Blog
【採択論文紹介】高性能なテキスト生成アルゴリズムMBR Decodingの分析 (NAACL2024)
AI Lab NLPチームの本多です。この記事では、最近注目が高まっているテキスト生成アルゴリズムであるMinimum Bayes-Risk decoding(以下、MBR decoding)について分析を行った論文を紹介します。この研究はAI Labのリサーチインターンシップにて名古屋大学の大橋厚元さんに取り組んでいただいたもので、研究成果はNAACL2024に採択されています。
On the True Distribution Approximation of Minimum Bayes-Risk Decoding [Code]
Atsumoto Ohashi, Ukyo Honda, Tetsuro Morimura, Yuu Jinnai
はじめに
最近ChatGPTをはじめとした大規模言語モデルの発展がめざましく、テキストの自動生成を行うテキスト生成モデルは我々の生活に身近なものとなってきています。テキスト生成モデルから生成されるテキストの品質は、生成モデルだけでなく、生成モデルの出力から望ましいテキストを得るための探索アルゴリズムにも大きく依存します。今回我々が扱うのは、この探索アルゴリズムとして特に注目を集めているMBR decodingです。
MBR decodingは以前から機械翻訳などにおいて用いられてきましたが、ビーム探索など他の探索アルゴリズムの影に隠れてしまい、注目されているとは言い難い状況でした。最近になって、用いるサンプリング手法や効用関数の見直しによって大幅な性能向上が報告され、注目を集めるようになりました [1-3]。機械翻訳、自動要約、キャプション生成など幅広いテキスト生成タスクにおいて有効性が報告されています [4]。
MBR Decodingとは?
MBR decodingとはどんな探索アルゴリズムなのでしょうか?シンプルなアルゴリズムなので、まずはMBR decodingの具体的な手順を見ていきましょう。
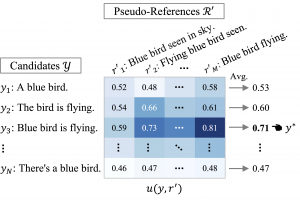
- まず、テキスト生成モデルから複数のテキストをサンプルしておきます。今回扱う機械翻訳タスクでいえば、一つの入力テキストに対して複数の翻訳候補が出力されている状態と考えてください。図の\(Y\)と\(R’\)は、どちらも同じ入力に対してサンプルされたテキスト集合です。†
- 次に、テキストの類似度を測る任意の関数\(u\)を用いて、各テキストペアの類似度を計算します(図のヒートマップ部分)。\(u\)は効用関数と呼ばれ、機械翻訳ではBLEUやCOMETなどが用いられてきました。
- 最後に、\(Y\)のなかで\(R’\)に対して平均して最も類似度が高いテキストを出力\(y^*\)として選択します。
† 実用上は、サンプリングコスト削減のため、YとR’に同じテキスト集合を用いることがあります。なお、Y, R’のいずれにおいてもテキストの重複を許しますが、簡略化のためにテキスト集合と呼ぶことにします。
このようにシンプルなアルゴリズムながら、上述のようにテキスト生成において高い有効性を示すことが知られています。では、なぜこれが有効なのでしょうか?この理由を考えるために、MBR decodingが何を目的としたアルゴリズムであるのかを見ていきます。
MBR Decodingの目的と近似
MBR decodingが本来達成したいことは、式(1)が示すように、人間が作成するような高い品質のテキスト(参照テキスト)の分布\(P_{\mathrm{human}}\) のもとで、参照テキストとの類似度(効用)の期待値を最大にするテキストを見つけ出すことです。翻訳者たちに書いてもらった翻訳に対して平均して最も似ている翻訳候補を選択すると考えてもらえれば、直感的にも良さそうなアルゴリズムに思えるかと思います。
![]()
しかし、肝心の\(P_{\mathrm{human}}\) は通常わかりません。そこで、テキスト生成モデルで推定した分布\(P_{\mathrm{model}}\) からサンプルされたテキスト集合\(R’\)がこれを近似すると仮定することで、以下の式によって近似的に目的を達成することを考えます。
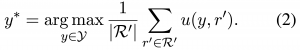
この式(2)が、図で見たMBR decodingのアルゴリズムに一致します。\(R’\)は擬似的に参照テキストとしての役割を果たすことが期待されるので、擬似参照と呼ばれます。この仮定からわかるように、擬似参照はMBR decodingにとって重要な要素となっています。実際、サンプリング手法はMBR decodingの性能を左右することが報告されており、本研究でも詳細な実験でこれを確認しています(論文中の表2を参照ください)。
本研究の貢献:近似と性能の関連を検証
本研究の貢献は、この仮定と性能の関連を実証的に示したことにあります。これまで複数の研究が、MBR decodingにおいて望ましいサンプルの性質について仮説を立ててきました [1, 3, 5]。我々もこれらを参考にサンプルされたテキスト集合の性質について分析を進めていましたが、いずれの仮説も仮定との関係が明確でなく、そもそもMBR decodingの有効性が式(1)にしたがってもたらされているものなのかについて検証が必要であると考えました。
この検証を行うためには、\(R’\)による\(P_{\mathrm{human}}\) の近似の度合いを定量化する必要があります。我々の提案は、この定量化のために、与えられた参照テキストから\(R’\)に対しての異常スコアを用いることです。\(R’\)が\(P_{\mathrm{human}}\) をよく近似していれば、\(P_{\mathrm{human}}\) から得られている参照テキストは\(R’\)からの逸脱が小さいはずと考え、MBR decodingでの性能が高いサンプリング手法ではこの異常スコアが小さくなると仮説を立てました。
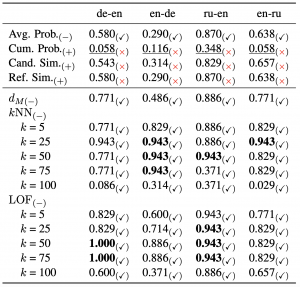
実験では、各サンプリング手法においてMBR decodingの性能と上述の異常スコアを計算し、これらの相関を測りました。詳細は省きますが、4言語ペアの機械翻訳タスクすべてにおいて、異常スコアと性能が期待どおり非常に強い相関を示すことが確認されました(表下段)。また、既存の仮説で重要とされていたサンプルの性質では性能との相関が弱く、既存の仮説では性能変動を説明するのに不十分であることも示されました(表上段)。
おわりに
本研究では、MBR decodingがおく重要な仮定と性能との関連を検証しました。今後の方向性としては、参照テキストが逸脱しないテキスト集合が望ましいという観点から、MBR decodingのためにより効率的なサンプリング手法を探索することなどが考えられます。弊社では、今回の研究に続き、MBR decoding関連でRLチーム陣内を中心に多数の研究成果を発表しているほか [6-9]、テキスト生成に関連する幅広い研究を行っています。毎年、博士課程の学生を対象にリサーチインターンシップを募集していますので、興味を持たれた方はぜひお声がけください。
参考文献
[1] Is MAP Decoding All You Need? The Inadequacy of the Mode in Neural Machine Translation (Eikema & Aziz, COLING 2020)
[2] Quality-Aware Decoding for Neural Machine Translation (Fernandes et al., NAACL 2022)
[3] High Quality Rather than High Model Probability: Minimum Bayes Risk Decoding with Neural Metrics (Freitag et al., TACL 2022)
[4] Follow the Wisdom of the Crowd: Effective Text Generation via Minimum Bayes Risk Decoding (Suzgun et al., Findings of ACL 2023)
[5] Sampling-Based Approximations to Minimum Bayes Risk Decoding for Neural Machine Translation (Eikema & Aziz, EMNLP 2022)
[6] Model-Based Minimum Bayes Risk Decoding (Jinnai et al., ICML 2024)
[7] Hyperparameter-Free Approach for Faster Minimum Bayes Risk Decoding (Jinnai & Ariu, Findings of ACL 2024)
[8] Generating Diverse and High-Quality Texts by Minimum Bayes Risk Decoding (Jinnai et al., Findings of ACL 2024)
[9] Annotation-Efficient Preference Optimization for Language Model Alignment (Jinnai & Honda, arxiv preprint)
Author