Blog
データ基盤へのdbtとCI/CDの導入を内定者がやってみた!
AI事業本部 アプリ運用センターでデータサイエンティストをしている河中と申します。
今回は内定者としてアルバイトに参加している23卒内定者の稲葉さんに、信頼性が高く分析しやすいデータ基盤を構築するためにdbtというツールを導入するタスクに取り組んでもらいました。その中での技術的な話や内定者バイトを通して学んだことをブログにまとめてくれました。
ぜひ一読ください!
23卒エンジニア職内定者の稲葉です。2022年10月から3ヶ月間、AI事業本部小売DXディビジョンのアプリ運用センターでアルバイトをさせていただきました。私は、今までデータサイエンティストやバックエンドエンジニアなど幅広く技術に関わってきましたが、今回はアナリティクスエンジニアとしてデータ基盤の改修を行いました。
本稿では、Snowflake上で構築されているデータ分析基盤を dbtやgithub actionsのCI/CDを用いて改修を行った経験をレポートにしてまとめます。
アプリ運用センターとは

サイバーエージェントでは現在、小売/行政/医療などのドメインにおいて様々な企業様と提携し開発を行うDX事業に取り組んでいます。アプリ運用センター(通称アプ運)はその中でも小売事業を展開されている企業様向けにアプリ開発/データ基盤構築をはじめとした開発から運用、コンサルティングなどを行う事業部です。POSシステムやAIカメラ、ビーコンなどの多岐にわたるテクノロジーを連携し、アプリ単体ではなく購買体験全体のUXを高めるアプリ開発を実現して行きます。(詳しくはこちらでご確認ください)
取り組んだことと目的
今回のインターンでは、小売店における購買やアプリ行動ログを集約するデータ基盤にdbtとCI/CDの導入を行いました。dbtとCI/CDを導入することで、データに対する継続的な信頼性を担保することやgithub, ER図と実際に動作しているコードの同期をとることでデータ基盤内を整備することを目的としています。
dbtとは?
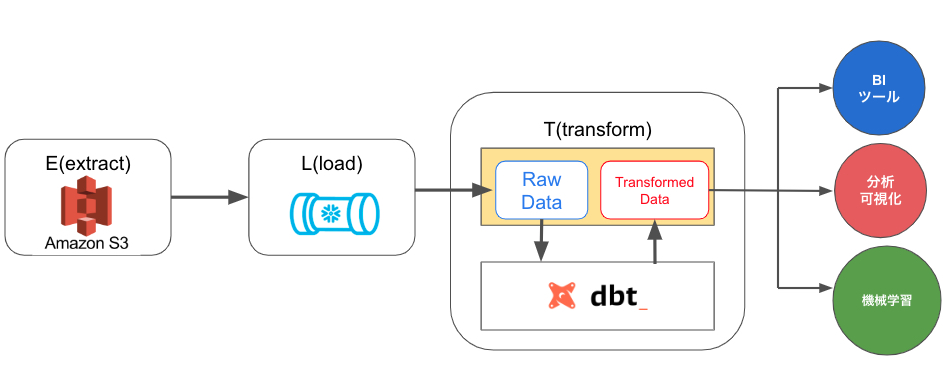
dbtとは、ELTデータパイプラインのTの部分を担っているツールで、既にデータがロードされている状態で、データを分析者が利用しやすい形に加工・変形することができます。また、select文だけで テーブル や ビューを作成することが可能で、データエンジニア以外でもテーブルやビューを簡単に作成し分析に活用できるメリットもあります。
dbt導入でのシステム構成とデータ基盤管理について
dbtには、有償のdbt cloud とdbt cli の2つがあり、それぞれ下記のようなメリット・デメリットが存在します。

今回は、dbt cloudとcliの両方を導入し役割を分担する環境を整備しました。データの定期更新については、諸事情でワークフローエンジンを使いにくい状態にあったため、dbt cloudを使用しました。一方、データサイエンティストが頻繁に作成するようなクエリのコード管理については、dbt cliを使用しました。この後、データベース内の構造を簡単に紹介した後に、データベース内で管理する役割、dbt cloudとcli 両方を導入するメリットの詳細を説明します。
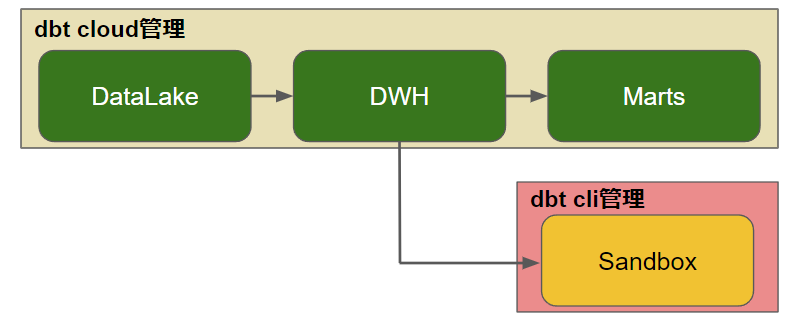
データベース内の構造
データベース内は、 rawデータを扱うDataLake層、rawデータをリキャストしたデータやそれらから作成された1次集約を扱うDWH層、特定のビジネスKPIをはじめとしたBIツール等で可視化するために集計処理をしたテーブルやビューを扱うMarts層の3層構造になっています。これらに加え、自由な分析環境を提案するためのSandboxが別に設定してあります。
dbt cloud, cliを両方導入するメリットとそれぞれの役割
dbt cloudでは、定期実行処理の管理を行うだけでいいDataLake、DWH、Martsを管理し、dbt cliではデータサイエンティストが自由なモデリングを行うSandboxを管理しています。それぞれ、dbt cloudの運用はロール権限が高いデータエンジニアが担い、dbt cliは誰でも自由に利用できるような構成になっています。
このようにdbt cloud, cli 両方を導入し開発環境を分離することで、dbt cloudを利用する人数を絞ることができ、金銭的コストを抑えられるといったメリットがあります。またロール権限を dbt cloudとcliで分離することもできるので、Sandboxに変更を加えてもdbt cloudの管理している領域には影響がありません。そのため、間違えてデータを消してしまったなどの事故を事前に防げるので、安全な開発環境を整備できるといったメリットもあります。
dbt cloud × snowflake × CI/CD
現状、github上でコードを管理しているが実際に動作しているコードはsnowflakeで実行して変更を反映しているため、正確にgithub上のコードと実際に動作しているコードの同期が取れていないという課題があります。この問題から生じる弊害としては、以下があげられます。
- snowflake上のコードに変更を加える際の信頼性の低下
- 動作しているテーブル、ビューの正当性の欠如
また、上記に付随しdbtとCI/CDを組み合わせて導入することにより、dbtのtestを実施できることやレビュー体制を整えることができ、データの正常性を十分に担保した状態でsnowflakeに反映させることが可能になります。具体的にCI/CDが動作するのは、以下の2つのタイミングです。
- プルリクエストが作成されたタイミング
- それらのプルリクエストがmainブランチに merge されたタイミング
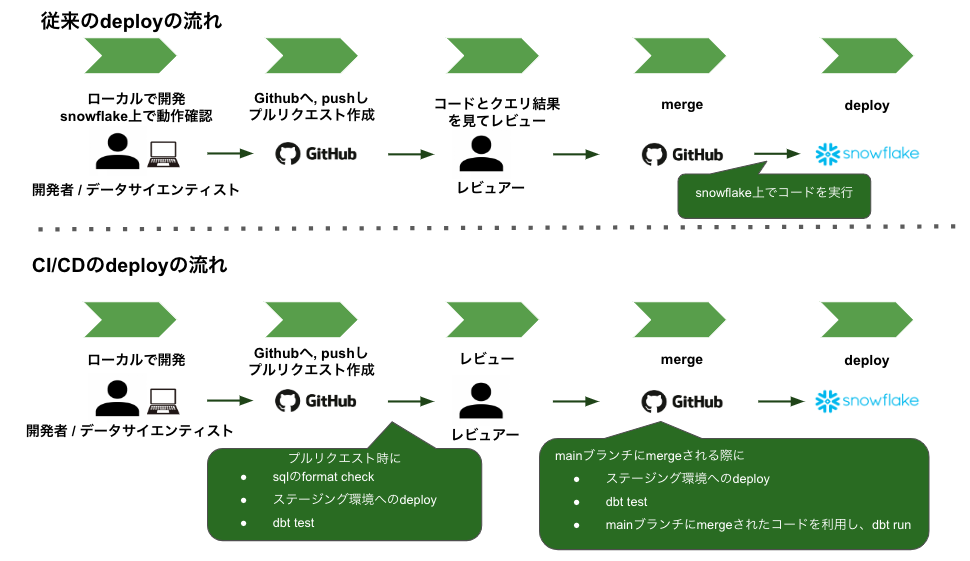
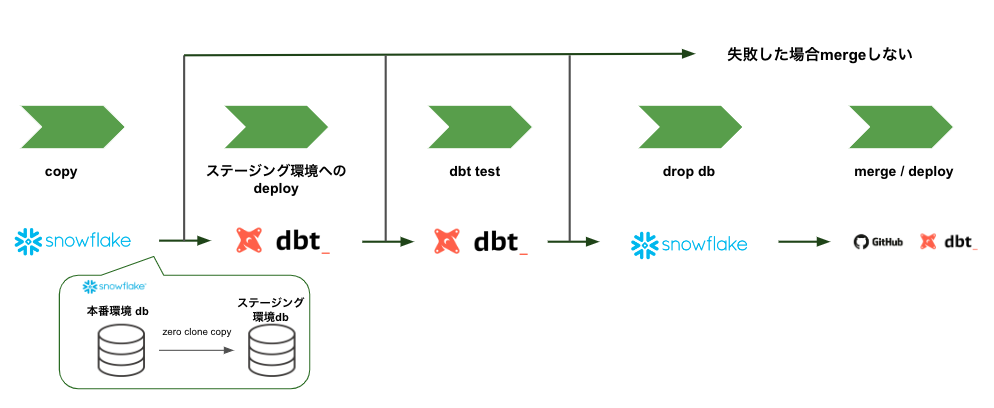
1. プルリクエストが作成されたタイミングでの CI/CD
プルリクエストが作成されたタイミングでは、以下の3つの動作を行います。
- dbtに対応したsql formatterでのformat check
- ステージング環境へのdeploy
- deployされたデータに対するテスト
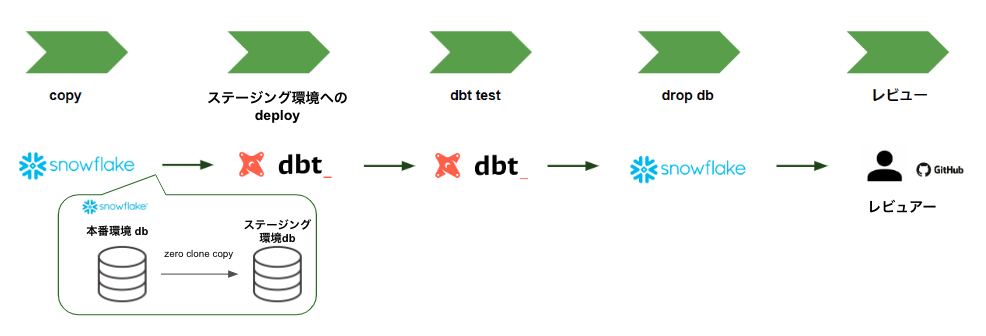
また、プルリクエスト作成時にステージング環境でのテストを行う主な目的としては以下の3つです。
- 本番環境のデータ/構成で本番環境を破壊する心配なくテストができる
- テストをすることでデータの信頼性を確認できる
- 実際に動作させることで、それらの動作結果がレビュアーの補助になる
ステージング環境への本番環境データのcopyには snowflakeのzero clone copyを利用します。zero clone copy はデータの複製は行わないため、時間や容量を節約してデータの信頼性を担保することが可能になります。
2. プルリクエストがmergeされたタイミングでのCI/CD
プルリクエストがmergeされる直前にもCI/CDと同じ動作を実行します。これらの動作を2度行う理由としては、プルリクエストがmergeされる直前の変更により生じたバグをmainに取り込まないためです。最終的に問題があった場合は、mainにmergeされませんが、なかった場合はmainにmergeされsnowflake上の本番環境に変更が反映されます。
実際にCI/CDを導入したときの課題
実際にCI/CDを導入すると1次集約を作成するために膨大な量のデータをフルスキャンするため、プルリクエスト時とmerge時のCI/CDの実行時間が合計で4時間程度かかってしまうという課題がありました。
今回 導入するCI/CDの主な役割としては、過去から現在までのデータ全てに対する品質担保ではなく、クエリが想定した通りの出力をしているのかどうか?を確認することです。そのため、実際に用いる1次集約を作成するためのデータは、直近1週間程度に絞りました。このようにすることで、CI/CDの実行時間を大幅に短縮しつつ、直近のデータのみでクエリ出力が想定通りか判断することが可能になります。
内定者バイトを通して
1. 実運用を想定した設計・検証の重要性
内定者バイト期間で学んだ一番のことは実運用を想定した設計・検証の重要性です。現状、タスク間の依存関係をワークフローエンジンで管理しているわけではなく、定期実行で管理しています。その中でデータの連携漏れがないか、またデータを変換する上で制約条件を満たしているかなど本番環境と同様の環境で検証を実施していかないと実運用を想定した設計にはなりません。そのため、それらを意識しつつ制約条件の洗い出しをドキュメントにまとめ検証していきました。実運用を想定し続けることは考える項目がとても多く難しかったのですが、信頼できるデータからユーザごとに最適化されたクーポン配布やプッシュ通知、UI/UXの改善などを行うためにとても重要だったと感じています。
2. 小売DXでの運用・施策をするための分析力や知識の広がり
私のチームでは分析を共有するタイミングが多くあり、専門的な知識を有するメンバーが積極的に自身の分析結果を発表している環境でした。 また、今回の業務ではデータ基盤の改善を中心に行っていましたが、A/Bテストや経済学的なアプローチ・統計的手法を利用しながら分析する技術に触れる時間が豊富にありました。施策を行った上での効果検証の重要性に関して知ることができ、小売における分析知識向上につながったと思います。
3. 小売DXの魅力
今回のインターンでは、小売に関するデータに触れる貴重な機会を得られました。小売のデータは、主にアプリのデータと実店舗から得られるデータの2種類があり、それら両視点から売り上げを伸ばすための施策を考えていくことが重要になります。データ基盤やデータ分析の業務を通して、小売DXが持つデータの特異性や応用の可能性を知ることができ、小売DXに携わる面白さを感じたとともに小売DXの醍醐味はここだなと感じました。
最後に
今回の内定者バイトでは、多くの方との繋がりを持てたとともに、協力していただきながら データ基盤の整備を進めることができました。また今回は、同じ部署でデータエンジニアとして働いている千葉さんにたくさんのレビューをいただきました。千葉さんのCA Base Next での発表も非常に面白いのでぜひこちらもご覧ください!
充実した内定者バイトの3ヶ月間はあっという間でとても楽しかったです。
メンターである河中さんをはじめ、協力してくださった方々ありがとうございました!
Author