Blog
Kaggleゼミ成果報告(Rossmann編)
こんにちは、基盤開発グループの平坂です。
前回に引き続き、今回は Kaggle ゼミで挑戦したコンペの1つ「Rossmann Store Sales 」での取り組みを紹介します。
前回で既に結果を報告している通り、このコンペでは全体で参加 3303 人・チームのうち 24 位という好成績が残せました!以下の図は LeaderBoard というコンペのランキングの最終結果からの抜粋です。
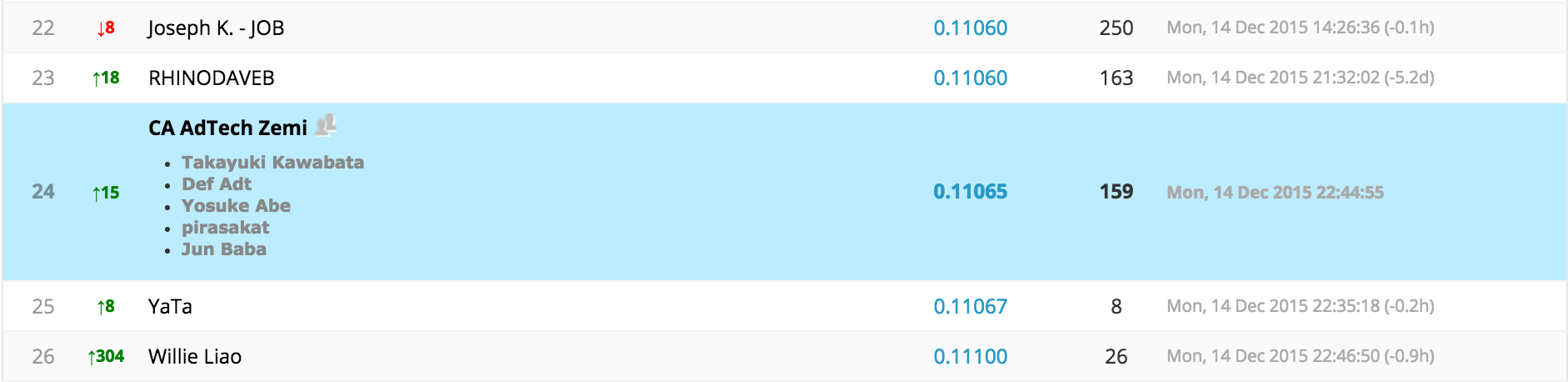
惜しくも Kaggle Master になる条件の1つである Top 10 入りは叶いませんでしたが、Kaggle でのノウハウをいろいろと得ることができましたので報告したいと思います。
Rossmann Store Sales コンペとは?
![]()
まず Rossmann Store Sales コンペ自体について説明します。Rossmann とはドイツを中心に展開している大手のドラックストアチェーンで、日本でいうとマツキヨみたいな企業のようです。
このコンペでは Rossmann から 1115 店舗分の店舗データと、これらの店舗の 2013年1月1日 〜 2015年7月31日までの日別売上データが予測モデルの学習用のデータとして与えられました。そして、これらのデータを活用して 2015年8月1日 〜 2015年9月17日 までの 48 日間における各店舗の売上(Sales)を予想することが目的でした。
店舗データ

店舗データには Store 1 から 1155 までの 1155 店舗に関するデータが含まれています。このデータには、店舗の形態や競合店舗との関係、店舗別のプロモーションの有無などが含まれています。以下に各カラムの説明を添えておきます。
| カラム | 意味 |
| Store | 店舗ID |
| StoreType | 店舗タイプ a, b, c, d の 4 タイプがある |
| Assortment | 店の装飾レベル a = basic, b = extra, c = extended |
| CompetitionDistance | 競合店舗との距離 (m) |
| CompetitionOpenSinceMonth | 競合店舗の開店月 |
| CompetitionOpenSinceYear | 競合店舗の開店年 |
| Promo2 | 1 =継続的なプロモーションを開催中、0 = それ以外 |
| Promo2SinceWeek | 継続的なプロモーションを開始した(年の)週目 |
| Promo2SinceYear | 継続的なプロモーションを開始した年 |
| PromoInterval | 継続的なプロモーションの開始月(例:Feb,May,Aug,Nov) |
店舗毎の日別売上データ

店舗毎の日別売上データからは、Sales、来客数、当日のイベントなど日々の店舗の動向が含まれています。以下は各カラムの説明です。
| カラム | 意味 |
| Store | 店舗ID |
| DayOfWeek | 曜日 |
| Date | 日付 |
| Sales | 売上(額) |
| Customers | 来店客数 |
| Open | 1 = 開店日, 0 = 休業日 |
| Promo | 1 = プロモーションが実施中, 0 = 未実施 |
| StateHoliday | a = 州の祭日, b = イースター, c = クリスマス, 0 = その他 |
| SchoolHoliday | 1 = 学校の休校日, 0 = その他 |
評価尺度
このコンペでは予測したSalseの評価尺度として、 RMSPE という以下の計算式が用いられています。
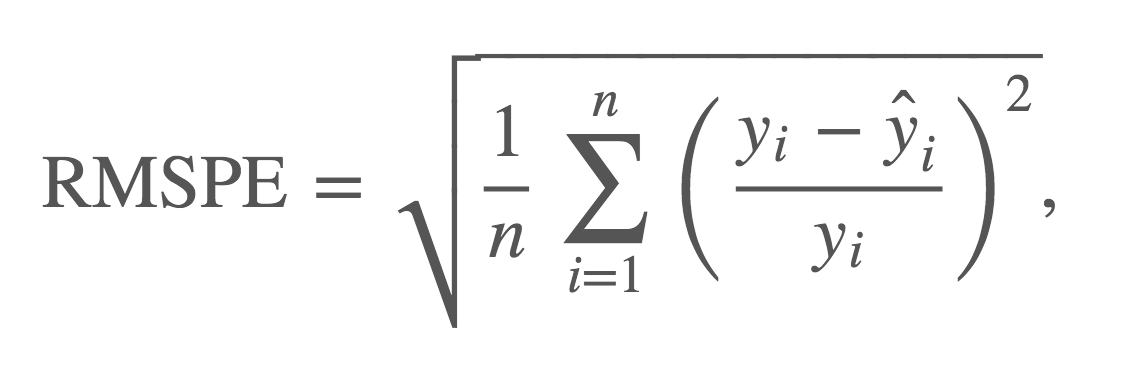
RMSPEは、実際の Sales と、予測した Sales の誤差の割合をベースに算出される値で、0 に近く小さいほど良いというものです。仮に全ての店舗の全ての日の Sales の予測値が実際の Sales と一致していれば RMSPE = 0 となります。
売上予測結果の一例
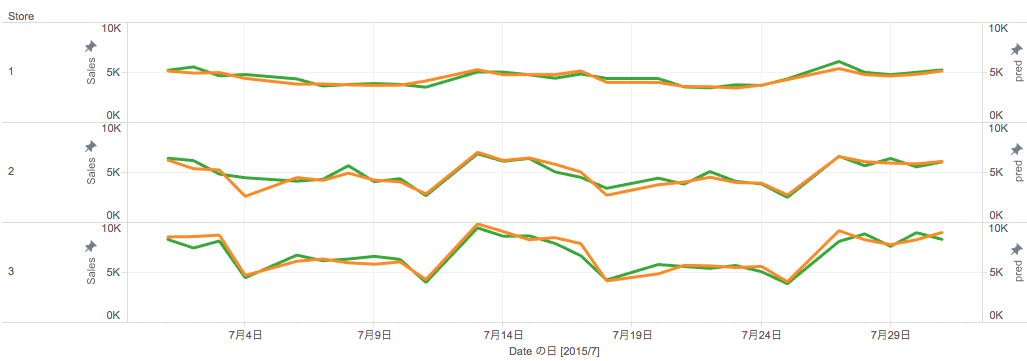
コンペのイメージを湧き易くするために、実際に予測モデルで予測した売上の結果についてお見せします。下図は2015年6月までのデータを使って、2015年7月の売上を予測したもの(緑線)と実際の売上(橙線)を3店舗分可視化したものです。なかなか良く売上の予測ができていることが見て取れます。以降では、この予測モデルの構築について説明していきます。
Rossmann Store Sales での取り組み
情報収集
まず重要なことはコンペの目的やデータを十分に把握することです。そのためには情報収集することが不可欠ですが、この情報収集に最適な場が各コンペ毎に設けられているフォーラムです。

このフォーラムには、世界中の Kaggler からの Q&A や各自が見つけた知見などが豊富に共有されています。例えば Rossmann のフォーラムからは、データの分析・可視化の共有記事や予測モデルの実装コードなどがあります。フォーラムには僕たちも大変お世話になりました!
Forum には多くの記事があるので全ての記事に目を通すことは大変ですが、各記事に付いている Vote 数が多い記事は他の Kaggler が評価している記事なので優先して参考にすることをお勧めします。
検証用データの分割
今回のコンペの目的である Sales の予測のために、機械学習を用いて予測モデルを構築していくわけですが、その前に予測モデルによる予測結果の性能・精度を評価する仕組みが必要です。この仕組みとして、クロスバリデーションという手法がよく利用されます。クロスバリデーションは下図のイメージのように、予測結果の精度を評価するために、学習用データと評価用データを複数セット作成して、各セット毎に予測モデルの学習と予測精度の検証を行う手法です。これは過学習と呼ばれる過度に学習データにフィットし過ぎたモデルを作るのを防ぐために重要です。
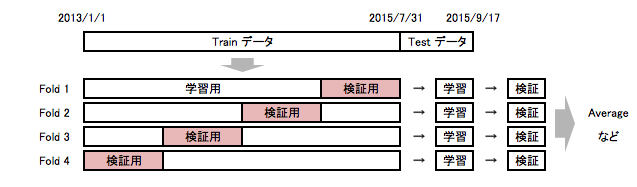
ただし、今回は予測したい値が時系列的な依存が強いので、Trainデータからランダムに検証用のデータをサンプリングするのではなく、下図のようにTrainデータの中で直近のn日を検証用のデータとしました。

公開スクリプトの活用
予測モデルの評価をする検証用データを用意した上で、これからコンペの目的である Sales 予測を算出するための予測モデルの実装に取り掛かりました。
ここで Tips ですが、実は Kaggle には、他の Kaggler が作った予測モデルの実装スクリプトを参考にできる以下のような仕組みが豊富にあります。
- Forum に共有されているスクリプトを活用
- Script の検索機能を使って言語など条件を指定して検索
- Leader Board から拝借
参考までに、ここでは一番簡単な 3 番目の方法について紹介します。

実はコンペ別の成績表である LeaderBoard には、各 Kaggler の順位とスコアと一緒に、そのスコアを出した submit 結果のデータと、そのデータを作ったスクリプトが公開できる機能があります!つまり、LeaderBoard の名前の横にグラフアイコンがある場合には(上図参照)、それをクリックすることで、その Kaggler が submit した結果のデータと、そのデータを作ったスクリプトも参照(利用)できてしまうのです。この機能があれば Kaggle ビギナーの方でも簡単に submit ができるようになるので便利な機能です。
僕らも、予測モデルには GBDT を、実装に xgboost を使っている公開スクリプトを活用しました。しかし、公開されているスクリプトは後述する Feature Engineering などなど、高い精度・スコアを出すための実装はほぼ含まれていません。あくまで簡単な予測をするだけの Kick Start 的なものが殆どですが、ビギナーの方はここから始めるのがおすすめです。
Feature Engineering
精度の良い予測モデルを作成するためにはFeature Engineeringが非常に重要です。Feature Engineeringとは与えられたデータから予測に効きそうな特徴量(=Feature)を作成・変換(=Engineering)することで、ドメイン知識を利用したり、データドリブンに行ったりします。以下に、幾つかの事例を紹介します。
Date の分解
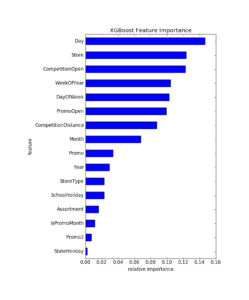
店舗・日別売上データに含まれる Date カラムの日付データは 2013-07-01 のような形式になっていますが、この日付データから、年(Year)・月(Month)・日(Day)・曜日(DayOfWeek)・年における週目(WeekOfYear)などへ分解して新たな特徴量を作ります。これは曜日や月によって売上は大きく変わるだろうというドメイン知識に基づいて行っています。これらの特徴量がどれだけ有用であったかを示すのが GBDT における特徴量の重要度(Feature Importance)を示す下図です。これを見ると Store や CompetitionOpen など元々含まれていた特徴量以上に、日(Day)など日付データを分解した特徴量は予測に有用なことがみてとれます。
また、日付データから作成した週目(WeekOfYear)などはデータドリブンで追加した特徴量の例で、以下のように可視化して、どの店舗でも同じ週目(横軸)で Sales (縦軸)が上り下がりしている傾向が見て取れ、週目という特徴量に店舗を横断した規則性があるように見えたためです。
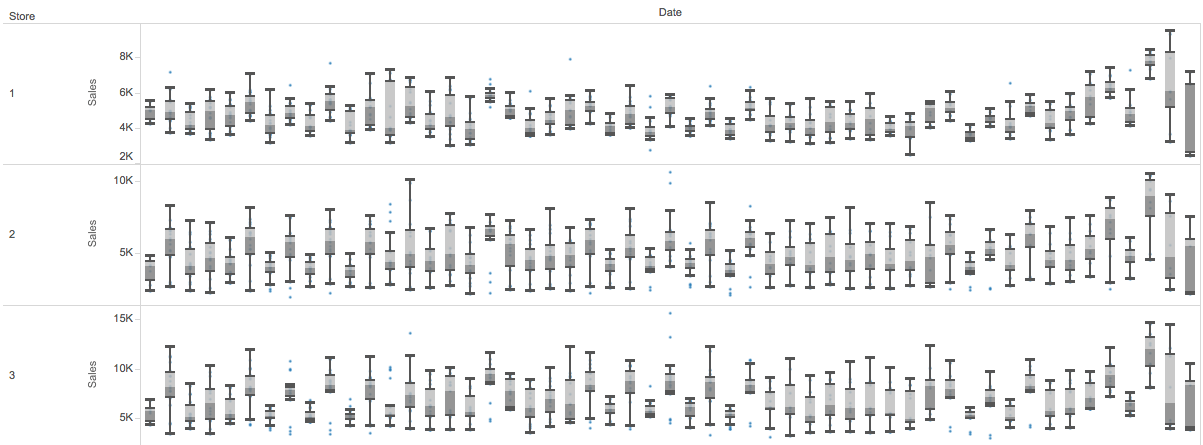
実際、この特徴量を追加することでスコアを改善することができました。
その他にも、月の前半・中盤・後半のいずれかを表すダミー変数を特徴量として追加することでスコアを改善することができました。
気象データの追加
次に試みたのは外部データの利用です。ただし、元々提供されているデータ以外の外部データの利用が可能かどうかはコンペ毎のルールに寄りますので利用には注意が必要です。今回、外部データとしては気象データを利用しました。

一般に、日々の店舗の Sales は当日の気象条件に影響されると考えられます。もし店舗のあるエリアの気象データが活用できると、予測の精度は向上するはずです。
今回は店舗に関する位置情報はデータに含まれていませんでしたが、店舗・日別売り上げデータに含まれる州の祭日(StateHoliday)、学校の休校日(SchoolHoliday)を使って、ドイツの州によって異なるこれらの日のパターンを当てはめると、なんと大抵の店舗がドイツにある全 16 州にマッピングできてしまうのです!ちなみに、この手法も前述のフォーラムで共有されていた情報でした。
この各店舗と州のマッピング情報と、個別に入手したドイツの州別の気象情報を組み合わせることで、州という広い範囲のデータではあるものの、店舗・日別で晴れや曇りなどの天気、最低・最高気温、降雨量、風速など、顧客の来店数に影響しそうな特徴量を増やすことができました。
ただし、この気象データは未来の売上を予測したいときには、知り得ない情報(天気予報なら使えるが数日先までしか確度がない…)なので、実ビジネスでは使えません。。データリーク(Leakage)と呼ばれる問題の一つですが、それも分かった上で他のKagglerも使っているようなので今回は利用することにしました。
州別平均客単価の追加
日本でも地域別に人口一人当たりの収入額が異なりますが、ドイツでも同じことが言えるようで、下図のようにドイツ各州では人口一人当たりの収入額にかなりばらつきがあることがわかりました。
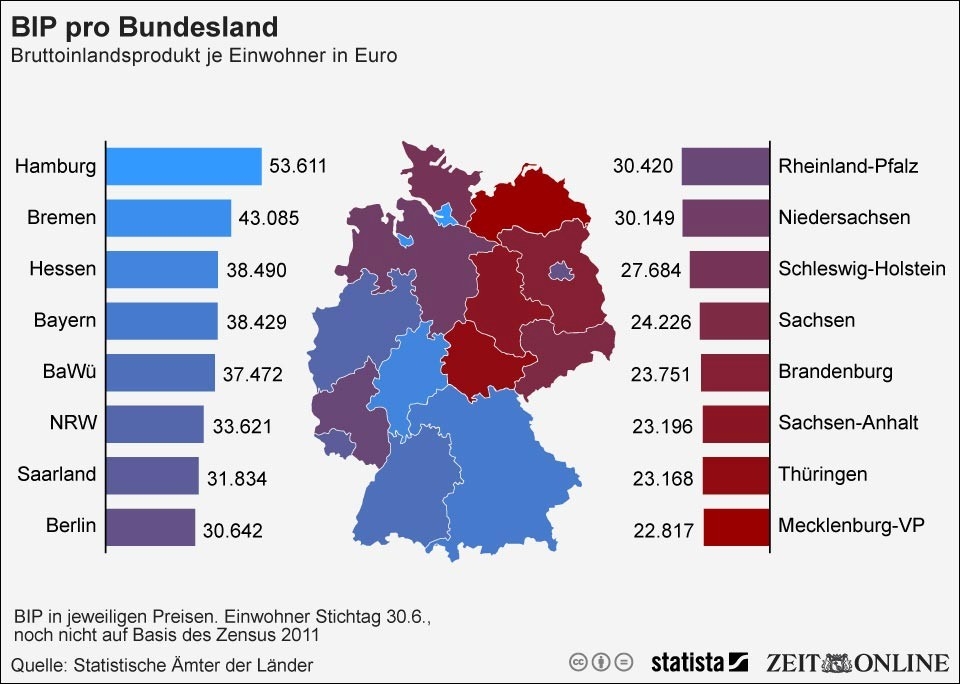
これを見ると、一人当たりの収入が最も多い州と少ない州とでは約 2.5 倍もの差があるようです。このことから、州別に消費者の支出額が大きく異なるのではという仮説のもと、州別の平均客単価も特徴量として付け加えました。その結果、若干ではありますがスコアが改善しました。
Feature Selection
Feature Engineering と並行して、Feature Selection (特徴量の選択)も行いました。Feature Selection は、予測精度の向上に寄与しない特徴量を予測モデルの学習に含めないことで、過学習を抑えた予測精度の高い予測モデルを構築することが目的です。
特徴量の選択は、それぞれの特徴量による予測精度への寄与の割合を、なんらかの情報量基準によって測り、それらの値の上位の特徴量を予測モデルの学習データに含めるという方法があります。しかし、この方法を試した結果、ローカルで測定したスコアと submit した時のスコアに一貫性が見られませんでした。そのため、今回は特徴量の組み合わせを試行錯誤し、LeaderBoard 上のスコアを参考に最もよい特徴量の組み合わせを探しました。
ハイパーパラメータのチューニング
ほとんどの予測モデルにはハイパーパラメータというモデルの複雑さを制御するパラメータがあります。例えば、GBDTのような決定木をベースとしたモデルには、ハイパーパラメータの一つに”木の最大の深さ”があり、このパラメータを大きくすればするほど、多くのパターンを学習した複雑なモデルを作ることができます。しかし、過度に複雑なモデルは過学習を引き起こし、新しいデータに対する予測精度が低下するという問題が起こります。新しいデータに対する予測能力のことを汎化性能と呼びますが、これが最大となるようにハイパーパラメータをチューニングします。グリッドサーチをして主要なハイパーパラメータは下記のようにしました。
- nrounds=4000
- max_depth=10
- eta=0.02
- subsample=0.9
- colsampe_bytree=0.7
Bagging
予測モデルの汎化性能をより高めるためにBaggingという手法を最後に使いました。今回は、ブートストラップ法で作成した 50 組の学習データを使って、これまで説明してきた GBDT の予測モデルで学習した結果の平均値を最終的な売上予測データとして作成しました。汎化性能を高めるためには他にも、複数のモデルを組み合わせるアンサンブルや、さらにそれを多段にするスタッキングなどがKaggleなどのコンペでは良く使われていますが今回はそこまではやりませんでした。
そして、微調整
最後に検証データで全体の誤差率のズレを確認し、予測値を補正しました。
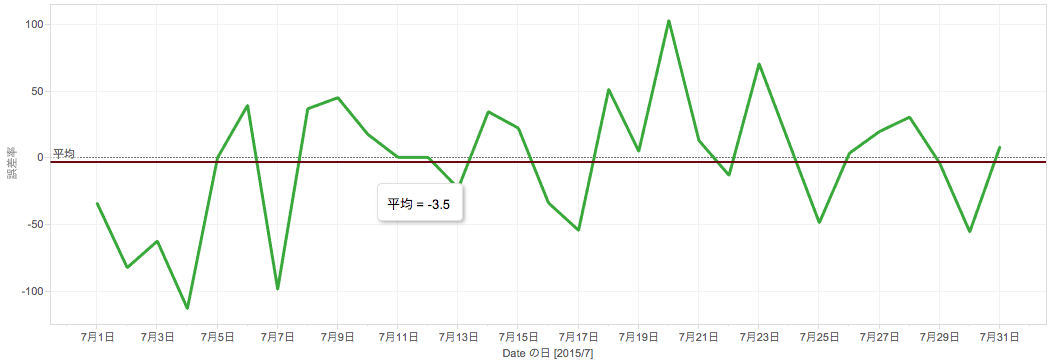
この図の緑線は各店舗の日別の誤差率(実際の値 – 予測値)の合計を表しています。少し見にくいですが、誤差率の平均(赤線)を算出すると、若干ですが平均で -3.5 だけマイナス側に偏っていることがわかります。つまり、作成した予測モデルが、実際の値より大きく予測値を算出してしまう傾向があるということがわかります。このため、予測値を低く補正する係数(0.997)を予測モデルの出力に掛けることで最終的な売上の予測値を補正しました。
まとめ
最終的な順位はあと少し?で Top 10 も見えるところまで迫れましたが、スコア面で見ると Top 10 にはいる Kaggler とは大きな隔たりがありました。一体 Top Kegglers はどんなことをして、どこが違うのか気になっていたのですが、なんと Rossmann コンペの優勝者の Kaggler Master でもある Gert さんが今回のコンペで実践されたことをレポートとしてまとめてくれています。また、優勝者のインタビュー記事でもかなり詳しくその手法を紹介してくれていています。

優勝するほどの Kaggler と僕たちの取り組みではいろいろと異なることがありここでは紹介しきれませんが、インタビュー記事で見つけた Gert さんの印象的なコメントだけ紹介します。Gert さんは「I spent 50% on feature engineering, 40% on feature selection plus model ensembling, and less than 10% on model selection and tuning」と言っています。なんと作業時間のうち、全体の 90 %の時間を使って Feature Engineering / Selection を行うそうです。とかく機械学習の予測モデルを構築するとなると、学習器の性能に注目をしてしまい、学習器の選別やそのパラメータチューニングにフォーカスしてしまいがちですが、それよりしっかりとデータ自体を分析して、特徴量を作成と選択をすることがより良い予測モデルの構築に重要なようです。
今回の取り組みでは、Feature Engineering には大分時間をかけて有効な特徴量探したつもりでしたが、なんと Gert さんは僕たちよりも倍以上の数の特徴量を作っていました!
また、モデルパラメータのチューニングやアンサンブル(今回でいうと Bagging)にもかなり時間を費やしましたが、それよりもよりデータの理解と特徴量の作成に重点をおくべきだったのかもしれません。
などなど、Rossmann コンペへの参加を通して、Kaggle Master を目指して Top 10 入りするための課題や方向性などが見えてきましたので、引き続き Kaggle Master 目指してがんばっていきたいと思います!!
Author