Blog
CVPR 2018 における参加報告と AI Lab からの発表について
はじめまして、AI Lab クリエイティブリサーチチームの大田です。 6月にコンピュータビジョンの国際会議 CVPR 2018 にチームで参加してきました。
この記事では今年の CVPR についての簡単な紹介と我々の発表内容についてご報告したいと思います。

CVPR 2018
CVPR はコンピュータビジョン分野において ICCV, ECCV と肩を並べるトップカンファレンスです。 昨年はハワイで開催されました。
開催地はアメリカ合衆国のユタ州ソルトレークシティ、会場はソルトパレスコンベンション・センターです。 ソルトレークシティはモルモン教徒が拓いた町として知られており、市街地には立派な聖堂が存在しています。 2002年の冬季オリンピックの開催地としても有名ですね。
会期中の現地の天気は概ね晴れており屋外の強い日差しと会場の冷房のギャップに悩まされつつも毎日ホテルと会場を往復していました。

今年は参加者数が約6,000人、投稿論文数3,000件以上と昨年同様過去最高を更新しています。
論文についてはさらにその中から979件が採択され、オーラル・スポットライト・ポスターのそれぞれの枠での発表となりました。
Best Paper Award は Taskonomy: Disentangling Task Transfer Learning [Zamir et al.] です。
コンピュータビジョンにおけるタスク間の転移学習の行いやすさについて分析し、グラフとして可視化。 関係の強いタスク同士は転移学習においてより少量の学習データで高い性能を出すことができ、学習の効率アップが期待できるとしています。
会場内はとても広く、目当ての発表を聴きに行くための部屋移動だけでかなりの時間がかかります。
特に巨大な展示ホールでは本会議ポスター発表や企業からの Expo ブースの出展が数多くされたのですが、それでもスペースが余ったのかソファやデスクなどの休憩所や卓球台まで。 議論の合間に軽く汗を流す参加者の姿が見受けられました。

さらに今年は会期とワールドカップの開催期間が重なっており、リアルタイム上映用の大スクリーンも設置。 試合中は大勢の参加者がスクリーンに釘付けになり、決定的瞬間の際には大歓声が会場内に響き渡ります。

そして本会議1日目の夜には会場からほど近い広場にて Social Event が開催。 料理やお酒を頂きつつパフォーマンスショーやバンド演奏がなされ、夜が更けるに連れてステージ前は曲に合わせて踊り出す方々で湧き上がりました。

研究紹介
CVPR 本会議にて発表された研究の中から我々が注目した発表を数件程度ピックアップしました。 簡単にコメントを添えて紹介いたします。
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo

論文より図1: StarGAN によるマルチドメインな Image-to-Image の結果例、入力画像に対し単一の Generator のみで複数のドメインへの画風転送に対応している
CycleGAN においての制約であった画像ドメインのペア制約を取り除きユニバーサルな Generator を配置したモデルを提案。 学習に ConditionalGAN の枠組みを取り入れることで、複数の Generator を学習することなくマルチドメインな Image-to-Image を実現しています。
CartoonGAN: Generative Adversarial Networks for Photo Cartoonization
Yang Chen, Yu-Kun Lai, Yong-Jin Liu
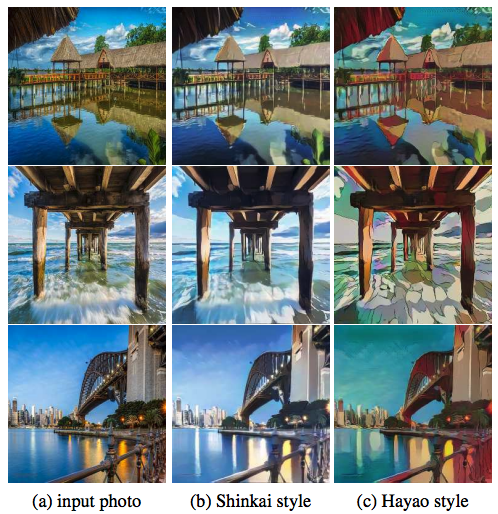 論文より図3: CartoonGAN によるアニメ調スタイル転送結果、多様なアニメスタイルに忠実な形で元の写真をアニメ調に変換できる
論文より図3: CartoonGAN によるアニメ調スタイル転送結果、多様なアニメスタイルに忠実な形で元の写真をアニメ調に変換できる
写真をアニメ調に変換する GAN の提案ですが、これまでの画風変換と異なるのはシンプルなテクスチャやくっきりとしたエッジなどアニメ調の画像が持つ特性をうまく再現するように損失関数を工夫していることが挙げられます。 実験においては「新海誠スタイル」や「宮崎駿スタイル」といった日本のアニメ映画作品に見られるような画風変換を行い結果画像を示しています。
ST-GAN: Spatial Transformer Generative Adversarial Networks for Image Compositing
Chen-Hsuan Lin, Ersin Yumer, Oliver Wang, Eli Shechtman, Simon Lucey

論文より図11(a): ST-GAN による顔写真とメガネの合成結果の生成過程、左の初期状態から反復的に推論し右のフィット状態へ至る
写真の中の顔に対しメガネを掛けさせるような画像合成を考えたとき、人間の眼の部分にフィットしていないと不自然なことは明らかです。 この論文では合成するオブジェクトの変形パラメータ+マスク画像を作成するモデルを学習することで、オブジェクトの変形を伴う画像の合成を行う GAN を提案しています。
Natural and Effective Obfuscation by Head Inpainting
Qianru Sun, Liqian Ma, Seong Joon Oh, Luc Van Gool, Bernt Schiele, Mario Fritz
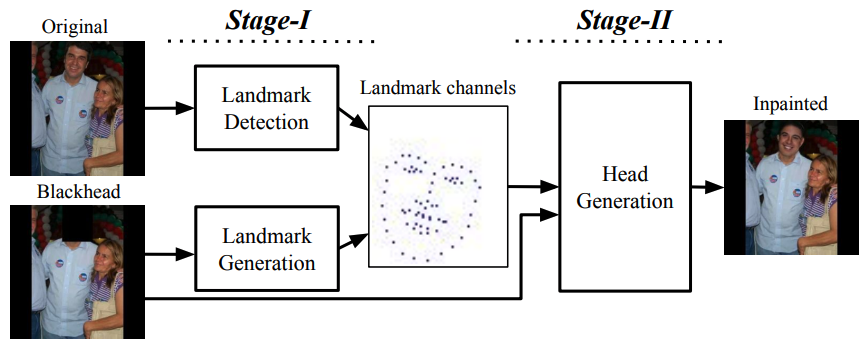
論文より図2: オリジナル顔画像あるいは黒塗り顔画像からランドマークを得る Stage-1 とそのランドマークと黒塗り画像を利用して擬似頭部を生成する Stage-2 というネットワークモデルを構築
ソーシャルサービスの拡がりに伴い、画像や動画におけるプライバシー保護がますます困難になっています。
画像内における顔部分を黒で塗りつぶすことは簡単ですが、隠蔽編集が施されていることがひと目で分かります。
この提案では代わりに写実的な擬似頭部を生成することにより、写真における自然な顔の挿げ替えを行っています。
Semi-parametric Image Synthesis
Xiaojuan Qi, Qifeng Chen, Jiaya Jia, Vladlen Koltun
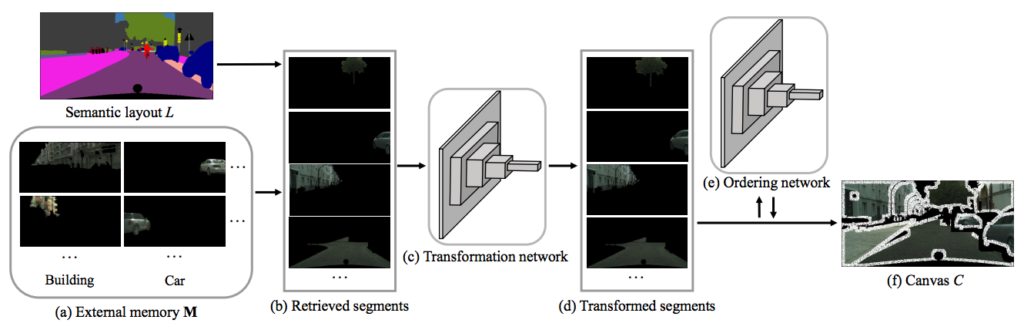
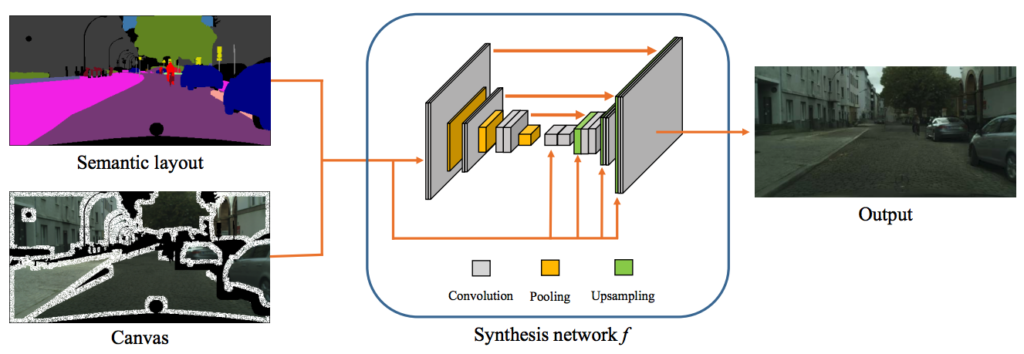
論文より図2,3: 最初に Semantic Layout と External Memory から Canvas を生成し、次のフェーズでさらに Semantic Layout と Canvas を利用して最終アウトプットを出力する2フェーズ構成
External memory と呼ばれるセグメント化済みの画像セットを合成することで、与えられた Semantic Layout から高精細な画像を生成する SIMS という手法を提案しています。
当日の口頭発表においては直前にも pix2pixHD という pix2pix の高精細化についての発表もなされましたが、こちらはよりリアルな結果を叩き出せていることを pix2pixHD と比較して主張しており会場が沸いていました。
AI Lab からの発表
それでは CVPR 2018 における我々の発表内容について紹介します。 今年の CVPR は本会議が3日間、チュートリアル・ワークショップが2日間ありました。 先日 PR ブログでも紹介されましたが、我々からは本会議にて1件の発表を行い、さらに2つのワークショップに参加しています。
本会議
本会議においては山口による以下の論文が採択されており、共著者と共にポスター発表を行いました。
Feedback-prop: Convolutional Neural Network Inference under Partial Evidence [Wang et al.]
複数のタスクを同時に推論するような DNN モデルにおいて部分的な正解ラベルが与えられた際に残りの未知ラベルの推定精度を向上させる汎用的な手法の提案を行っています。当日のポスターボード前には大勢の人だかりができ、盛んな議論が行われました。

Towards Automatic Understanding of Visual Advertisements ワークショップ
参加ワークショップ1つ目は広告画像理解のためのワークショップ。 与えられた広告画像に対し正しい説明文を選択するコンペが開催されました。
Towards Automatic Understanding of Visual Advertisements (ADS)
広告画像の自動生成・制作支援について研究している我々クリエイティブリサーチチームとしてはぜひ参加したいということで話が決まり、山口・大谷・岩崎の3名がコンペに向けてスコアの向上に努めてまいりました。
そして何と1位を獲得、大谷がワークショップ冒頭にて “Unreasonable Effectiveness of OCR in Visual Advertisement Understanding” というタイトルで Winner Talk を行いました。

コンペ内容や技術的詳細については下記のブログ記事をご参照ください。
[CVPR Workshop] Automatic Understanding of Visual Advertisementsコンペティション解説
また、このワークショップでは上記コンペに加えて広告画像にまつわるアブストラクト論文の募集も行われました。 こちらについては私大田より “Emotional Style Transfer for Stock Assets” というタイトルの論文を投稿し発表。 BAM データセット [Wilber 17] の感情スコア値に着目し、人々の画像に対して抱いた感情に基づく画像変換手法を CycleGAN [Zhu 17] を利用して提案しています。

Language and Vision ワークショップ
参加ワークショップ2つ目は言語と画像についてのワークショップ。こちらでは大谷が大阪大学にて学生時代より進めていた研究について “Visually Grounded Paraphrase Extraction via Phrase Grounding” というタイトルで発表しました。 画像において2つのフレーズが同じオブジェクトに関する言い換え表現かどうかを判定する提案を行っています。
おわりに
やはり今年も DeepLearning 祭りなのはもはや当然のことながら、昨年と比べるとグラフ情報に着目した提案が目立っていたように思います。個人的には GAN に関する発表が一度に沢山聞けたのも良い経験となりました。ちなみにオーラル・スポットライト発表の録画はこちらの YouTube チャンネルにて随時アップされておりますので気になった方は発表を聴いてみてはいかがでしょうか。
来年の CVPR 2019 はアメリカ合衆国ロサンゼルス・ロングビーチにて開催されます。機械学習のトップカンファレンス ICML と開催地・日程が重複しているということもあり、参加人数もさらに多くなることが予想されます。
私が CVPR に参加するのは昨年に続き2度目となります。 昨年は聴講だけでしたが、今回はワークショップとはいえ発表も兼ねました。 現地での自身の研究に関するフィードバックはやはり新鮮でより様々な意見が得られますし、今後も何らかの投稿をもって国際会議に参加していければと思っています。 引き続き我々 AI Lab では広告とコンピュータビジョンに関する研究を進め、権威ある国際会議への論文投稿も積極的に狙っていきます。

Author