Blog
Coling 2016参加レポート – その1
こんにちは。AI Labの山本です。
今月の11日から16日まで大阪府立国際会議場で開催された国際会議Coling2016についてレポートを4回に分けてお送りします。
Colingは計算言語学(Computational Linguistics)についての国際会議で今回でなんと26回目です。
計算言語学というと、自然言語を計算機の視点でルールもしくは統計的にモデル化するものですので、自然言語処理と比較すると理論よりだったりします。
ただ、現在のColingは計算言語学に加えて自然言語処理の話題も扱っていますので、理論も応用も知ることができる一粒で二度美味しい![]() 国際会議となっています。
国際会議となっています。
今回は1日目に開催されたワークショップについて紹介していきます。
この日は私とチームメンバーの田中が参加していて、質問応答のワークショップOKBQA2016とノイズを含むテキストについてのワークショプWNUTをそれぞれ見に行っていました。
Open Knowledge Base and Question Answering Workshop (OKBQA2016)
概要
知識抽出と質問応答のためのオープンなフレームワークを共同で作っていくことに主眼を置いたワークショップでした。
Keynote1: Reading and Reasoning with Vector Representations
UCL (University College London)のMachine Readingグループでは構造化されていないテキストを読み取り、質問応答するエージェントを作ろうとしているそうです。
このようなエージェントを作るアプローチとしては、データソースや質問を論理式に変換してパターンマッチで解く方法が昔から行われていますが、データの確保やノイズのあるデータにどのように対処するかが問題となっています。
一方、Machine Readingグループでは別のアプローチである埋め込み(embedding)表現から推論する方法を研究しているそうです。
埋め込みからの推論というと、ベクトル空間モデルと同様、対称性のある実体(entity)の関係しか表すことができないのではと思っていたのですが、非対称性を表現する工夫もあるとのことでした(pdf)。
ちなみに、なぜそのように推論したのかという理由付けについての研究は進行中とのことでした。
まだまだこの分野は面白い発表が出てくるだろうなと感じたキーノートでした。
Featured Talk: OKBQA
この発表で初めて知ったのですが、OKBQAという質問応答のフレームワークがあるそうです。
ちなみにOKBQAは、Open KB (Knowledge Base) and QA (Question Answering)の略です。
発表の中でフレームワークの特徴が紹介されていましたが、特にシステムの作りが面白いなと思いました。
下の図はOKBQAのドキュメントからの引用です。
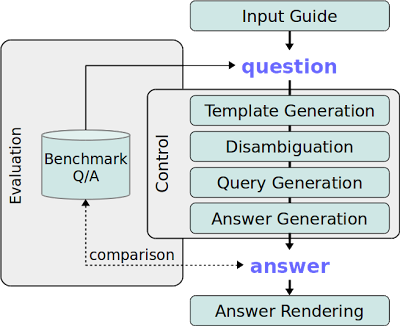
Control内の箱がQAシステムを構成する要素なのですが、それぞれがRESTサービスになっています。
このようにすることで、各モジュールを独立に開発することができたり、入れ替えを容易にできるようしているとのことです。
もう1つOKBQAで重要なところは、質問応答システムをオープンに共同開発しやすくしているところです。
例えば、先ほど説明したOKBQAのモジュールはオープンソースになっています。
また、OKBQAハッカソンに参加することで開発に関わることができるようです。
Keynote2: Challenge in QA for University Entrance Exam at NTCIR QA-Lab
情報アクセス技術の評価型ワークショップにNTCIRというのがありますが、そのQA-Labタスクの紹介でした。
実はこのタスクを初めて知ったのですが、世界史の試験問題を使って質問応答する(解答するというほうが適切かも)というものです。
ちなみに、世界史の試験問題というのは、センター試験(多岐選択式問題)と二次試験(多岐選択式問題及び記述式問題)です。
QA Labはこれまでに2回行われていて、3回目が現在進行中なのですが、回ごとにタスクや提供しているデータセットについて工夫がなされているようです。
例えばQA Lab 2では、訓練データを増やしたり、1つの論述問題につき3つの模範解答を作ったりしているようです。
また、QA Lab 3では論述問題タスクの参加者を増やすために、抜粋と要約のサブタスクに細分化したものを新設しているようです。
面白かった発表
Large-Scale Acquisition of Commonsense Knowledge via a Quiz Game on a Dialogue System (pdf)
ボットと人間で連想ゲームをやることで、人間が持つ常識(コモンセンス知識)を収集すると内容です。
ちょっとわかりにくいと思いますので下の図で説明していきます(図はPaperからの引用)。

ボット(Voice Assist)が、当ててほしい単語についてヒントを出していきます。
人間がヒントに基づいて単語を答えていくわけですが、ボットが意図しているものと違うものを答えることがあります。
そのような回答はこのゲームでは不正解なのですが、ボットが提示したヒントを制約として人間が導き出した単語であるのでファクトとしては正しいものになりそうです。
例えば上の図では、ボットが「スーパーマーケットにあるもの」「牛乳を材料にして作られている」 というヒントを提示して、人間が「チーズ」と答えていますが、このやり取りによって、「チーズはスーパーマーケットにある」ことと「チーズは牛乳を材料にして作られている」という2つのファクトを獲得することができます。
こんな感じでコモンセンス知識を収集することができるわけです。
余談ですがボットが意図していた答えは「ケーキ」だそうです![]()
さて、この研究では先に示した連想ゲームからの知識獲得をYahoo!音声アシストで実現しようとしているのですが、以下の2つの問題があったようです。
1つ目は、音声アシストでは人間が音声を通して単語を入力するので、音声認識誤りを含んでしまうことです。
例えば「チーズ」といったのに「地図」と変換されてしまうという問題です。
もう1つは、ヒントに矛盾する単語を答えてしまうことです。
例えば「草食動物」「黄色」というヒントに対して、後ろのヒントに引きづられて「トラ」と答えてしまうという問題です。
提案手法では、編集距離、キーワード間の類似度、答えた単語と提示したヒントとの距離などを使って信頼度を付けることでこの問題を解決しています。
そして、発表時点で9万人のプレーヤから19万を超えるファクトを取得することができたとのことでした。
2016 The 2nd Workshop on Noisy User-generated Text (W-NUT)
概要
AI Lab新卒の田中です。
初日は2016 The 2nd Workshop on Noisy User-generated Text (W-NUT)の発表を聞いていました。
このWorkshopではTwitterなどのSNSで発信されるノイズの混ざったデータを対象にした研究に関する発表をメインに扱っています。
また、今回はTwitterを用いて位置情報の予測や固有表現の抽出を行うshared taskも開催されました。
ユーザ個人の発言を上手く解析することができれば、それぞれのユーザのニーズなどをより良く推定することができ、適切な広告ターゲティングなどを実現できるようになります。
そのため、多くの雑音を含んだデータを解析することは非常に有用であると考えられます。
面白かった発表
CSIRO Data61 at the WNUT Geo Shared Task (pdf)
概要
ユーザの位置情報推定に関するShared Taskで一番をとったチーム(Data61)の発表です。
このshared taskでは、Twitterのデータを元に、市町村レベルでの位置分類精度を競います。
このshared taskでは以下の2つの位置分類タスクでそれぞれ評価を行います。
1. Twitterのユーザ単位での位置分類
- 学習データ : 100万ユーザデータ
- 開発/テストデータ : 10,000ユーザデータ
1ユーザにつき1つの正解位置ラベルが付与されている
2. Tweet単位で位置分類
- 学習データ : 100万ユーザデータ
- 開発/テストデータ : 10,000tweet
1tweetにつき1つの正解位置ラベルが付与されている
評価は以下の3つの項目で行います。
1. ACCURACY
- 位置分類の精度(正解率)
2. MEDIAN
- 正解位置と予測された位置との距離の中間値(単位:km)
3. MEAN
- 正解位置と予測された位置との距離の平均値(単位:km)
このshared taskのデータは参加者以外でも入手することができるので、挑戦してみたい方はダウンロードしてやってみましょう。
http://noisy-text.github.io/2016/geo-shared-task.html
さて、このチームではユーザ単位での位置分類で、MEDIANが30km以内になったと発表しています。
アプローチ方法としては、
1. Metadata Methods
2. Label Propagation Approaches
3. Information Retrieval Approaches
4. Text Classification Approach
の4つの観点からアンサンブル的に位置情報を分類する方法を取ったそうです。
特にMetadata Methodsはかなり効いたと言っていました。
位置情報推定のためのアプローチ
- Metadata Methods
tweetのテキストやプロフィールに含まれる地名など、tweetのメタデータから得られる情報を元に5つの観点で地名分類ラベルの候補に含めています - Label Propagation Approaches
tweetのリプライをもとにネットワークを構築し、label propagationで位置情報を推定しています
このアプローチだけユーザ単位での位置情報を推定するものです - Information Retrieval Approaches
似たようなtweetから各地名のラベルが付与される確率を算出します - Text Classification Approach
tweetのテキストを元にtimezoneを分類します
アンサンブル方法
上述したアプローチをいくつかの方法で組み合わせて位置情報の分類を行います。
Tweet単位での位置分類
以下の3種類のアンサンブル方法で評価を行っています。
1. Full Cascade(csiro.1.tweet)
- validationデータを用いて、それぞれのアプローチにおいて位置分類に対するaccuracyが高い順に位置情報を決定
- 最もaccuracyが高いアプローチはMetadata LBS Links(facebookやinstagramなどの位置情報を用いたサービスから位置情報を分類するアプローチ)でした。
- 確かにこれはかなり正確に位置情報を取れそうに思えます。しかしLBS(Location Based Service) Linkが含まれるtweetはかなり少ないと思うので、他のアプローチの出力が必要になる場合も多いだろうなと感じました。
2. Heuristic Cascade(csiro.2.tweet)
- tweetのメタデータとlabel propagation(メタデータから得られる位置情報のみからpropagationを行う)によるアプローチのみを含めた方法
- Full Cascade同様にaccuracyの高いアプローチから順に位置情報を決定
3. Voting Variant(csiro.3.tweet)
- precisionの高いアプローチで位置情報を分類できる場合はその結果を使用
- 分類できない場合はその他のアプローチによる出力で最も多く分類された位置情報を使用
User単位での位置分類
1. Full Cascade(csiro.1.user)
2. Voting Variant(csiro.3.user)
3. Ablation Variant(csiro.2.user)
- Full CascadeからTime zone Text Classifierのアプローチを除いたアンサンブル方法
まとめ
各チームの結果は以下となりました。
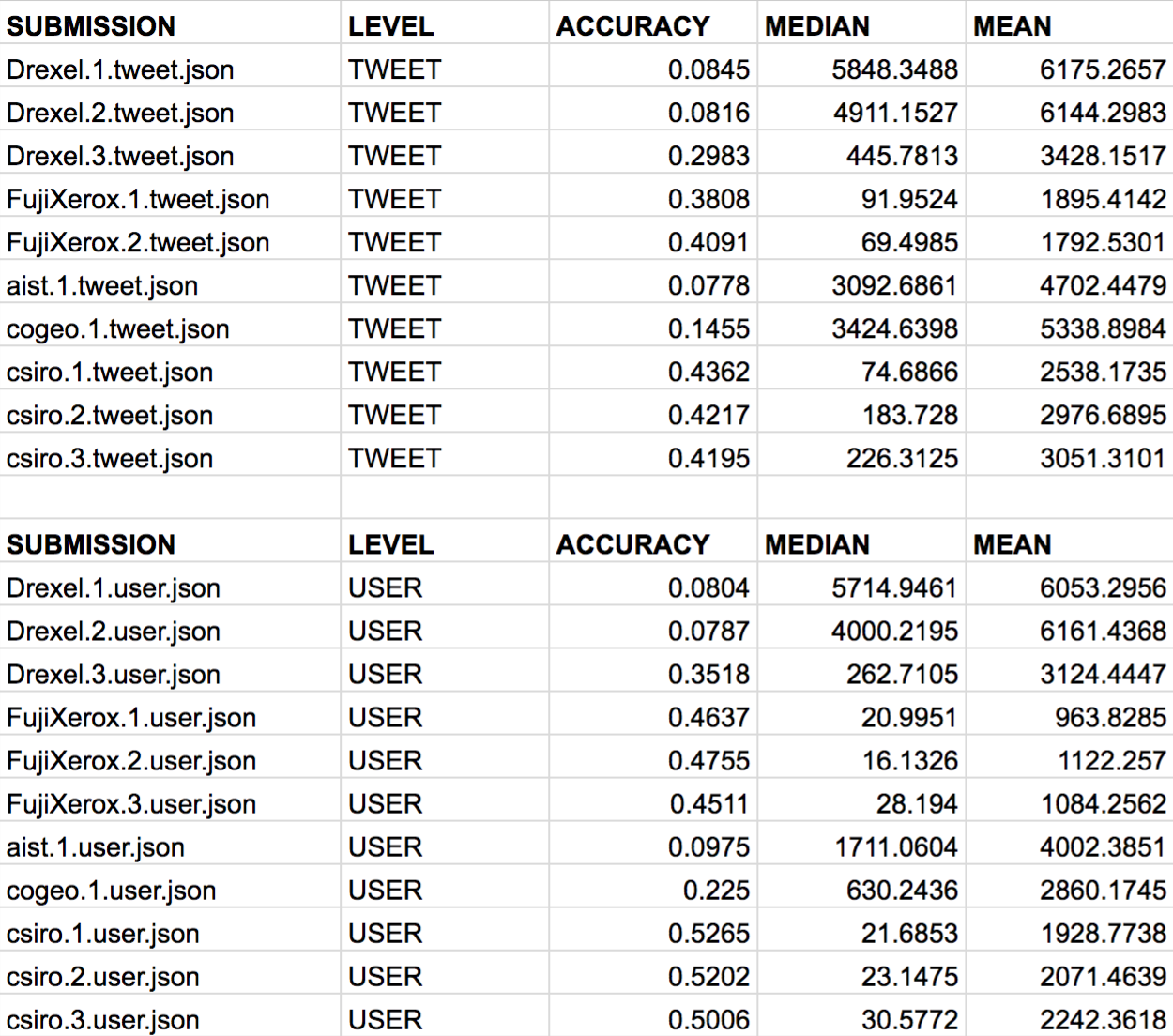
ACCURACYは位置情報の分類精度なので高いほど良く、MEDIAN, MEANは正解の位置と予測された位置との誤差なので小さいほど精度が良いといえます。
ACCURACYの観点では、Full Cascade(csiro1)が他のチームの手法と比較し最も高いスコアを出しており、提案した全てのモデルがTop-3以内に入っています。
MEDIANでは、Tweet毎の位置分類において、Full Cascadeが2番目に良い結果となっています。
このチームが提案した、自然言語処理的なアプローチ(the time zone text classifierとthe information retrieval approach)は、このタスクではaccuracyを高くする重要な要因にはならなかったと報告しています。
(Full Cascade と Heuristic Cascadeを比較した際、後者はtime zone text classifierとinformation retrieval approachが除かれているが、大きく精度が減少することはなかったため。)
ただ、Full Cascade と Heuristic Cascadeにおいて、median error distance はHeuristic Cascadeの方が増加しているため、time zone text classifierは位置分類の平均予測誤差を減らすのには効果があるようです。
今後は何かしらのイベントに言及するtweet(e.g. 「浜松で不発弾処理してるらしいよ」)など、ユーザのいる位置と言及している位置が異なる場合などでの分類精度を改善するために、自然言語処理的なアプローチを取っていきたい と締めくくっています。
Author