジニアの手に馴染みやすいのも大きな利点です。
そしてAirtrackではほぼ全てのコンポーネントがAWS上にあり、必然的にECS Fargateも選択肢に入ってきました。
正直、ぶっちゃけFargateでも良かったです。EKS vs Fargateは以下のブログが詳しい。
https://www.bmc.com/blogs/aws-ecs-vs-eks/
ALBからpodに落ちるまでのホップ数(EKSというかKubernetes)や、他のAWSサービスとの連携などはFargateの方が良いでしょうね。
結果的にEKSを採用した理由として、
- OSSコミュニティの盛り上がり、拡張性の強さ。
- そこまでレイテンシにシビアなサービスではなかった
- @nnao45君がKubernetesの方が圧倒的に慣れてた、また他のメンバーのKubernetesへの勉強も進んでいて、社内事例も多かったので。
- 採用面で強く出れそう。なお、AirtrackチームではKubernetesをバリバリ触ってみたいエンジニアを絶賛募集していまs(ry
- 将来的にオンプレやGKEへの移行という話になってもスムーズに行きそう & 他のチームでGKEとかオンプレk8s動かしてた人も入りやすくなりそう
という少々生々しい感じで、多分性能面というよりかはチームビルディングの過程による色が強かったかもしれません。
また載せたサービス群がそれほど多くないのでK8Sではtoo muchではなんていう懸念もありましたが、
後述するCD面やクラスターの拡張性の面でこの規模でさえK8Sから得られる恩恵は意外に大きかったです。
KubernetesのサービスはIngress?Nodeport?
うーんどっちもどっちって感じでした。
「Ingressはまだ使うな」という論と「alb-ingress-controller強いからイケる」という論があり、難しかったです。
alb-ingress-controllerは僕の予想それでもポツポツと本番投入しているプロダクトは出てきてるんじゃないかな?と思っています
https://github.com/kubernetes-sigs/aws-alb-ingress-controller
annotationでalbの設定を投入できたり、証明書を紐付けたりできるみたいで悪くなさそうですね。
ただ、僕は個人的にはEKSとしてはNodeportによるサービスバインドが優れていると感じました。
1. AWSの世界とKubernetesの世界を分離したかった
これは非常に重要な観点と感じていて、チームとして大きなメリットを得ることができます。
IngressによりALBまで管理することによって「Kubernetesのmanifestに何かしらのアクションをしないとALBができない(=サービスコントロールができない)」という状態になります。
IngressでALBをmanifest管理できるのは確かにメリットかも知れませんが、ALBを「AWSリソースを立てる」という手立てで管理にしておくとVM時代と同様な手順で「AWSが触れる人」でもサービスコントロールできるようになります。
マイグレのような対応をするときにクラスターを複製するときに、ALBも複製されたり色々面倒だったりします。
2. 適当なローカルクラスタを作りやすくなる。
例えばminikubeで本番環境と全く同じ検証環境を作成したくなっても、VMとDBだけ用意すればよく、そしてVMとDBは頑張れば1個の物理マシンで済ませられるので検証に便利です。
クラウドベンダのLBがあること前提の環境にしてしまうより差分が少なくなるはずです。
ログの置き場所をどうするか in AWS
当然標準出力だろという話に思えた。
しかし、ローンチ時点でサーバサイド内で分析したいログとそうでないログがあり、それをログの出力内容としてjson化してタグで分別するのが厳しそうでした。
よって分析ログだけ物理ログとしてどっかに置いておいてfluentdで飛ばそうとなりました。しかし・・・。
AWS EKS, Volumes architecture in a statefull app. in multiple AZ’s
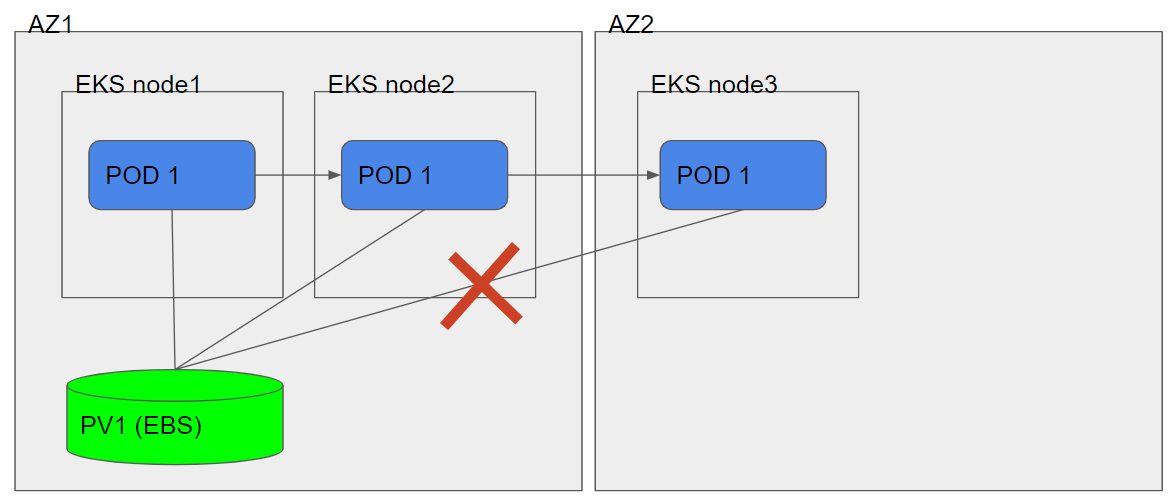
単純にEBSマウントしログを置くとAZ跨ぎで実装することが出来ません。
今回、僕らの環境ではマルチAZな構成にしているのでこれにぶち当たってしまいました・・・。
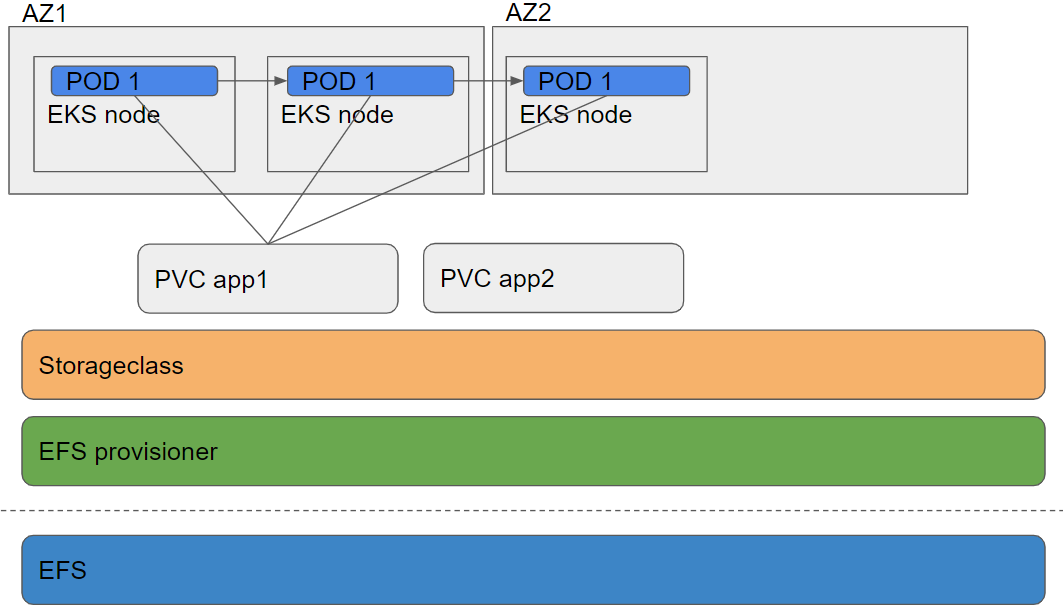
マルチAZ構成でのPersistent VolumeはEFSによって構成すれば、マウントするpodがどこのAZにいても大丈な構成にしました。
今後、このEFSがAZをまたぐ構成がクリティカルな負荷になる可能性はありますが、その時はnode taintも視野に入れて採用に至りました。
しかし・・・・・・
https://github.com/kubernetes-incubator/external-storage/tree/master/aws/efs
なんとこの公式のEFS Dynamic Provisioner、動かない >< 理由がわからん。
頑張ってググったところ、helmの方が動くようなので、此方のEFS Dynamic Provisionerを使用しました。
https://github.com/helm/charts/tree/master/stable/efs-provisioner
これにより、分析ログはこのEFS上に配置してfluentdでtailすることによって解決しました。
最後に注意点ですが、こういうkubelet配下にないログの場合はローテーションを考えなければいけません。
今回の構成では他のプロダクトでも使っているJavaの伝統的なログマネージメントライブラリのlogbackを使って実現しています。
ミドルウェア
ミドルウェア周りは大量にあるので、特筆点のみ紹介します。
Aurora(データ移行)
リレーショナルなデータベースにはAuroraを選びました。強いからです。
https://aws.amazon.com/jp/rds/aurora/
インフラ観点で特別な事はしてないのですが、今回特筆する点といえばproduction→stagingへのデータ移行の点でしょうか。
今回の環境では結構インプレッションの上下が激しく、データに関してもstagingはproduction同等ものを用意しました。
ここに関してはそのうち①いつでも発火できるジョブ②早朝に回るバッチとしてdockerコンテナがrunする仕組みをkubeのCronJobで実現する予定です。
docker自体はシェル叩くだけのコンテナですが、Auroraでは叩くシェルも非常に単純なシェルで実現できます。
何と、ほぼ全てのデータ移行がSQL4行で終わっています。
|
1 2 3 4 5 6 7 8 |
# テーブル名を全部持ってくる。 SHOW tables FROM ${DATABASE_NAME} # テーブルごとにproductionのデータをs3に保存する。 SELECT * FROM ${DATABASE_NAME}.${TABLE} INTO OUTFILE S3 's3://${S3_AURORA_BUCKET}/${TABLE}/table' OVERWRITE ON # テーブルごとにstagingのテーブルをTRUNCATEする。 TRUNCATE TABLE ${DATABASE_NAME}.${TABLE} # テーブルごとにstagingのテーブルをs3からロードする。 LOAD DATA FROM S3 PREFIX 's3://${S3_AURORA_BUCKET}/${TABLE}/table' INTO TABLE ${DATABASE_NAME}.${TABLE} |
このS3にSELECT文のデータを送り、LOADするのはAuroraバージョンv1.13から使えるんだそう。
ネットでは色々情報が錯綜してますが、今回使用したAurorav2.03系でもこの機能は(上記のクエリを発行するだけなら)使えます。
そんなとこです。
Botkube
僕が気に入ってるミドルウェアの一つにbotkubeがあります。
https://github.com/infracloudio/botkube
僕自身コントリビューションもしているので是非使ってみてください。
このツールはslackからreadonlyなオペレーションをchatで投げれるのと、kubernetesのイベント監視をしてくれます。小回りがきいて便利です。


bokube君のおかげで、kubectlをslackからクラスタに投げたり、getコマンドをチームで共有、履歴保存できて重宝しています。
Fluentd
fluentdですが、野良プラグインが使いたかったりしたので、今回は野良レポジトリのを応用してビルドしております。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
FROM fluent/fluentd:latest-onbuild WORKDIR /home/fluent COPY /entrypoint.sh /home/fluent/entrypoint.sh ENV PATH /home/fluent/.gem/ruby/2.3.0/bin:$PATH # We need root access to read container logs USER root RUN apk --no-cache --update add build-base ruby-dev && \ gem install fluent-plugin-s3 fluent-plugin-docker && \ rm -rf /root/.gem/ruby/2.3.0/cache/*.gem && gem sources -c && \ apk del build-base ruby-dev && rm -rf /var/cache/apk/* ENTRYPOINT ["sh", "entrypoint.sh"] |
<追記 20190828>
↑の fluent/fluentd:latest-onbuild は古いイメージを使っているとご指摘いただいたので、asspで直しました😌いんたーねっつはあったけえ
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
FROM fluent/fluentd:v1.7-debian-1 WORKDIR /home/fluent COPY entrypoint.sh /home/fluent/entrypoint.sh ENV PATH /home/fluent/.gem/ruby/2.3.0/bin:$PATH # We need root access to read container logs USER root RUN buildDeps="sudo make gcc g++ libc-dev" && \ apt-get update && \ apt-get install -y --no-install-recommends $buildDeps && \ sudo gem install fluent-plugin-s3 && \ sudo gem install fluent-plugin-docker && \ sudo gem sources --clear-all && \ SUDO_FORCE_REMOVE=yes \ apt-get purge -y --auto-remove \ -o APT::AutoRemove::RecommendsImportant=false \ $buildDeps && \ rm -rf /var/lib/apt/lists/* && \ rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem ENTRYPOINT ["sh", "entrypoint.sh"] |
参考:https://github.com/fluent/fluentd-docker-image
</追記 20190828>
参考:https://github.com/ccpgames/kubernetes-fluentd-s3
余談ですが、コンテナで動かすfluentd_confを書く場合は、環境変数を埋め込める記法を覚えておくとセキュアです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
<match **> @type s3 log_level info s3_bucket "#{ENV['S3_LOGS_BUCKET_NAME']}" s3_region "#{ENV['S3_LOGS_BUCKET_REGION']}" s3_object_key_format %{path}%{time_slice}/cluster-log-%{index}.%{file_extension} path "#{ENV['S3_LOGS_BUCKET_PREFIX']}" buffer_path /fluentd/log/s3-buffer flush_interval 60s time_slice_format %Y/%m/%d time_slice_wait 10m utc <instance_profile_credentials> ip_address 169.254.169.254 port 80 </instance_profile_credentials> </match> |
#{ENV['<環境変数名>']} を使うことによって、環境変数から引っ張ってこれます。
Gatling as a Service
少し番外編として負荷試験ツールも紹介しておきます。
以下の理由でgatlingをas a serviceとして作りたいって思いたちました。
- 負荷試験サーバってtoo fatの金食い虫
- 別にずっと流す必要がない
- 環境が汚れがち
つーことで作りました。
構成としては図にするまでもなかったのですが、Codebuild + Gatling + Dockerです。
つまりCodebuildでdocker runするだけです。
他のAWSのサービスではなくCodebuildでGatlingを実行する理由ですが、
- lambdaはログがだるい
- aws batchみたいにECSサービスを立ち上げるまでもない
- aws barchみたいに定期的に実行したいわけでもない
- 「dockerで」揮発的にジョブ実行したい(移植可能な状態にしたい)
- gatling自体がシェルとかsbt越しで実行される事を期待されている
な感じです。
記念に使ったDokerfileを置いておきますが、インストールしてるだけです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# Gatling is a highly capable load testing tool. # # Documentation: https://gatling.io/docs/3.0/ # Cheat sheet: https://gatling.io/docs/3.0/cheat-sheet/ FROM openjdk:8-jdk-alpine # working directory for gatling WORKDIR /opt # gating version ENV GATLING_VERSION 3.0.3 # create directory for gatling install RUN mkdir -p gatling # install gatling RUN apk add --no-cache --update tzdata zip curl wget bash libc6-compat && \ mkdir -p /tmp/downloads && \ wget -q -O /tmp/downloads/gatling-$GATLING_VERSION.zip \ https://repo1.maven.org/maven2/io/gatling/highcharts/gatling-charts-highcharts-bundle/$GATLING_VERSION/gatling-charts-highcharts-bundle-$GATLING_VERSION-bundle.zip && \ mkdir -p /tmp/archive && cd /tmp/archive && \ unzip /tmp/downloads/gatling-$GATLING_VERSION.zip && \ mv /tmp/archive/gatling-charts-highcharts-bundle-$GATLING_VERSION/* /opt/gatling/ && \ rm -rf /tmp/* # setup TZDATA RUN cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ echo "Asia/Tokyo" > /etc/timezone COPY entrypoint.sh /opt/gatling/entrypoint.sh COPY user-files /opt/gatling/user-files # change context to gatling directory WORKDIR /opt/gatling # set environment variables ENV PATH /opt/gatling/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin ENV GATLING_HOME /opt/gatling ENTRYPOINT ["/opt/gatling/entrypoint.sh"] |
参考: https://github.com/denvazh/gatling/blob/master/3.0.3/Dockerfile
cloudbuildにbuildが走るとslackに通知してくれてレポートも飛ばしてくれるようにしてます、普通にzipコマンドで固めてcurlで飛ばしてるだけですがこうすると便利なのでオススメです(^^)!
CI/CD
今回の構成では以下のようなCI/CD基盤としました。GitOpsですね(正確には少し違うのだけれど)。
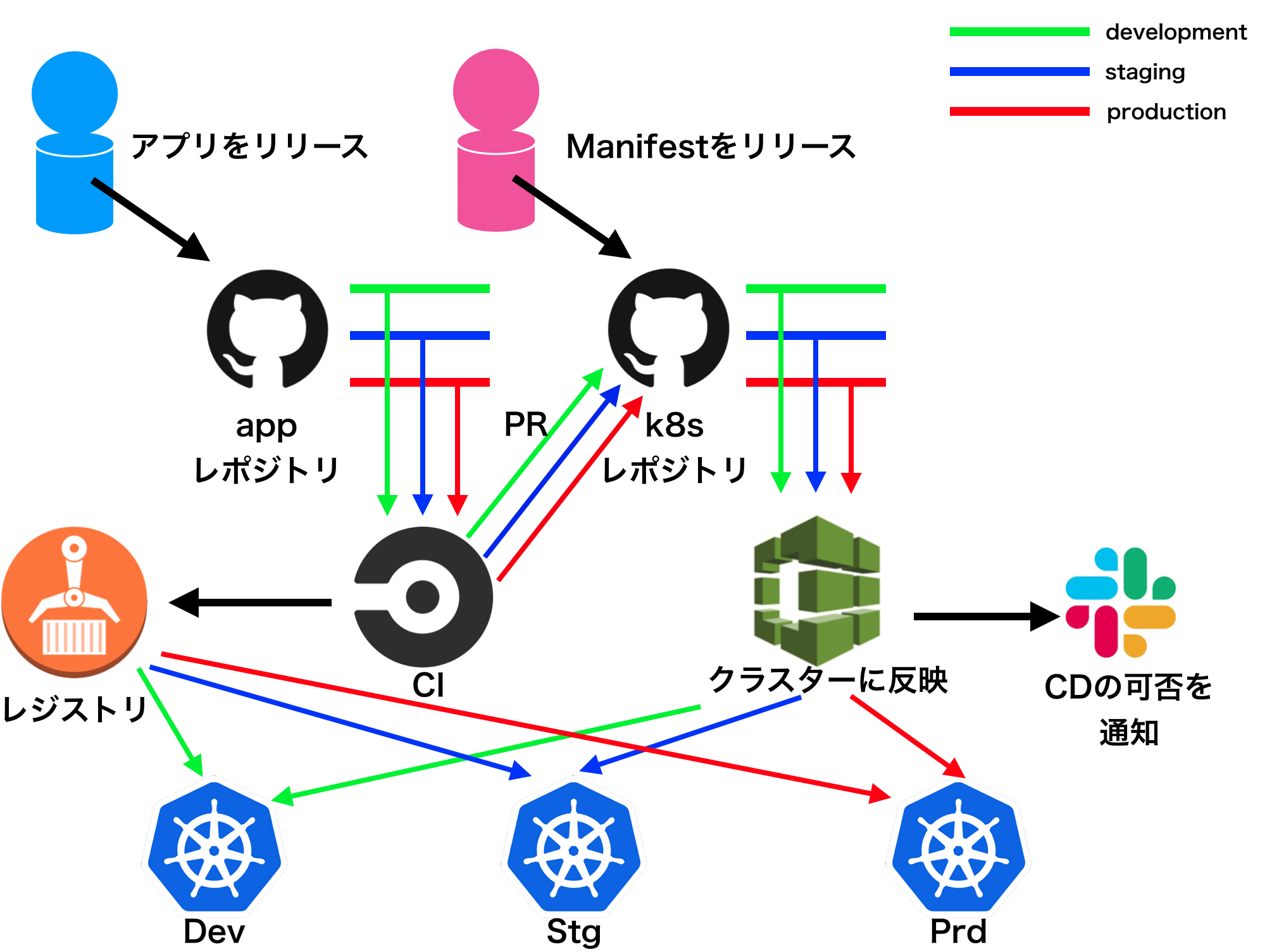
ほぼ図に全て書いてあるので、今回も以下の特筆点だけ。
- ぼくがかんがえたちょっとつよいぎっとおぷすもどき
- CircleCIからk8sレポジトリへはプルリク、ただしdevelopmentはマージコミット
- マニフェスト管理にはkubectlのみ、helm、kustomizeは使わない
- kubectl発火はCodepipeline/Codebuild
app、k8sどちらもdevとstgとprdを表すブランチへのマージコミットを起点にCI/CDが発火されます。
ぼくがかんがえたちょっとつよいぎっとおぷすもどき
- 大部分のオペレーションからkubectlの排除
- アプリを触る人が、Githubだけでリリースが完結する
- manifestの変更だけでもリリースできる
- リリースの可否もslackを見ればいい(=デバック以外でkubectlを使わせない)
- git pushからリリースまで大部分をマネージド、自動化することで開発者へのストレスをゼロに近づける
ほぼほぼこれらは実現でき、非常に好評でした(^_^)v
CircleCIからk8sレポジトリへはプルリク、ただしdevelopmentはマージコミット
最初、ScalaとVueのコンテナのコードのテストだけをCircleCIに任せていたのですが、
ここからLambdaとか何か生やしたりするのが面倒だったのでCircleCIにdocker buildまでさせてECRにプッシュしています。
注意点はECRにイメージがあるかどうか怖いので、CIの最後にそのコンテナのpullにより実在することを保証しています
devはプルリクじゃなくてマージコミットを(=アプリのCIがOKならそのままクラスタに反映)した理由は、単純に「devはリリースタイミングはCIが通ったら行ったらいつでも」であったので、それならプルリクにする必要がなかったからです。
また余談ですが、実はプルリクに工夫をしていまして、何とそのイメージタグにどういうアプリの変更が含まれたかの情報を入れています。
これスミマセン、アプリレポジトリ側のCIの時で使っているシェル芸です…!
|
1 2 |
BEFORE_MERGED_COMMIT_HASH=$(git log -1 --pretty=format:"%P" | awk '{print $1}') git log --pretty="%H %s" ${BEFORE_MERGED_COMMIT_HASH}...${CIRCLE_SHA1} --no-color | sed "s@^@https://github.com/xxxx/yyyy/commit/@g" > tee /tmp/commit_list.md |
詳しくは長くなるので書きませんがこれは凄い便利なのでこの情報をつけてプルリクを自動生成すると運用する人に凄い喜ばれます✌︎(‘ω’✌︎ )
|
1 |
echo -e "${COMMENT}\n\n## Git History\n$(cat /tmp/commit_list.md)" | hub pull-request -b ${ORG}:${MERGE_BRANCH} -h ${ORG}:${BRANCH} -F - |
マニフェスト管理にはkubectlのみ、helm、kustomizeは使わない
これは賛否両論なとこでしょう^^;
個人的に今回の規模であれば、helmなどによるテンプレーティングよりもむしろ単純に kubectl apply -f できない、また反映される実物はレポジトリ内で閲覧できないという点の方デメリットに感じての事です(ちなみにhelm templateでmanifestを持ってきたりしてはいます)。
マニフェストの内容も変えるとしたらイメージタグやレプリカくらいなので、これはこれで良かったと感じています。
またアプリのビルドが成功したらマニフェストのイメージを変更するわけですが、これも実はkubectlコマンドでできます。
|
1 2 3 4 5 |
kubectl set image \ -f <イメージを変えたいマニフェスト> \ <イメージを変えたいデプロイメント>=<変えたいイメージ> \ --local \ -o yaml |
–localでapiと通信しない、-o yaml でyamlで出力する、これを使う事でsedでシェル芸しなくてもイメージ変更することができます。
kubectl発火はCodepipeline/Codebuild
色々考えましたが、AWSメインで要件を満たしていたので採用しました。
ブログを書いてる時点ではcodepipelineによってsourceステージを指定すると、master以外のブランチを指定できるようになるのでcodepipelineからcodebuildを呼び出す構成になっています。
工夫点としては、k8sのmanifest側のディレクトリ構成が
|
1 2 3 4 5 6 7 8 |
❯❯❯ tree -NC ./ ./ ├── kubesec │ ├── hoge_secret.yaml │ └── piyo_server_secret.yaml └── manifests ├── mayo_dep.yaml ├── sio_cm.yaml |
みたいにしております。今回kubesecを使っていて、単純にkubectlをぶちかませばいい構成ではないので、最終的に発火しているbuildspec.yml(=dockerのENTRYPOINT)はこんな感じです。
|
1 2 3 4 5 6 7 8 9 10 |
version: 0.2 phases: build: commands: - aws eks update-kubeconfig --name <EKSのクラスター名> - kubectl get all --all-namespaces - kubectl apply --dry-run -f manifests && kubectl apply -f manifests - ls -1 kubesec | while read manifest; do echo '---'; kubesec decrypt kubesec/$manifest;done | kubectl apply -f - - kubectl get all --all-namespaces |
ポイントは、
- applyする前に
kubectl apply --dry-runしてテストしておく。 - 4行目、シェル芸をかまして
kubesec decryptをかましてから、複数のyamlを一枚の標準出力にするために文頭に---入れて〜最後にkubectl applyしています。これでkubesecでkubesec encryptされて暗号化されたマニフェストをおくだけで展開できます。
そんな感じだわよ
監視
AWSとkubeの監視についてはDatadogに一任をしています。
datadog-agentはhelm templateでmanifestだけ持ってきてkubectlで適用しているだけです。
ダッシュボードですが、datadogはワンクリックでこんな凄いダッシュボードが出来上がります・・・はっきり言ってこれは神
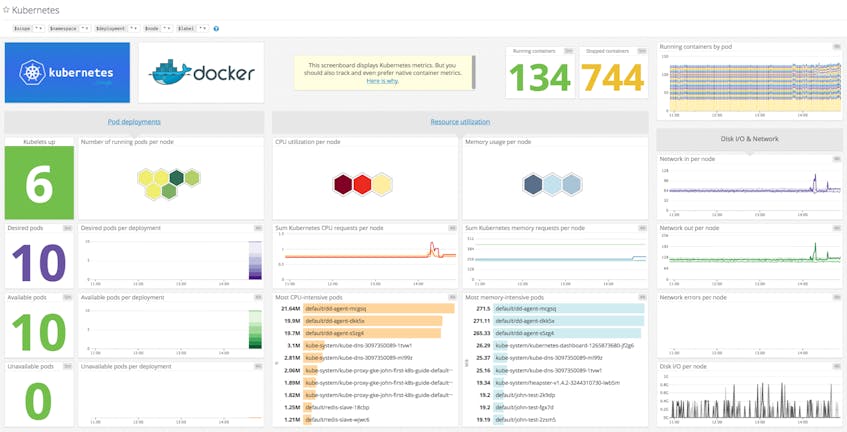
How to monitor Kubernetes + Docker with Datadog
感想
俺たちの旅はまだ始まったばかりだ!!@nnao45、ならびにAirtrackチームの次回作にryって感じで、とりあえずの初期状態は作れたかなと思っております。
プロダクトが大きくなる見込みも十分にあるので、もし大きくなりアーキテクチャを見直すことになったらまた記事を書きたいなと思っております!
Author