Blog
【採択論文紹介】公共空間における対話ロボットのオンライン音声方策最適化 (HRI 2026)
AI Labの宋です。Interactive AgentグループはHuman-Agent Interaction、Human-Computer Interactionを中心に研究・開発を行っています。今回は、 Human-Robot Interaction分野の主要な国際会議であるHRI2026に採択された、公共空間における対話ロボットのオンライン音声方策最適化と報酬設計の比較についての論文について紹介します。
著者:Sichao Song, Yuki Okafuji, Kaito Ariu, Amy Koike
はじめに
対話ロボットを公共空間に設置すると、ロボットとインタラクションを行う利用者の年齢等の属性や、 対話目的は多種多様となります。こうした多様な環境に対して、オンライン学習(多腕バンディットなど)でロボットの振る舞いを現場適応させる試みは増えています。一方で現場導入で必ずぶつかるのが、「何を成功(reward)とみなして学習させるか」という設計です。満足度を上げたいのか、会話をきれいに終えたいのか、会話を続けてエンゲージメントを取りたいのか。どれも良さそうですが、実は報酬の置き方が変わると、学習される最適な話し方も変わってしまいます。本研究はこの点を、12日間・1,400件超の実地運用で比較検証しました。
研究背景
Thompson Sampling(TS)をはじめとする多腕バンディット(Multi-Armed Bandit; MAB)は、探索と活用のバランスを取りながら限られた試行で累積報酬を最大化でき、公共空間のように属性が多様な環境と相性が良いとされています。ただしMABは、最終的に「観測できる報酬」しか最適化できません。主観評価(ユーザアンケート)のように分かりやすい指標もあれば、会話の終わり方や継続といった行動指標もあります。それぞれが指す良い対話は異なるため、報酬の選び方がそのままロボットの人格・運用方針を規定します。本研究は、同一環境・同一行動空間・同一学習アルゴリズムのまま、報酬定義だけを切り替えて比較しました。
研究方法
本研究では、対話ロボットの話し方を2軸で離散化し、計6つのアーム(行動)から選ぶ問題として定式化します。
・話速:Slow(遅い) / Normal(普通) / Fast(速い)
・冗長さ:Concise(簡潔)/ Detailed(詳細)
6アームは SC(Slow-Concise)、SD(Slow-Detailed)、NC(Normal-Concise)、ND(Normal-Detailed)、FC(Fast-Concise)、FD(Fast-Detailed)です。
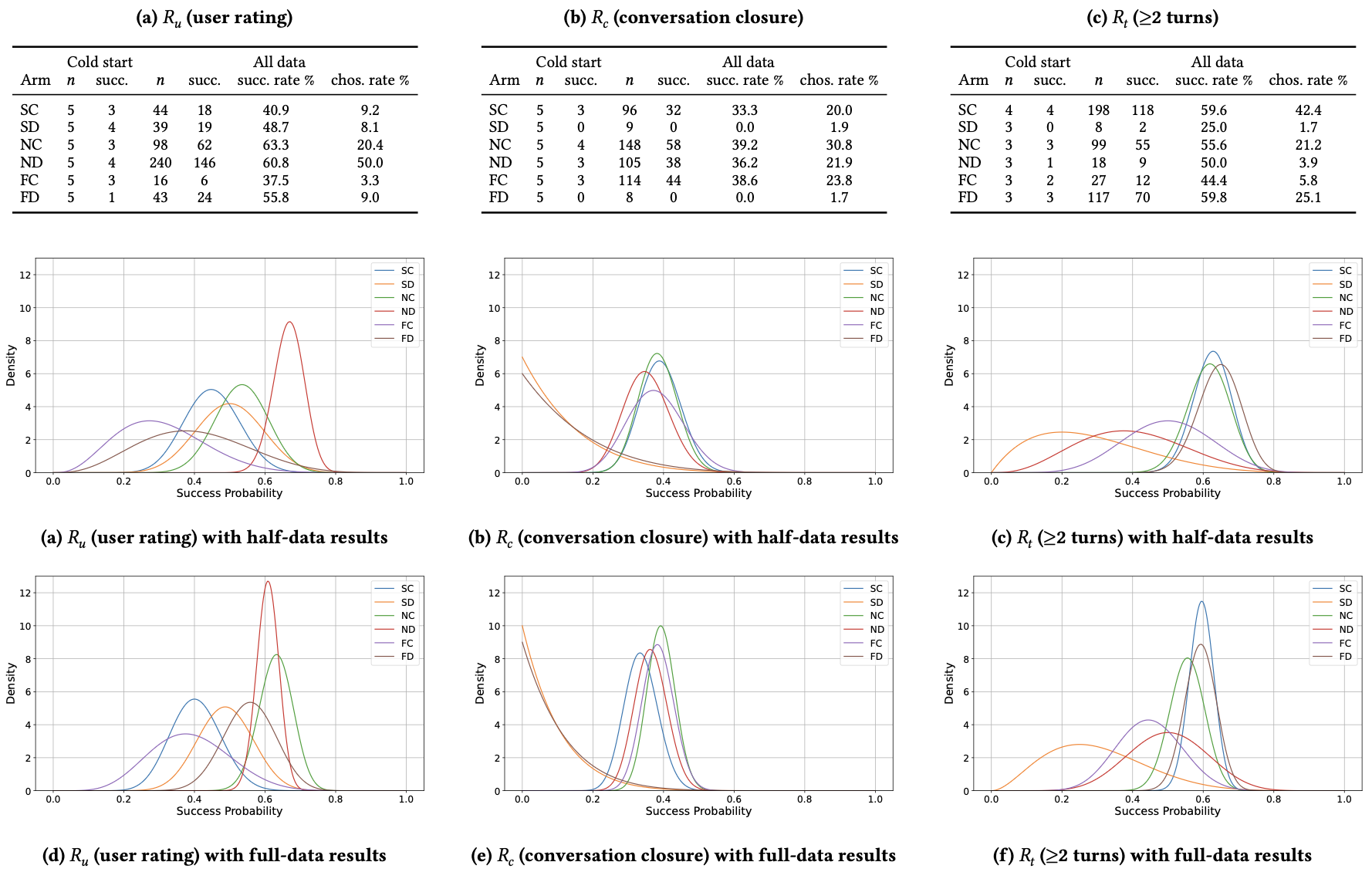
学習アルゴリズムはベルヌーイ報酬×Beta事前分布のThompson Samplingを採用し、各対話の終了後に報酬を受け取って事後分布を更新します。初期偏りを避けるため、各条件で30件のコールドスタート(各アーム5回ずつ)を行った上で、450件の学習フェーズへ移行しました。
実験
実験は商業施設にサービスロボットを設置し、12日間運用して実施しました。総インタラクションは1,400件超です。

比較した報酬条件は、運用上の目的が異なる3種類の二値報酬です。
(1)Ru(利用者評価):対話後アンケート(7段階)で6以上を成功
(2)Rc(会話の締め):ありがとう/さようなら等の明示的なクロージングに到達したら成功
(3)Rt(≥2ターン):2ターン以上(ロボット1→ユーザー1→ロボット2→ユーザー2)が成立したら成功
Ruは満足度、Rcは効率的な完結、Rtは対話継続意欲をそれぞれ反映しています。
各報酬条件では、ユーザがインタラクションを行うごとにリアルタイムに報酬を与えました。Ru条件の場合は、インタラクションごとに利用者にアンケートを取って、アンケート評価を収集しました。RcとRt条件の場合では、裏にいる観測者が対話内容を観測しており、インタラクションが終わるタイミングで報酬評価を行いました。報酬のための評価が得られたタイミングで学習が回るようなシステムを組むことで、インタラクションごとに学習を回していく設計としました。

結果
結論から言うと、同じアーム集合でも、報酬定義が違うだけでTSが好むアームは明確に変わりました。満足度(Ru)では、選択率が最も高かったのはND(50.0%)で、成功率が最も高かったのはNC(63.3%)でした。学習の前半ではNDが強く選ばれ、後半でNCが伸びていくという学習途中での逆転も観察されています。会話完結(Rc)では、NCが選択率30.8%、成功率39.2%と最も良く、SC/ND/FCも近い水準で推移しました。一方でSDとFDは全期間で成功率0%となり、完結指標とは相性が悪いことが示唆されます。会話継続(Rt)では、選択率が最も高かったのはSC(42.4%)、成功率が最も高かったのはFD(59.8%)でした。ゆっくり簡潔と速く詳細という、異なるスタイルがそれぞれ継続に寄与する可能性が示されました。
考察
本研究では、全インタラクションを動画記録し、混雑、単独/グループ、案内要求、動機をアノテーションした上で、GLM(一般化線形モデル)でアーム×文脈の相互作用を分析しています。たとえばRuでは、単独ユーザはグループより高評価を得にくい一方で、単独場面ではNDが相対的に有利になる傾向が示されました。また教育目的の来訪者ではNC/ND/FDが高評価になりやすいなど、目的によって良い話し方が変わる可能性が示唆されています。Rtでは、混雑時にNDやFCが不利になるなど、同じ継続指標でも周辺状況で成否が変わる兆候が見られます。
本研究のメッセージは明快です。オンライン学習において「何を報酬とするか」は、最終的にロボットがどんな会話を学ぶかを決めます。満足度を取りたいならRuに寄せた設計が必要ですし、回転率や案内効率を重視するならRcが合います。会話を続けたいならRtが使えますが、その結果として生まれる話し方は、満足度最適化とは一致しないかもしれません。また、文脈によって最適アームが変わる以上、将来的には文脈付きバンディットのように「状況を見て話し方を切り替える」枠組みへ進むのが自然です。実運用におけるセンサー設計・ログ設計・公平性や社会的許容性なども含め、報酬と文脈を一体で設計することが重要になります。
おわりに
実フィールドでの対話型のロボットの設計に課題を感じていたり、実証実験や導入を検討しているような企業・研究者の皆さまは、ぜひ現地で議論の機会をいただければ幸いです。
また、我々のチームでは一緒に Human-Robot Interaction / Human-Computer Interaction の研究・開発を行っていただける研究者・エンジニア・博士インターン生を募集しています。本ブログを見てご興味を持っていただけた方はぜひ一度カジュアルにお話させてください。よろしくお願いします。
Author