Blog
AWS の新しい機械学習マネージドサービス SageMaker のハンズオンに参加して
8月2日に AWS 様の新オフィスで開催されたAmazon SageMaker|機械学習エンジニア向けセッション+体験ハンズオンに参加してきました。普段は実験用途で社内の GPU 搭載マシンなどを利用することが多いのですが、様々なアーキテクチャやパラメータでモデルの検討をする際にはパブリッククラウドの恩恵を受けることも多く、EC2 などで GPU インスタンスをスポットで立ち上げたりしています。今回はずっと気にはなっていたものの、名前だけしか聞いたことのなかった SageMaker の講義とハンズオンが開催されるということで申し込んでみました。

SageMaker について
まずは SageMaker 概要についての講義を受けました。
SageMaker は2017年12月にリリースされた機械学習の統合ワークロードを提供する AWS マネージドサービスです。2018年8月現在では東京リージョンにおいても利用可能となっています。パブリッククラウド上における機械学習システムでよくある問題を解消し、データサイエンティストやエンジニアが素早く PDCA を回せるような趣向が凝らされています。
機械学習におけるプロセスは学習と推論の2段階に分かれますが、実務などで実際に機械学習システムを構築する際には、学習・推論を適切に行うための開発作業も発生します。具体的には学習用コードの記述、小規模データでの動作検証、推論リクエスト受付用エンドポイントの提供などが挙げられます。しかしながら、学習用コードの記述やそれに対する逐次的な修正などを学習で利用されるような高スペックインスタンスや GPU インスタンス上で直接行うことはコスト面での効率が悪いですし、推論用のエンドポイントの構築・提供は純粋にエンジニアリングの領域となってくることが多いためデータサイエンティストや研究者には荷が重いタスクであるといった問題があります。
こういった開発・学習・推論にまつわる問題を解決し、一気通貫なワークロードを提供するサービスが SageMaker です。Jupyter Notebook を動作させるための最低限スペックのインスタンス上で開発作業を行い、学習時には Docker コンテナを高スペックインスタンス上で走らせ学習ジョブが終わり次第自動でコンテナが終了する仕組みとなっています。また、推論用のエンドポイント作成についても API を叩くだけで Docker コンテナとして簡単にプロビジョニングが走り、オートスケーリングや A/B テストを行うための機能も提供されています。
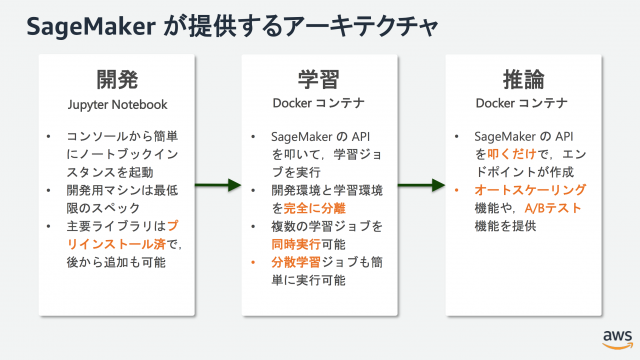
SageMaker には線形回帰、GBDT、画像分類、物体検出など昨今の機械学習でよく用いられる定番アルゴリズムが予め組み込まれているため、学習データさえ用意すれば SDK を利用してすぐに開発・学習に取り掛かることができます。各種 Deep Leaerning ライブラリ(TensorFlow/Chainer/PyTorch/MXNet)も取り揃えられており、ビルトインアルゴリズムにない独自モデルの学習も可能な上、オリジナルの学習データと学習用 Docker コンテナさえ用意してしまえばビルトインアルゴリズムやライブラリに拘らない形での開発・学習環境を提供してくれます。

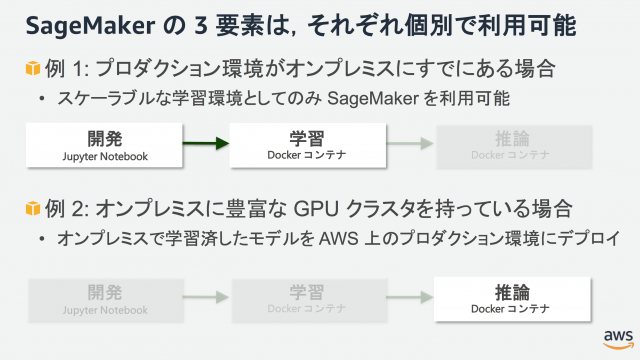
また、開発・学習・推論のそれぞれは個別に組み合わせが可能となっています。例えば開発・学習は SageMaker で行い、モデルを自前の環境にコピーしてくることで推論環境は独自で提供するといったことが柔軟に行なえます。もちろん逆も然りで、我々研究者がローカル GPU マシンで学習したモデルを試験的に提供するといった際に、システムを都度構築せずとも SageMaker の推論エンドポイントを利用するだけで外部公開が行えます。
他にもSageMaker にはベイズ最適化によるハイパーパラメータチューニングや推論時に読み込むモデルを複数指定しての A/B テストなど魅力的な機能が搭載されています。どれも機械学習プロセスにおいて嬉しい機能ですね。
ハンズオン
次に実際に AWS SageMaker 上でのデモ学習についてハンズオンにてご講義いただきました。
ハンズオン用の資料はすべて Jupyter Notebook 形式で配布していただきました。もちろん SageMaker 上で即実行可能であり、各タスク用のノートブックを開きセルを上から順番に実行していくだけでハンズオンが完了するという親切設計です。家に帰ってからの復習も容易です。
内容は下記になります:
- RandomCutForest を利用した時系列データの異常検知
- XGBoost を利用した MNIST データセットの画像分類
- Chainer フレームワークを利用した MNIST データセットの画像分類
機械学習タスクとしては基礎的な内容でありながら、SageMaker のエッセンスを理解するには丁度よい分量であるように感じました。SDK を利用してコードを記述していくわけですが、普段通り AWS SDK を利用することも可能となっていはいるものの、データサイエンスや研究向けには SageMaker SDK が用意されています。こちらは AWS SDK を scikit-learn ライクにラップしたインターフェースを提供しており、 SageMaker 上での機械学習モデルの開発・学習に特化しています。また、ハンズオンの内容ではありませんが、SageMaker Example Notebook 上にも沢山のコード例が Jupyter Notebook 形式で掲載されているため、簡単に試すことができるようになっています。
注意点としてクラウドサービス全般に言えることですが、未使用のリソース(SageMaker においては開発用インスタンスと推論エンドポイント)のシャットダウン・削除忘れにだけは気をつけなければいけません。
ちなみに講義前には $25 のクーポンをいただけました。結局この日のハンズオンにかかった料金は $0.2 程度だったので、むしろお金を頂けたぐらいのとてもありがたい話です。

まとめ
以上、SageMaker についての簡単な解説と当日のハンズオンについての所感を記しました。コンピュータビジョン系の研究員としてはビルトインアルゴリズムに Style Transfer や GAN などが含まれているとより楽しそうだと感じましたが、学習したモデルをデモアプリなどで提供する際に推論エンドポイントの構築が容易な点、使い慣れている PyTorch がライブラリとして組み込まれている点はとても嬉しい限りです。
クラウドサービス自体はウェブシステムのエンジニアをしていた時から利用しているのですが、月並みながらこれまで自前で構築・運用していた仕組みやシステムが急速に置き換わっていくのをひしひしと感じます。機械学習やデータサイエンスにおけるシステムも例外ではなく、全てを自前でこなすことはもはやリスクとも言えるかと思います。今後もクラウドとのより良い付き合い方を模索していきたいですね。
今回のハンズオンでは基礎的なタスクをこなしたため、次は実際に自分の研究タスクにて使用し、また使用感や出来上がったデモなどでお見せし、このブログでご紹介できればと思います。
Author