Blog
論文紹介:Budget Constrained Bidding by Model-free Reinforcement Learning in Display Advertising
AI Labの宮西です。
今回は、情報検索やナレッジ・マネジメントに関する国際会議CIKM 2018(Conference on Information and Knowledge Management)で発表された
Budget Constrained Bidding by Model-free Reinforcement Learning in Display Advertising
という論文を紹介します。
この論文では、ディスプレイ広告のReal-time bidding(RTB)において、強化学習を使った入札戦略最適化の手法を提案しています。
提案内容をまとめると、
予算制約のある入札問題に対して
- モデルフリーな強化学習の適用
- 報酬関数の改良
- 深層強化学習フレームワークの実装・実験
となっています。
予算制約付き入札問題
予算制約付き入札問題について、先行研究Weinan Zhang et al., 2014、Weinan Zhang et al., 2016にて、
最適な入札価格が\(v/\lambda\)で表されることが示されています。
(\(v\): インプレッションの価値(KPI依存で、例えばCTRなど)、\(\lambda\): スケールパラメータ)
パラメータ\(\lambda\)によって入札額を調整することができ、
・\(\lambda\)が大きいと、入札額は低くなり、予算が消化されにくくなくなる。
・\(\lambda\)が小さいと、入札額が高くなり、予算消化が早まりインプレッションを取り逃す。
という傾向があります。
最適な\(\lambda\)を見つけたいのですが、
・落札額が予測困難
・途中で予算やターゲティングなどの設定を変更する可能性がある
といった理由で、最適な\(\lambda\)を見つけるのは困難です。
そこで、この論文では強化学習を使ってパラメータ\(\lambda\)を適切に調整する手法を提案しています。
強化学習と制約付きマルコフ決定過程
強化学習は、たいてい状態空間\(\mathcal{S}=\{s\}\)・行動空間\(\mathcal{A}=\{a\}\)・状態遷移\(\mathcal{T}\)からなるマルコフ決定過程(MDP)としてモデル化されます。
即時報酬関数\(r:\mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R}\)、割引率\(\gamma\in [0, 1]\)とし、方策を\(\pi:\mathcal{S}\rightarrow\mathcal{P(A)}\)で表すとします。
ここで求めたいのは、時刻Tまでの割引報酬和\(R=\sum^{T}_{t=1}{\gamma^{t-1}r_t}\)を最大化する方策で、
$$\pi^*=argmax_{\pi}\mathbb{E}[R|\pi]$$
で表される\(\pi^*\)です。
環境との相互作用でコストが発生し、これに対して制約を設けるように拡張したものが制約付きマルコフ決定過程(Constrained Markov Decision Process(CMDP))です。
定式化すると以下の通りで、K種類のコスト全てに対して制約を満たした上で、割引報酬和の期待値を最大化します。
$$max_{\pi}\mathbb{E}[R|\pi]$$
$$s.t. \space \mathbb{E}(C^k|\pi)\leq{\hat C}^k \space \forall k\in {1,…,K}$$
提案手法
上記のCMDPを使って、エージェントの行動を入札、制約を予算としてモデル化するのが直感的ですが、
よく使われるモデルベースな強化学習や線形計画法では、事前に状態遷移を予測しておく必要があります。
ところが、RTBの環境は非定常で予測困難なことと、計算コストがかかりすぎる点で、このアプローチは現実的ではありません。
提案する手法では、CMDPでパラメータ\(\lambda\)を調整する問題と捉え、学習手法としてはdeep Q-network(DQN)を採用しています。
学習の流れは論文内で以下のように示されています。
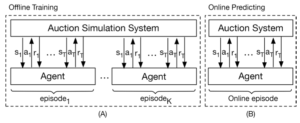
全体をエピソード単位(実験では1日)の期間に区切り、その期間の予算\(B\)とパラメータ\(\lambda_0\)でスタートします。
さらに、エピソードの中をTステップ(実験では1ステップ=15分)に刻んで、ステップごとに観測値を用いて\(\lambda\)を調整していきます。
例えば、t回目のステップ中のi番目のインプレッションに対する入札額は\(v_i/\lambda_t\)となります。
また、t回目のステップ終了時に、即時報酬\(r_t\)とコスト\(c_t\)が発生します。
さらに、効率的に最適解に収束するように報酬関数とε-greedy方策の改良も行っているので、それぞれについて説明していきます。
報酬関数設計
単純に\(\lambda\)を小さくすれば、入札額が上がり即時報酬は増えますが、局所解に落ちてしまいます。
これは、予算制約を無視して早々に予算消化してしまうのと、貪欲な方策のために探索が不足していることに起因します。
こうならない報酬関数を設計したい。。
ということで、エピソード全体のリターンがエージェントの良さを表していると考えて、これが報酬となるように設計してみます。
定式化したのがこちら
$$r(s, a)=max_{e\in E(s, a)}\Sigma^{T}_{t=1}r^{(e)}_t$$
\(E(s, a)\)は、これまでに状態sで行動aをとったことのあるエピソードの集合で、
\(r^{(e)}_t\)はエピソードe内のtステップ目の即時報酬。
つまり、過去に状態sで行動aをとったエピソードの中での最大報酬を返す関数を報酬関数として定義しています。
適応的ε-greedy
DQNはデフォルトε-greedyなので、1-εの確率で行動価値関数Qを最大化する行動を選択し、
εの確率でランダムに行動を選択します。
εはたいてい大きな値から始めて、徐々に小さくしていきますが、早すぎると探索不十分になり、
遅すぎると収束が遅れるという問題も出てきます。
\(\lambda\)を最適値にできるだけ近づければいい。
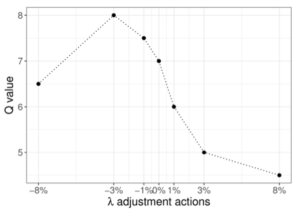
εの更新の仕方として、\(\lambda\)を調整する割合によってQ値の推定値がどう変動するかを利用します。
例えば、\(\lambda\)の調整割合を-8%から8%の間で変えたとき、Q値の動きが下図のように単峰性を持つ場合、
期待する分布なのでεを小さい値に更新していきます。
論文中に示されている例では以下のような場合、単峰性を持つのでεの更新を続けます。
同様の設定で、Q値が下のようになった場合、現在のQ値の推定値が異常なためεを大きくして探索をします。
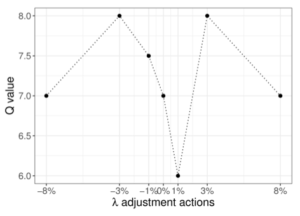
このようにしてεを調整していく適応的ε-greedyを提案手法では採用しています。
深層強化学習フレームワーク
以上を組み込んだDQNベースのフレームワークを、DRLB(Deep Reinforcement Learning to Bid)フレームワークと名付けて提案しています。
DRLBでは、適応的ε-greedyで次の行動を決め、\(\lambda\)を調整し、入札額を決定します。
DQNが学習時に使う報酬は、即時報酬ではなく上の方で提案した報酬関数になりますが、
全ての状態・行動ペアに対応する報酬の履歴を保存しておくのは現実的ではありません。
そこで、新たにRewardNetという報酬を予測するDNNモデルを導入します。
RewardNetは、過去の履歴からサンプリングした状態、行動、報酬のデータを使って、
状態・行動ペアから報酬を予測するモデルとなっています。
実験
設定
データセットとして、EC広告の2018年1月の10日間20億インプレッションを使っています。
最初の7日分で訓練し、残りの3日分で評価します。
エピソードは1日ごとで、1ステップは15分。
比較対象とするベースライン手法としては3つ挙げています。
- 固定線形入札(FLB)
固定値\(\lambda_0\)を使って入札する - 予算平滑化線形入札(BSLB)
エピソードの残り時間と残予算から\(\lambda\)を調整する方法 - 強化学習(RLB)
オークション処理をMDPでモデル化
提案手法であるDRLBの構成については、隠れ層3つで各層が100ユニットの全結合NNで、
RewardNetも同じ構成です。
評価結果
初期値の影響について
初期パラメータ\(\lambda_0\)には、たいてい過去の最適値を使いますが、
実際の環境は都度変化しているため、以前の最適値が現在の最適値\(\lambda^*\)から大きく外れる場合も考えられます。
論文ではまず、このような場合での各手法の性能を比較する実験を行っており、結果が下の表になります。
理論上の最適値を\(\lambda^*\)として、\((\lambda_0-\lambda^*)/\lambda^*\)を\(\lambda\)の偏差(λ Deviation)と定義しています。
この偏差が異なるデータについて、最適報酬\(R^*\)に対する各手法で得られる報酬\(R\)の割合\(R/R^*\)で性能比較を行っています。
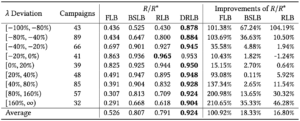
結果としては、提案手法であるDRLBが最も良い性能となっています。
固定した\(\lambda_0\)を使うFLBが影響を最も大きく受けて性能が悪くなっています。
オークションの環境が時間によって変動が大きく、訓練データとテストデータで予算や落札価格が違っていることが原因と考えられます。
報酬関数の収束について
報酬関数の違いによるエージェントの振る舞いがどう変わるかを確認するため、
論文ではRewardNetと即時報酬を使ったモデルで比較実験を行っています。
その結果が以下のグラフで、訓練のステップ数に対する\(R/R^*\)を比較しています。
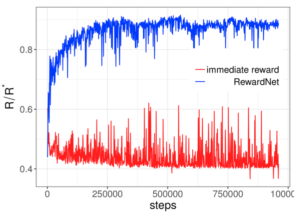
RewardNetが少ない訓練ステップ数で高い\(R/R^*\)に達しているのに対して、即時報酬では低いままになっています。
この結果からRewardNetがエージェントに対して最適な方策を与えられていると言えます。
適応的ε-greedyについて
さらに、論文中で提案した適応的ε-greedyを従来のε-greedyと比較した実験も行っており、
その結果が以下のグラフになります。
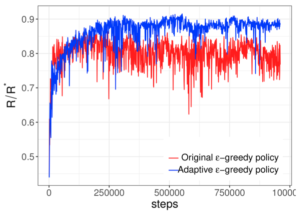
適応的ε-greedyの方が、効果的に探索して高い性能を示しています。
おわりに
ディスプレイ広告のRTBでの予算制約ありの入札問題に対して、強化学習を使った手法を提案し、高い性能になることを実データでの実験で示した論文を紹介しました。
主な提案内容としては、
・即時報酬に代わるRewardNetを提案
→ 予算制約を考慮しつつ探索することで、エピソード全体で最適解を得られる
・適応的ε-greedyな方策を提案
→ 不十分な探索を解消し、効率的に最適解に到達できる
・全部まとめた深層強化学習フレームワークの実装・実験
となります。
今回紹介した論文では、報酬関数の設計が柔軟なため、RTBでの入札問題以外にも予算配分の最適化など単位時間内での行動選択に応用できるかと思います。
Author