Blog
【採択論文紹介】初期化画像による生成コンテンツの編集(ACMMM2023)
AI Lab Media Fundamentalsの汪とインターンのMaoです。我々のチームでは広告クリエイティブの制作支援に関する研究開発に取り組んでおり、その中でも特に拡散モデルによるテキストとレイアウトからの画像生成の研究に取り組んでいます。
拡散モデルはテキストを条件に、初期ノイズを変換することで画像を生成します。この記事ではACMMM2023に採択された、拡散モデルの初期ノイズを操作する手法について紹介します。
Guided Image Synthesis via Initial Image Editing in Diffusion Model
Jiafeng Mao, Xueting Wang, Kiyoharu Aizawa
はじめに
本論文では、生成に失敗する要因について調査し、生成されたコンテンツを制御する新たな方向性を提案しました。現在一般的に使用されているサンプリング手法であるDDIM[1]とPLMS[2]は決定的です。拡散モデル 𝜃、プロンプト 𝑝、初期ノイズ画像\(x_T\)が与えられた場合、生成される画像\(x_0\)は一定であり、\(x_0=f_𝜃(p, x_T)\)と表現されます。プロンプトとモデルパラメータが同じであれば、最終的な生成画像はランダムにサンプリングされた初期画像によって確定されるはずです。初期ノイズ画像は生成プロセスにおいて極めて重要な役割を果たす一方で、これまでほとんど注目されていませんでした。そこで、本研究では初期ノイズが生成結果に及ぼす影響について詳細に分析しました。
本論文では、生成傾向の性質と編集に関する実験を実施し、生成傾向の形成の理論的な側面も考察しました。実験の結果と分析から、生成画像の一部の再生成による修正と、レイアウトに基づく画像生成という二つの応用についても提案しました。

図1:初期ノイズに基づく生成傾向の制約応用の例
初期化画像の生成傾向
まず、初期化画像自体がどれだけ情報を保持しているかを調査する実験を実施しました。具体的には、ランダムな初期化画像と一定のモデルパラメータを用い、プロンプトを変更しながら画像生成を行い、その結果を観察しました(図2の上段)。次に、初期化画像を別のランダムな初期化画像に変え、同じプロンプトで再び生成を行い、生成された結果を観察しました(図2の下段)。
ここでのプロンプトは、a (bus) and a (cat) のような簡単な文で、括弧内の単語は画像下の赤と青の単語です。

図2:生成傾向の検証する実験の結果
図2の結果から、次のような結論を導くことができます。
- 同じ行の画像を比較すると、初期化画像が固定された後、異なるプロンプトを使用しても、背景やオブジェクトの位置、画像全体のトーンなど、生成されるコンテンツに顕著な共通点が見られます。
- 同じ列の画像を比較すると、異なる初期化画像を用いると、同じプロンプトを使用していても、生成されるコンテンツが背景やオブジェクトの視覚的な表現、オブジェクトの位置などにおいて大きく異なることが分かります。
これは、初期化画像そのものが最終的な生成結果に対して決定的な影響を及ぼすことを示唆しています。初期化画像が決定されると、特定のコンテンツが特定の位置に生成されやすくなる傾向があることを示唆しています。
初期化画像の編集で生成結果の修正
上記の実験結果から、なぜ画像生成が成功する場合と失敗する場合があるのかの一つの可能性を解析できます。初期画像の生成傾向がプロンプトの内容と一致する場合、生成が成功しやすくなります。つまり、初期画像が生成される際に既に望ましいコンテンツの特徴と近いため、それに基づいて生成が進行しやすくなると考えられます。逆に、初期画像の生成傾向がプロンプトの内容と合致しない場合、生成が失敗しやすくなります。初期画像とプロンプトの一致度が生成の成功率に影響を与えることが、この実験によって示されています。
初期画像は生成に非常に重要ですが、それを編集する可能性について実験で検証しました。画像生成が失敗する原因の一つは、先述の分析によると、望ましい内容と初期画像の生成傾向が一致しないためです。そこで、この衝突を解消し、生成が成功するかどうかを確認します。衝突を解消する方法も非常にシンプルです。具体的には、どの部分で衝突が発生しているかを特定し、その部分を再サンプリングします。たとえば、図3の場合、プロンプトの指示に従って、猫が椅子の上に生成されることが期待されていましたが、結果的には画像右下に生成されてしまいました。先述の分析によると、これは初期画像の椅子の領域(領域 B)の猫を生成する傾向が低く、一方で右隅の領域(領域 A)で猫を生成する傾向が高いためです。実験では、初期画像のこれらの領域を再サンプリングし、他の領域のピクセル値を変更せずに再生成しました。4〜5回の試行の結果、最終的には右側の画像の生成に成功しました。
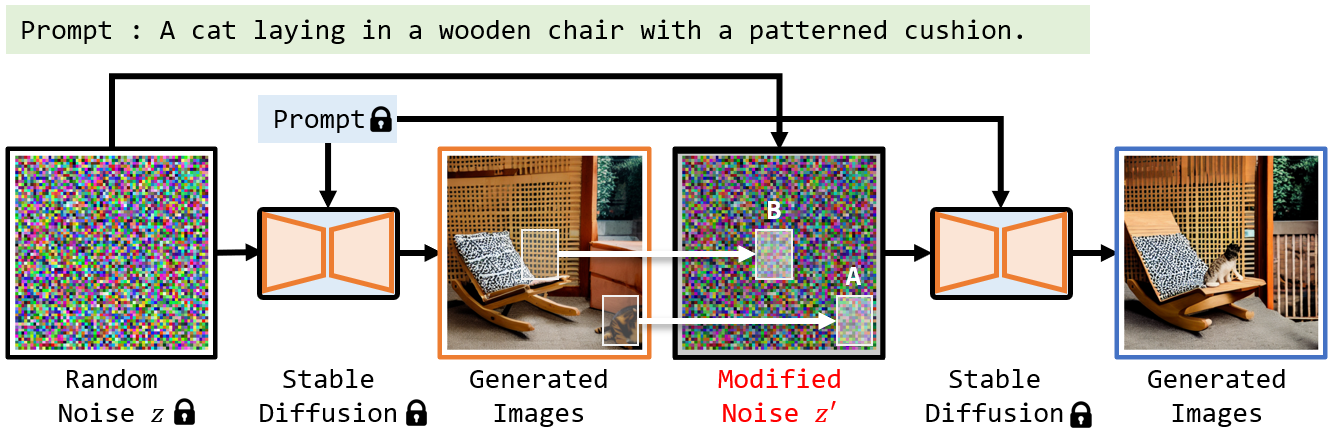
図3:初期化画像の編集で生成結果を修正する実験
この実験によって、初期画像は非常に重要であり、単純に2つの小さな領域を再サンプリングするだけで、失敗した生成を修正できることが確認できました。これにより、初期化された画像の生成傾向とプロンプトの内容との間に調和をもたせることが、生成を制御するカギとなることが示唆されています。そして、このような生成の傾向は局所的なものです。初期化画像が再サンプリングされた領域では、生成結果に大きな変化が見られます。一方で、他の領域では基本的に生成結果は一貫しており、大きな変化は生じていません。このことは、生成のプロセスが局所的な特性を持ち、必要な部分だけを調整することが可能であることを意味しています。この特性を利用して、生成された画像の調整に応用できます。

図4:生成された画像を修正するタスク
図4の例のように、ユーザーが生成画像の一部に不満がある場合、同じ初期化画像を用いて、修正したい箇所を再サンプリングし、再生成することで、その部分を改善することが可能です。
生成傾向に関する分析
画像生成プロセスは、ランダムな出発点(初期画像)を徐々に潜在空間での実際の画像分布に近づけていると解釈できます。テキストからの画像生成で用いられる拡散モデルでは、ノイズを取り除き、Cross-attention Layerを用いて初期画像の各ピクセルとプロンプトに含まれる各オブジェクトとの類似度を表すAttention Mapを計算します。簡単に言えば、Cross-attention Layerは、query Q(入力画像の埋め込み)とkey K(プロンプト中の各単語の埋め込み)の間の類似度を計算します。ある単語に対するAttention Mapの値は、入力画像の対応する領域の特徴と単語の特徴との類似性を示しています。Value Vは各単語のセマンティックな特徴を含んでいます。Attention Mapに従って、Cross-attention Layerは、単語と既に十分に類似している領域に、その単語の特徴を繰り返し追加します。その結果、特定の単語に関連するコンテンツの生成は、最終的にそのAttention Mapの信号が強い場所で発生します。このメカニズムが初期画像の生成傾向を形成しています。Cross-attention Mapは初期化画像の各領域の生成傾向を示すことができます。 このようなCross-attention mapの性質を使って、特定のオブジェクトを生成しやすい領域をユーザーが指定する領域に移動することで生成結果を制御する実験を実施しました。

図5:ピクセルブロックを移動する実験
図5の例では、ユーザーがオレンジと青い枠で羊と車の位置を指定しています。羊を生成する傾向を持つ初期画像のピクセルブロックを、左側のオレンジ色の枠内に移動し、一方で車を生成する傾向のピクセルブロックを右側の青色の枠内に移動させました。その結果、羊をオレンジの枠内に、車は青色の枠内に生成することができました。
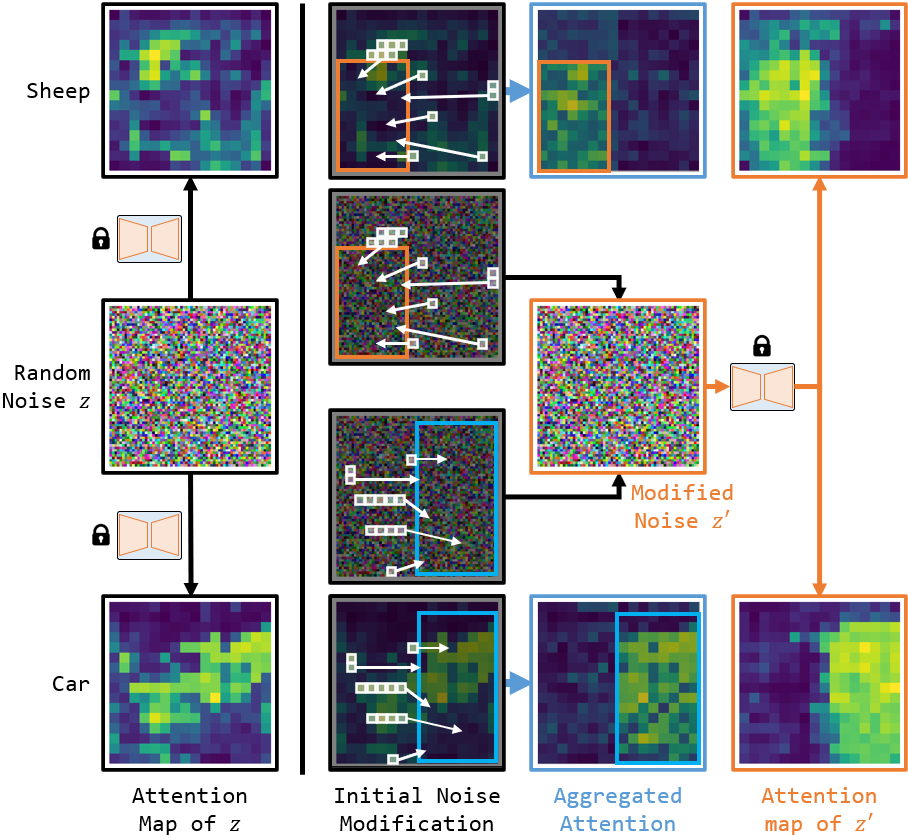
図6:編集したAttention Mapと編集した初期画像で再計算したAttention Map
図6では、編集したAttention Mapと、編集した初期画像で再計算されたAttention Mapを表示しています。羊を生成する傾向のピクセルブロックが左側の領域に収束することで、左側の領域は強い羊の生成傾向を示すように変化します。この手法は、レイアウトからの画像生成タスクに適用できます。我々の手法は既存手法[3,4]と同じ程度のコントロール有効性ができ、既存手法と組み合わせて使う場合、既存手法の有効性をさらに向上できます。図7は生成の例を示しています。

図7:レイアウトからの画像生成の例
おわりに
この研究では、初期化画像の特性を探求し、その特性を新たな制御メカニズムとして活用することを試みました。この手法により、生成された画像の修正や、レイアウトからの画像生成を実現しました。
参考文献
[1] Song et al., “Denoising Diffusion Implicit Models”, In ICLR, 2021
[2] Liu et al., “Pseudo Numerical Methods for Diffusion Models on Manifolds”, In ICLR, 2022
[3] Mao et al., “Training-Free Location-Aware Text-to-Image Synthesis”, In ICIP, 2023
[4] Balaji et al., “eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers”, In arXiv, 2022
Author