Blog
AI Hub から Kubeflow Fairing を使ってタイタニック生存予測サービスを立ててみる @ Google Cloud Next’19参加レポ
アドベリフィケーション事業の井上です。
サンフランシスコで開催された Google Cloud Next’19 に参加してきました。
今回はなんと122以上にのぼる発表がありました。
Google CloudのChief Marketing OfficerであるAlison Wagonfeld氏 が 公式ブログにまとめてくださっています。
原文: News to build on: 122+ announcements from Google Cloud Next ‘19
日本語訳: Google Cloud Next ’19 で行った 122 の発表
新機能の概要はこちらの公式ブログをご覧になって頂くのが良いかと思いますので、私の方では気になったセッション及び機能をご紹介させて頂こうと思います。
AI Platform , AI Hub , Kubeflow Pipelines , Kubeflow Fairing は何がどう違うのか
2日目のキーノートで AI Platform(beta) の紹介がありました。
ML系の諸々を一つのインターフェイスで統合的に扱うサービスです。
この他にも AIと機械学習に関する新機能の発表は多く、Google さんが大変 AI に力を入れていることが伺いしれます。
しかし、AI Platform と AI Hub は立ち位置がどう違うのか? Kubeflow Pipelines と Kubeflow Fairing は何が違うのか? が、キーノートを聞いただけではわからなかったので(私の英語力の問題かもしれませんが…)、 下記のセッションを聞きに行ってきました。
AI Hub: The One Place for Everything AI (Cloud Next ’19)
このセッションでは、AI系サービスのユース・ケースが述べられ、「このユーザ・ロールだとこんな使い方できますよ」的なデモが行われました。
AI系サービスのユース・ケースと代表的なユーザ・ロールをまとめると下記図の感じになります。

私の疑問だった、 AI Platform と AI Hub , Kubeflow Pipelines と Kubeflow Fairing の使い分けや違いは、AI Platform のページに良い説明図が掲載されています。

(https://cloud.google.com/ai-platform/?hl=ja より掲載)
特に AI Platform , AI Hub , Kubeflow Pipelines , Kubeflow Fairing についてまとめると こんな感じでしょうか。
- AI Platform : AIサービスの統合実行環境。ここから AI Hub や Kubeflow を実行したり、ダッシュボードでサマリーを閲覧したりする(workbench≒まさに土台)
- AI Hub: JupyterLabのラッパーと言ったらよいのかな。
- Kubeflow Pipelines: ETL や モデルの訓練, デプロイなどの一連のMLをプロダクションとして扱う上で必要なパイプラインをパッケージ化して可搬性を提供するツール
- Kubeflow Fairing: モデルをコンテナ化したり、 Kubeflow クラスタにデプロイする PythonのSDK。Jupyter Notebook から 実行できる。
実際にどれだけ便利かを体感するために、これらを使って Kaggle の有名な課題セットである タイタニック 号乗客の生存予測 について、モデルの訓練から〜サービスのデプロイまでやってみたいと思います。
AI Hub から Kubeflow Fairing を使って タイタニック号乗客生存予測サービスを立てる
1. 下準備
Kaggle からデータ をダウンロードして、 GCS に入れておきます。
私は gs://inoue-next19/titanic に入れました。
2. XGBoost × Kubeflow Fairing notebookを起動する
AI Platform から AI Hub を開きます。
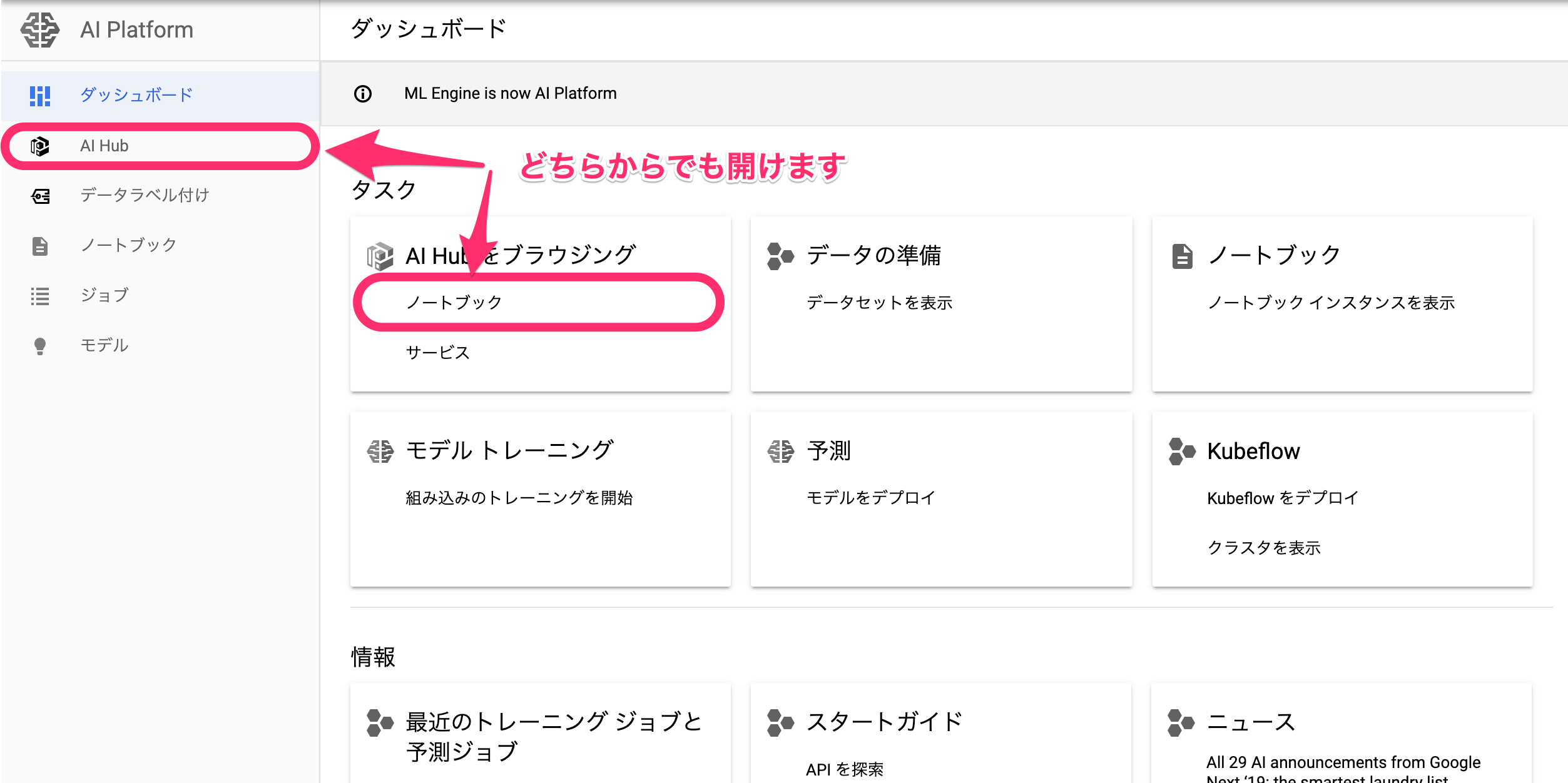
次に AI Hub で、サンプルnotebookを探します。
参考になるコードをここで探せるのはすごく便利です。
今回は XGBoost を使って生死を予測しようと思いますので、 xgboost でフィルタリングして探しました。
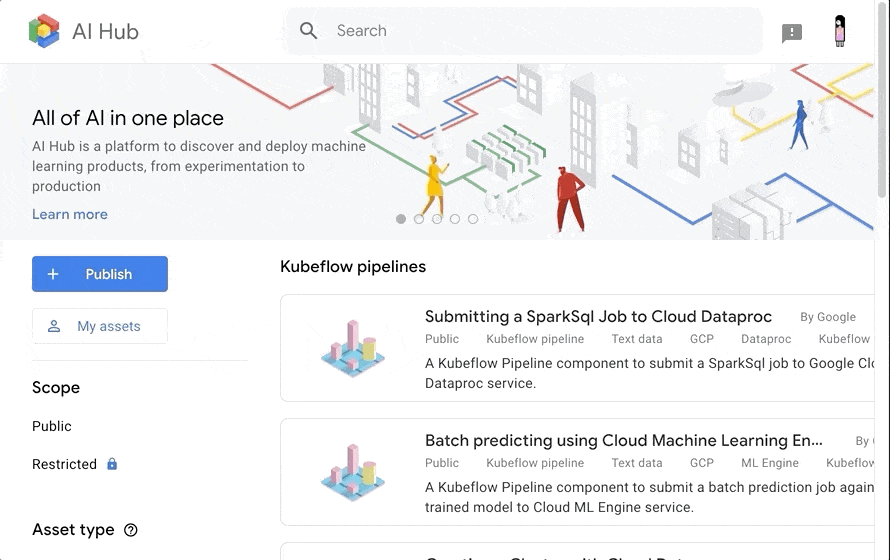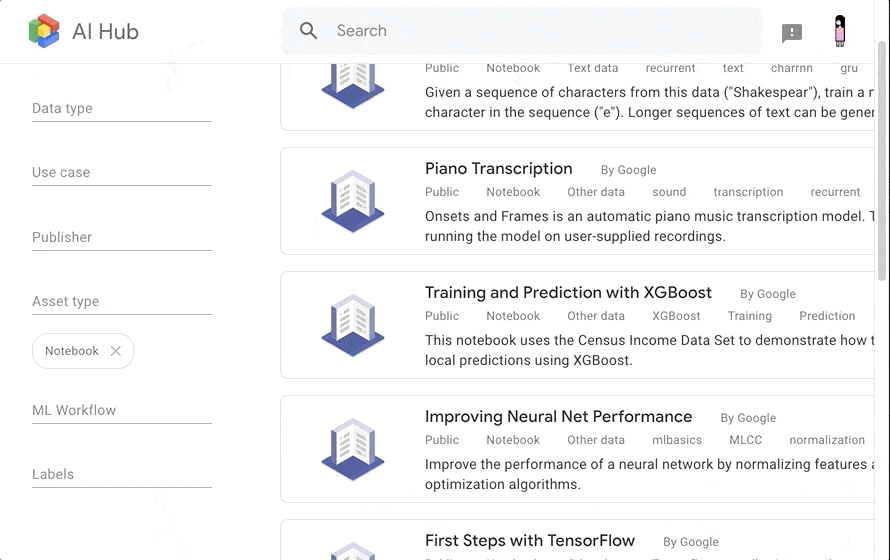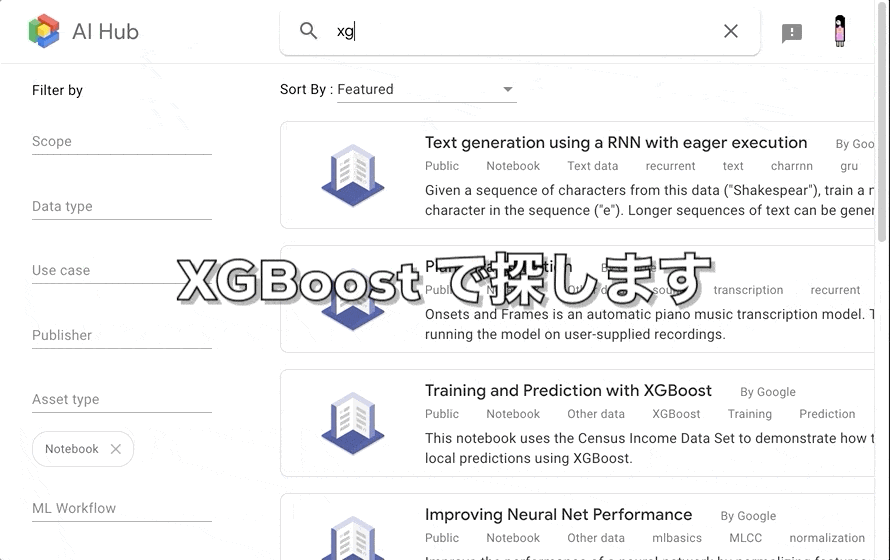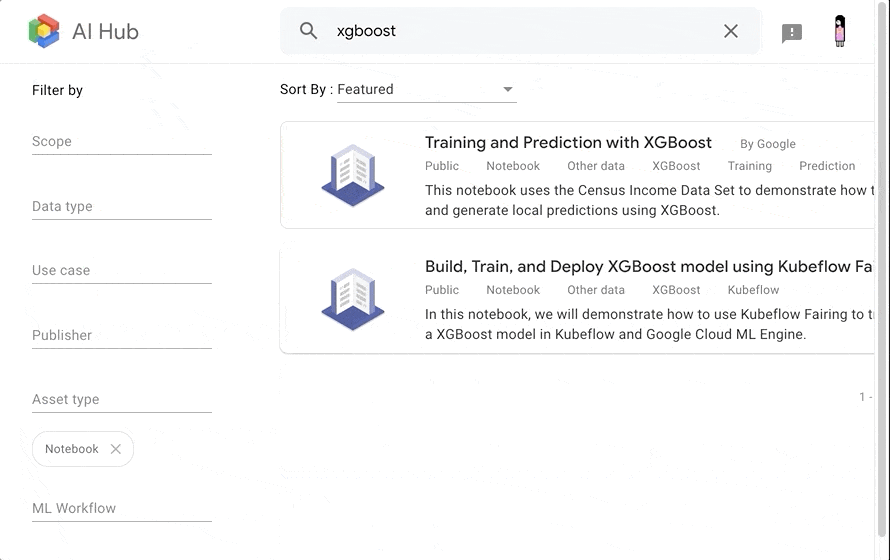
Kubeflow Fairing を使って、モデルの訓練〜デプロイまでを行う notebook がありますので、こちらを使っていきます。
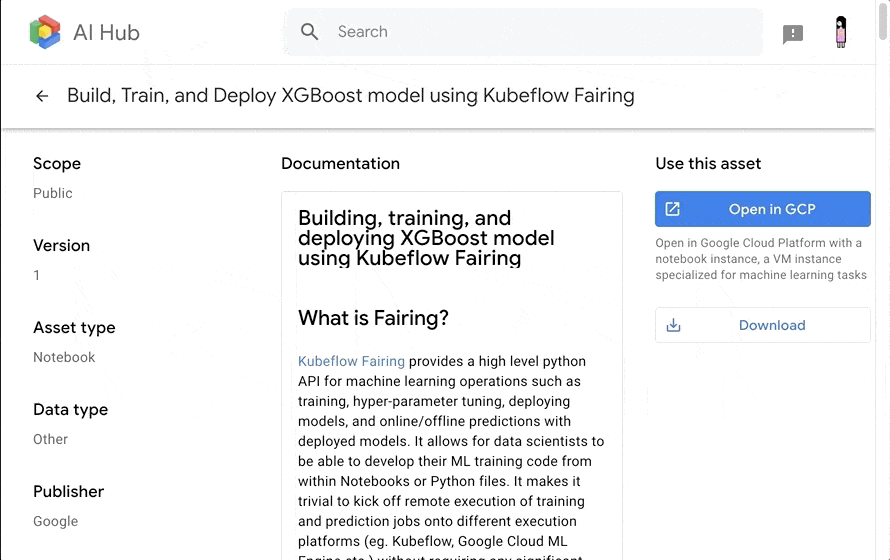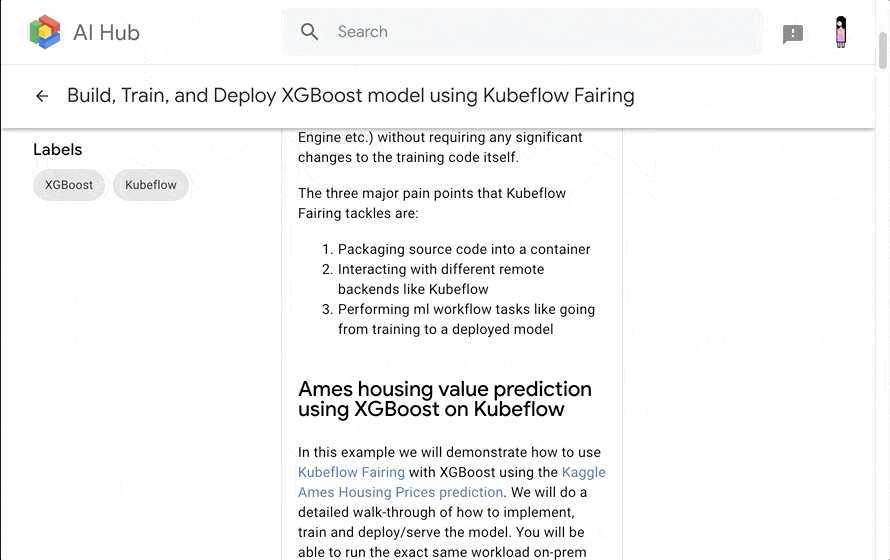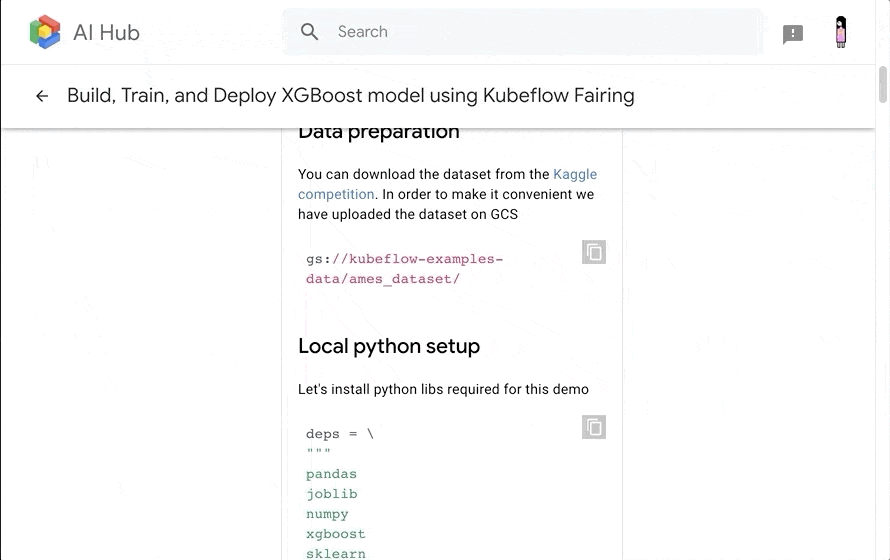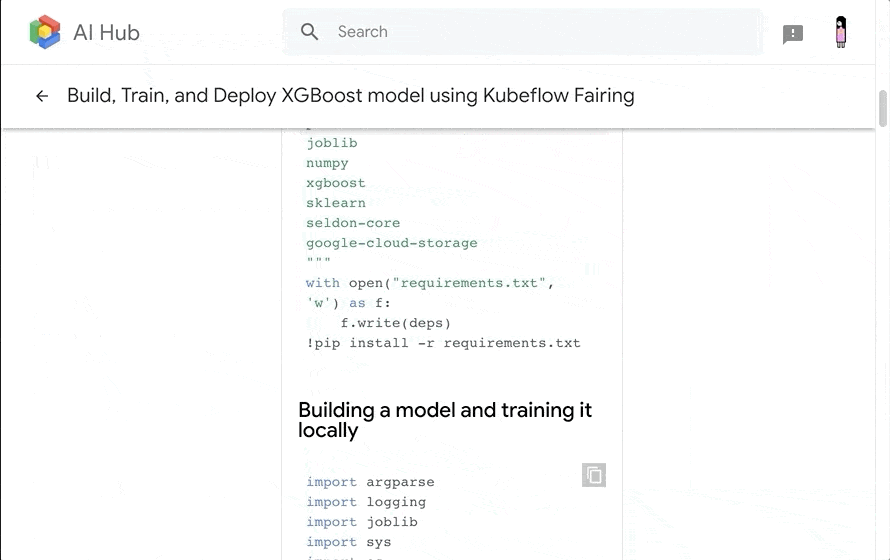
右上の Open in GCP をタップすると AI Platform に戻るので、ここで JupyterLab 駆動インスタンスの設定を行います。
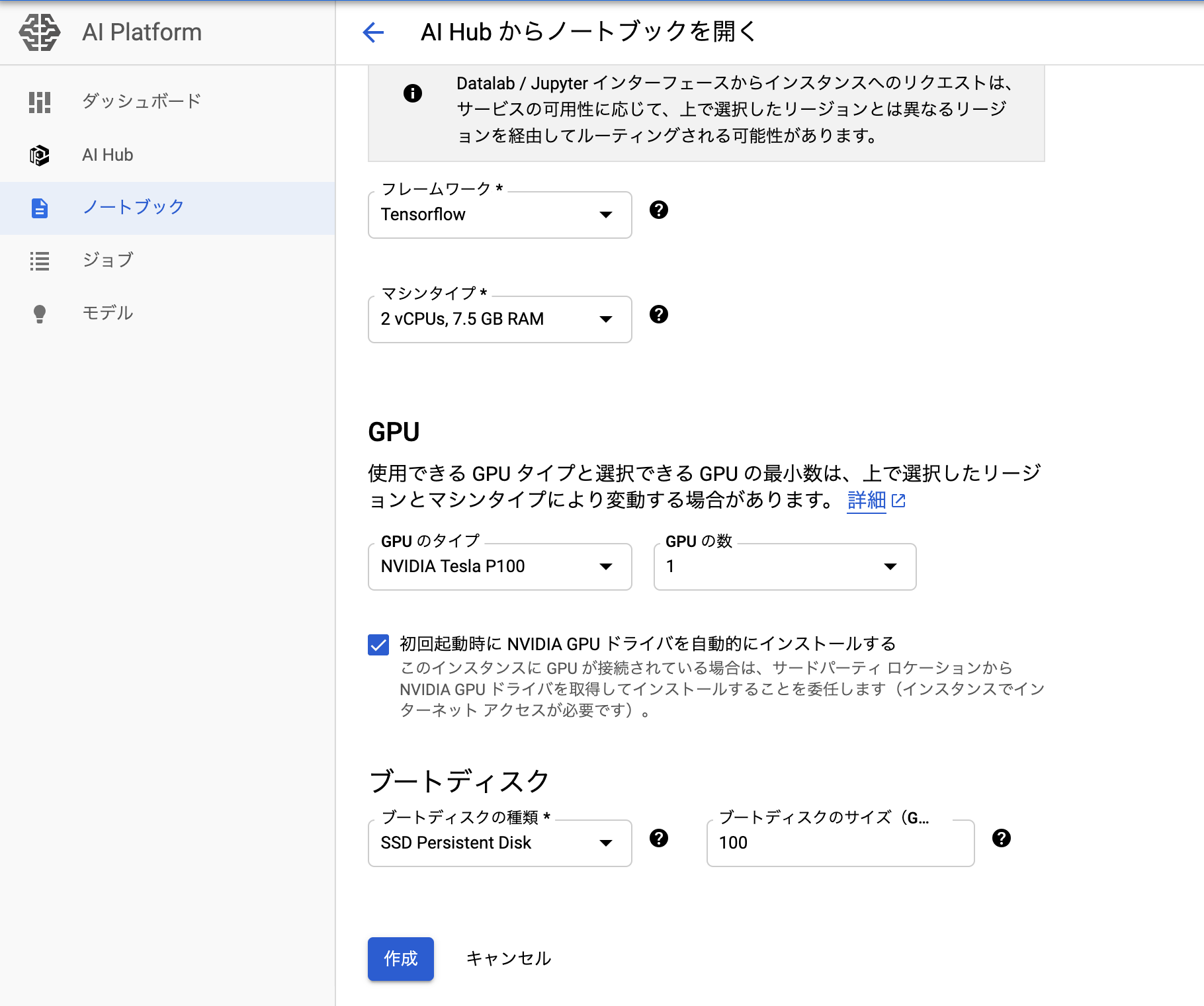
インスタンスの作成を行うと JupyterLab が起動します。サンプル notebook のコピーが作成されています。
3. タイタニック号乗客生存データの訓練を行う
サンプルの notebook を改造して、タイタニック号生存予測モデルを作成します。
ここでの注意点としては
- カーネルは Python3 を選択すること
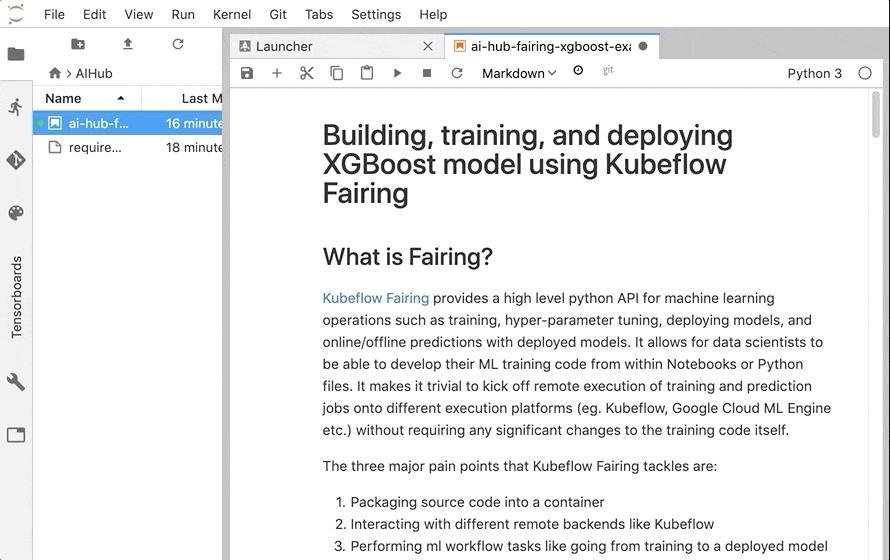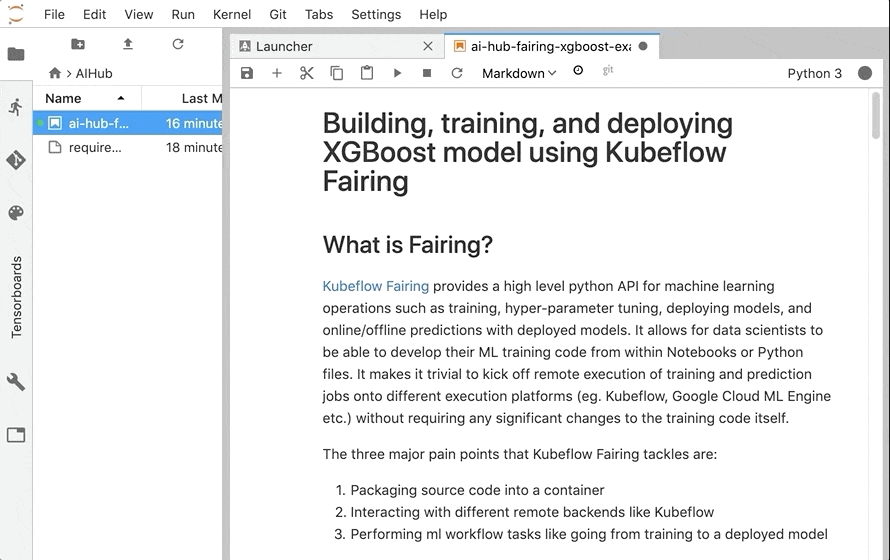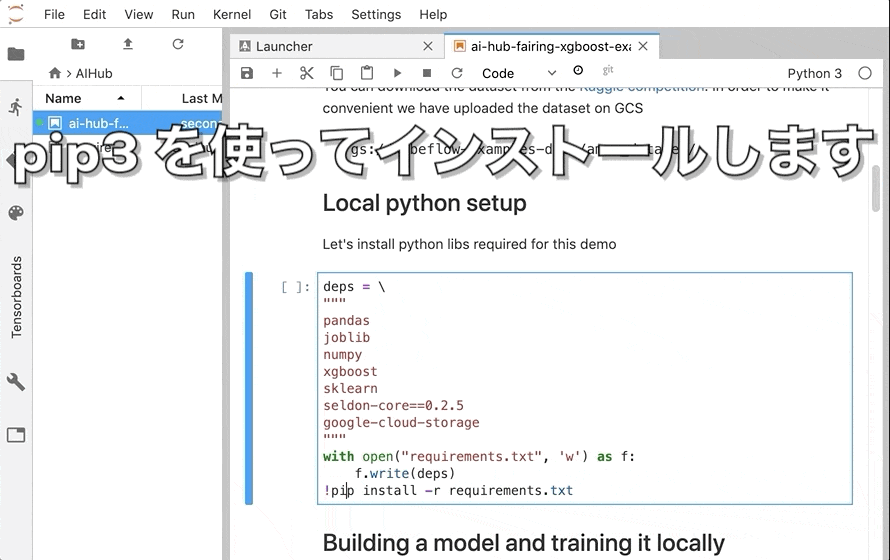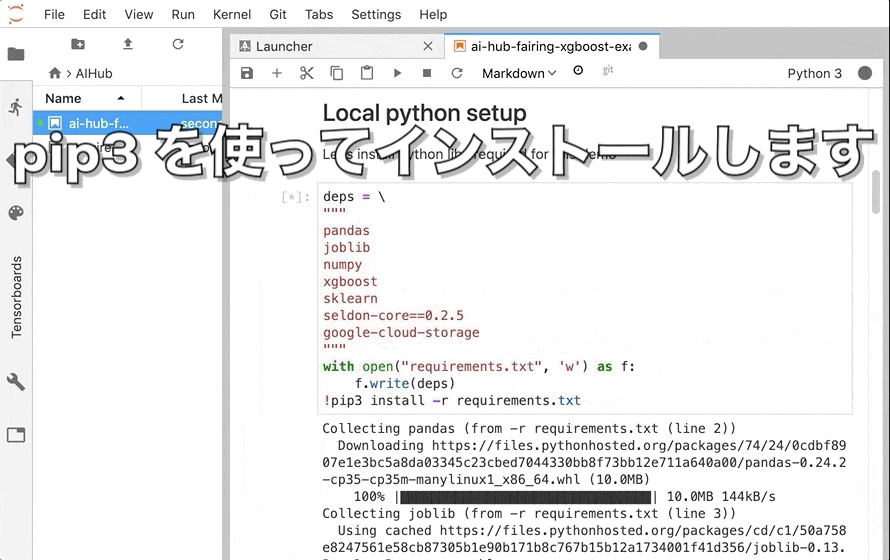
- 依存パッケージの install には
pip3を使うこと seldon-coreの 最新版は Python 3.6 で導入されたシンタックスを使っているが、カーネルは Python3.5系のため、 バージョンを0.2.5に縛ってインストールする必要があることurllib3も1.21.1縛りが必要。(コンフリクトする)- サンプル・ノートは XGBRegressor を使っているが(
価格を予測しているので)、XGBClassifier を使うこと - JupyterLab に プリ・インストールされている
fairingはバージョンが古く、0.0.3が入っている
でしょうか。
※ 追記:
現在のインスタンスでは !pip3 install --upgrade "urllib3==1.21.1" "fairing==0.5.2" をやらないとまともに動かなそうでした💦
次に from xgboost import XGBRegressor としている部分もfrom xgboost import XGBClassifier に変更します。
※ import の次々セルでは、 gsutil の存在チェックを行っているのですが、 gsutild と間違っているので gsutil に修正が必要です。
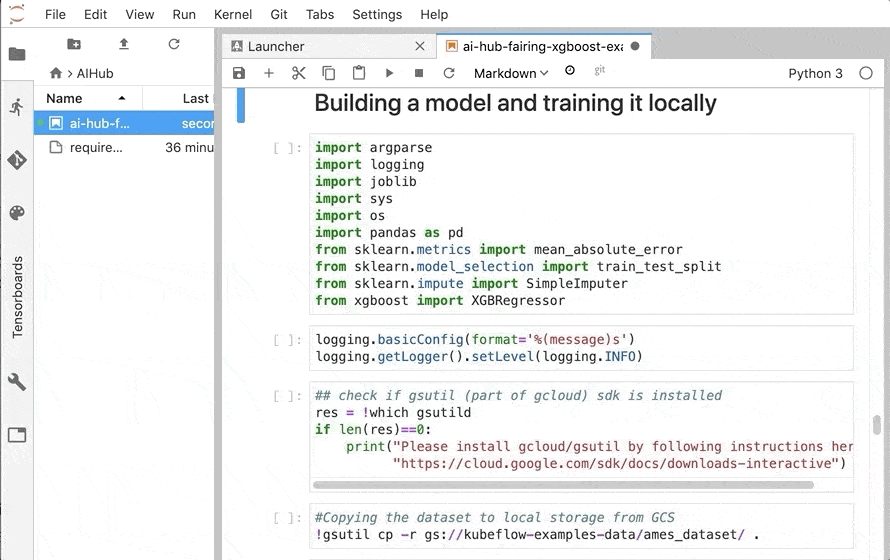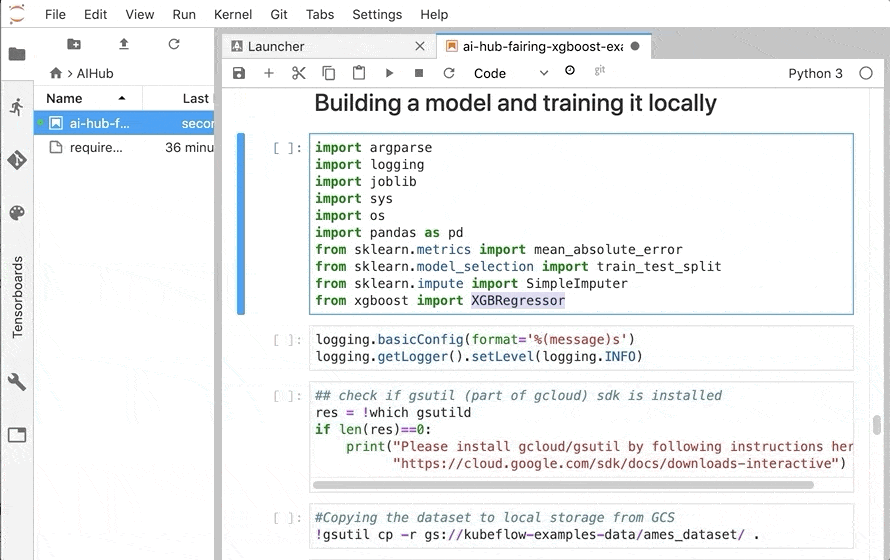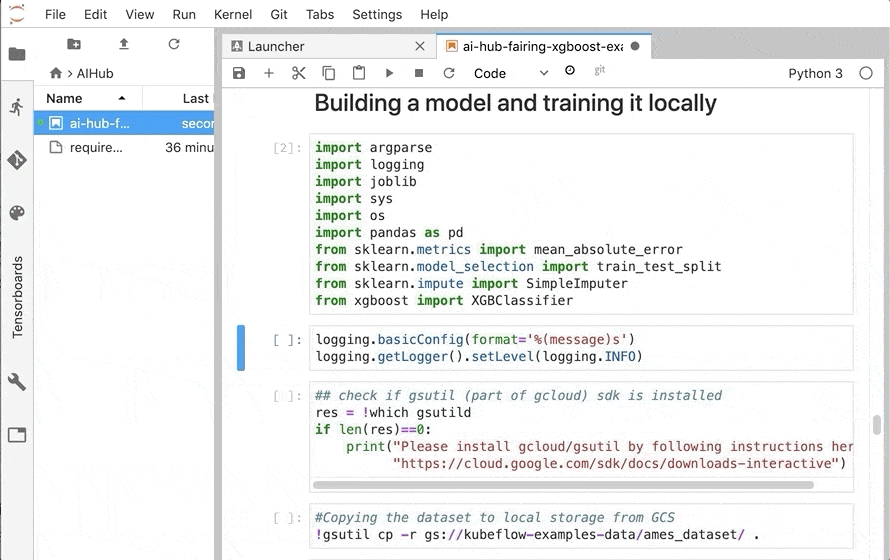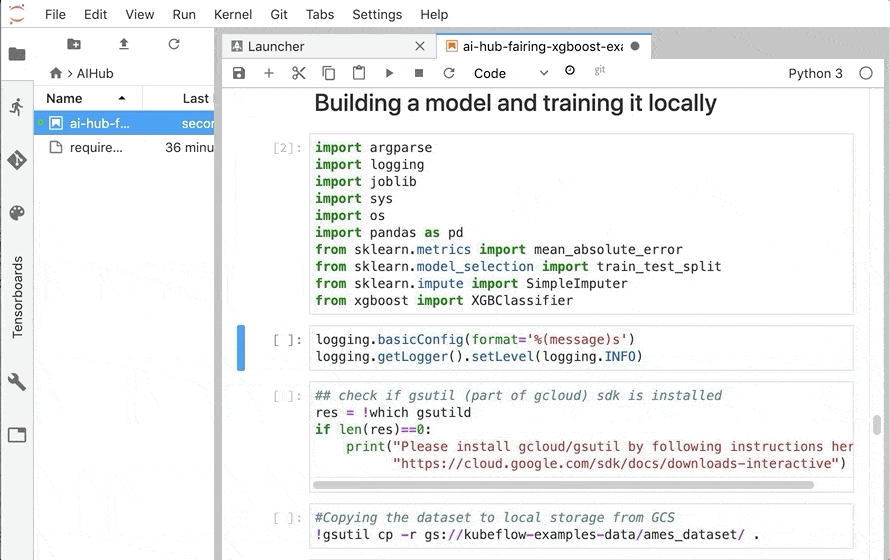
次に、 Kaggle からダウンロードしたタイタニック乗客生存データ を JupyterLab 上に持ってきます。
gsutil の操作も notebook 上でできてしまうので非常に楽です。

タイタニック号乗客生存データを読み込みます。

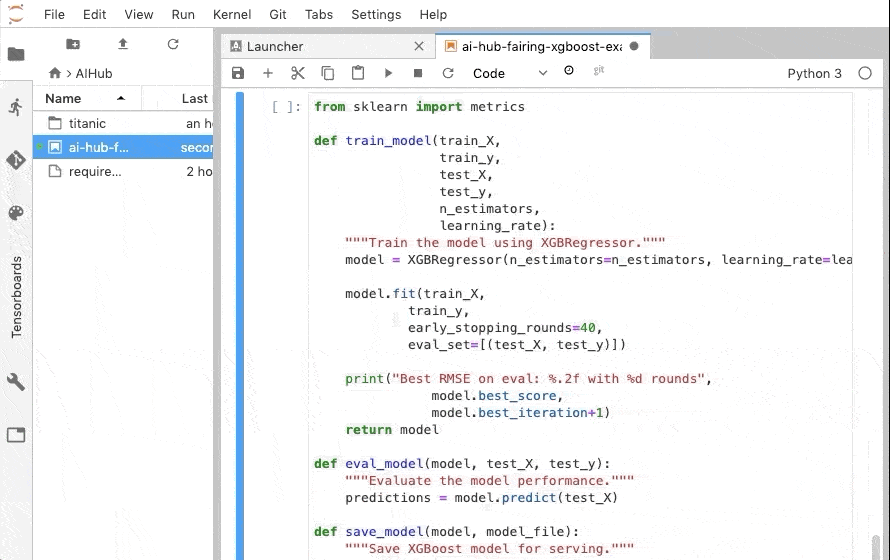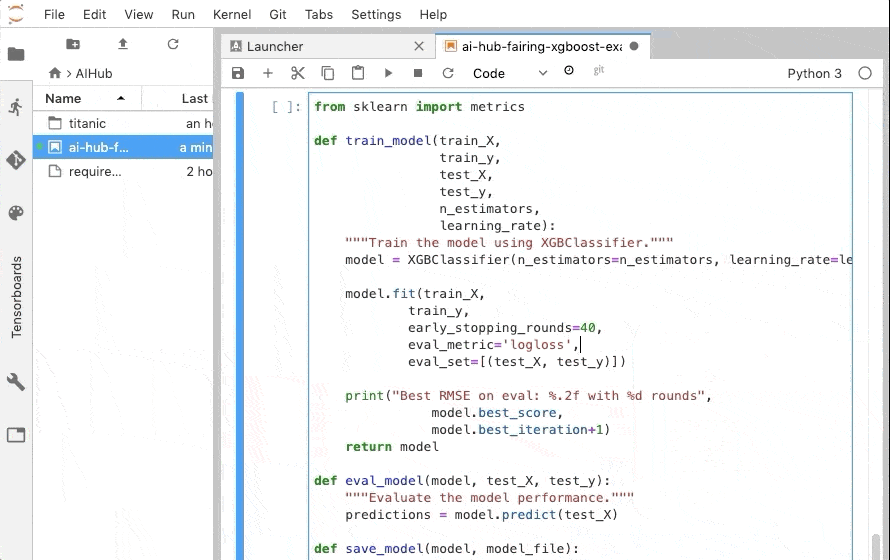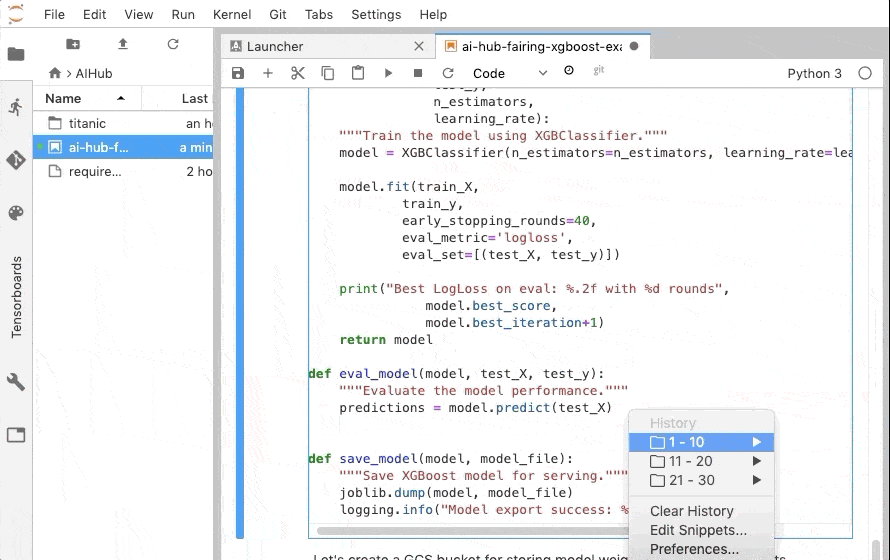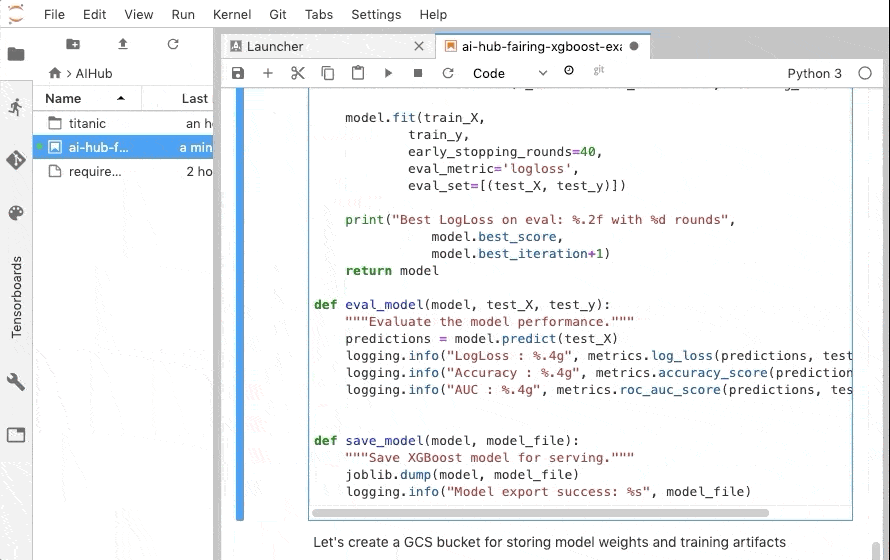
モデルの訓練と評価の箇所は下記のように変更しました。
XGBRegressor を XGBClassifier に変更し、評価メトリックを LogLoss にしています。
※ ↑ eval_model で出力している LogLoss が間違っています。正しくは、 model.predicr_proba(test_X) の戻り値を渡す必要があります💦(@YusukeKaneko ご指摘ありがとう…🙇)
さて、次はいよいよ モデルの訓練を行います。
HousingServe を TitanicServe に変更して train を実行します。
|
1 2 3 4 |
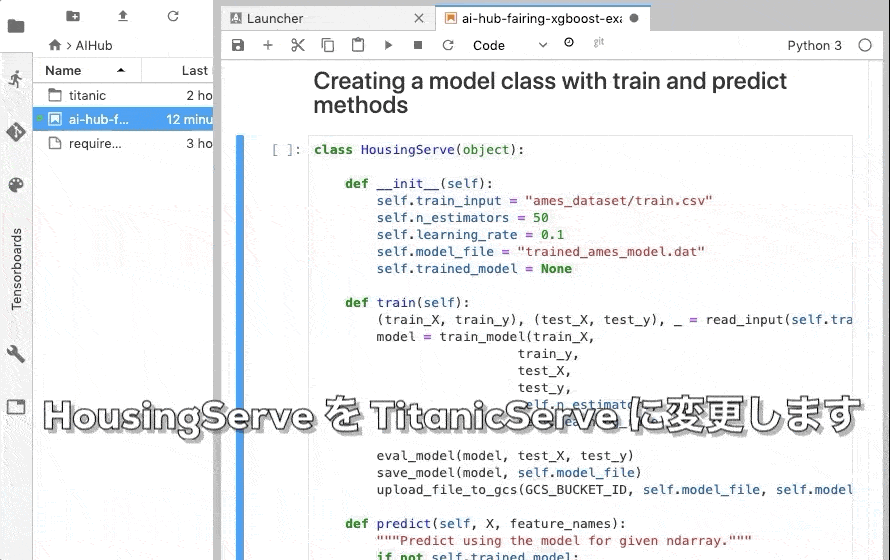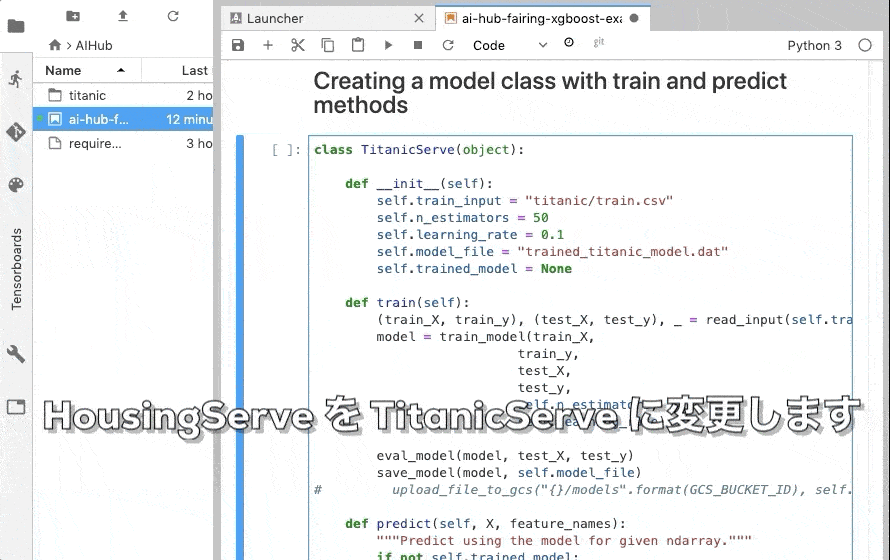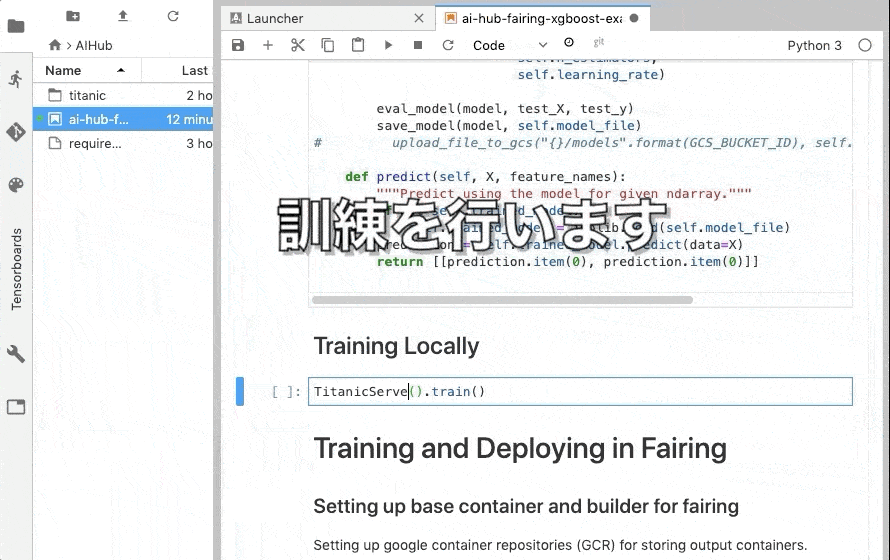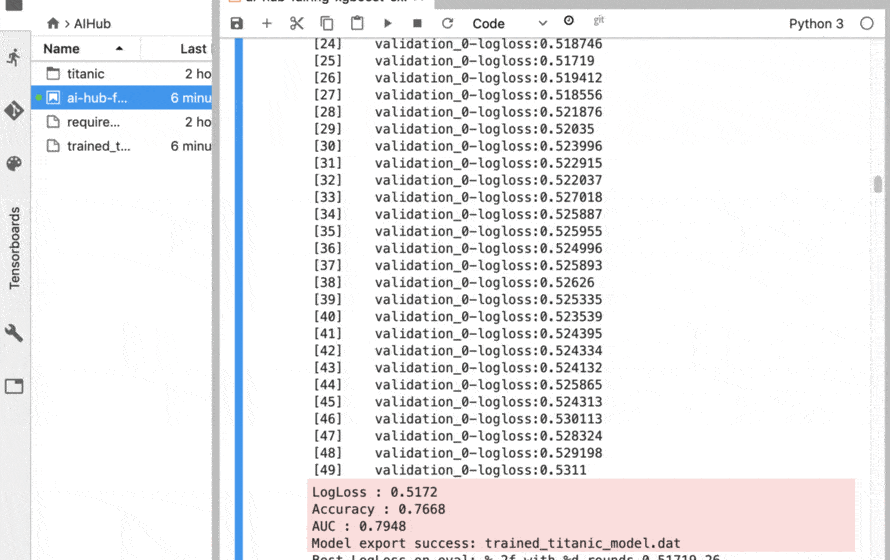
LogLoss : 0.5179 Accuracy : 0.7668 AUC : 0.7948 Model export success: trained_titanic_model.dat |
↑の結果となりました。
4. fairing で notebook を実行可能なコンテナ化する
ここからは本命の fairing が大活躍します。
今作成した TitanicServe を GCP 上で訓練します。
まずは、カーネルで使用している Python のバージョンを指定して fairing に ベース・コンテナを設定します。

ここで、 notebook に Kubeflow クラスタを構築するよう記載があるので、Kubeflow クラスタを構築 しておきます。
この記事では Kubeflow クラスタ の構築は割愛しますが、 kfctl を使ってこちらの手順通り行えば、簡単にKubeflow クラスタが立ち上がります。(時間はかかりますが…)
サンプル・パイプラインもデフォルトで用意されています。
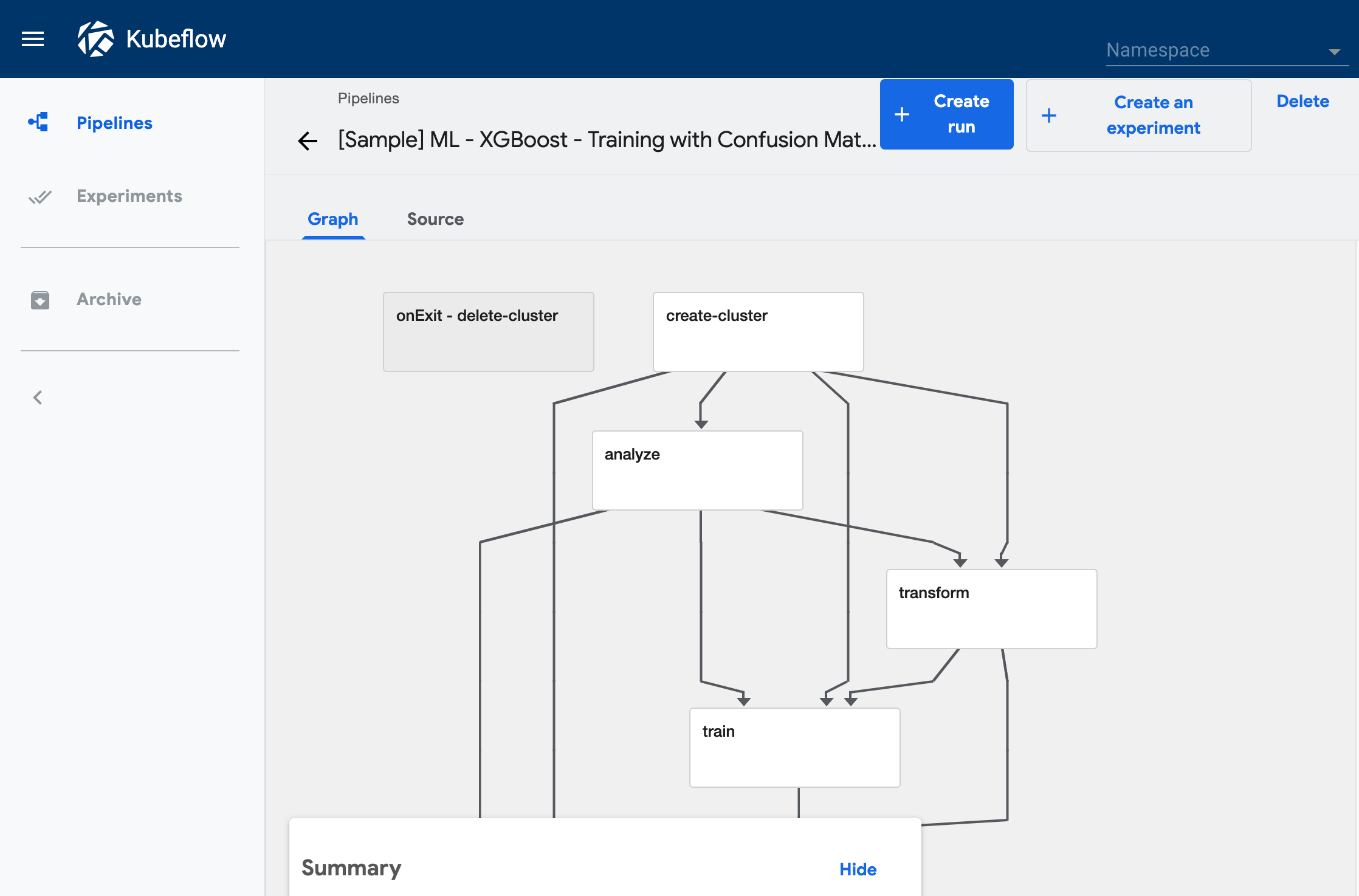
私は titanic-serve という名前でクラスタを作成しました。
サンプル notebook には記載がないですが、 JupyterLab 上でこのクラスタのクレデンシャルを取得する必要があるので、セルを追加します。

これで、 fairing で訓練〜デプロイする準備ができましたので、 TitanicServe を GCP 上で訓練します。

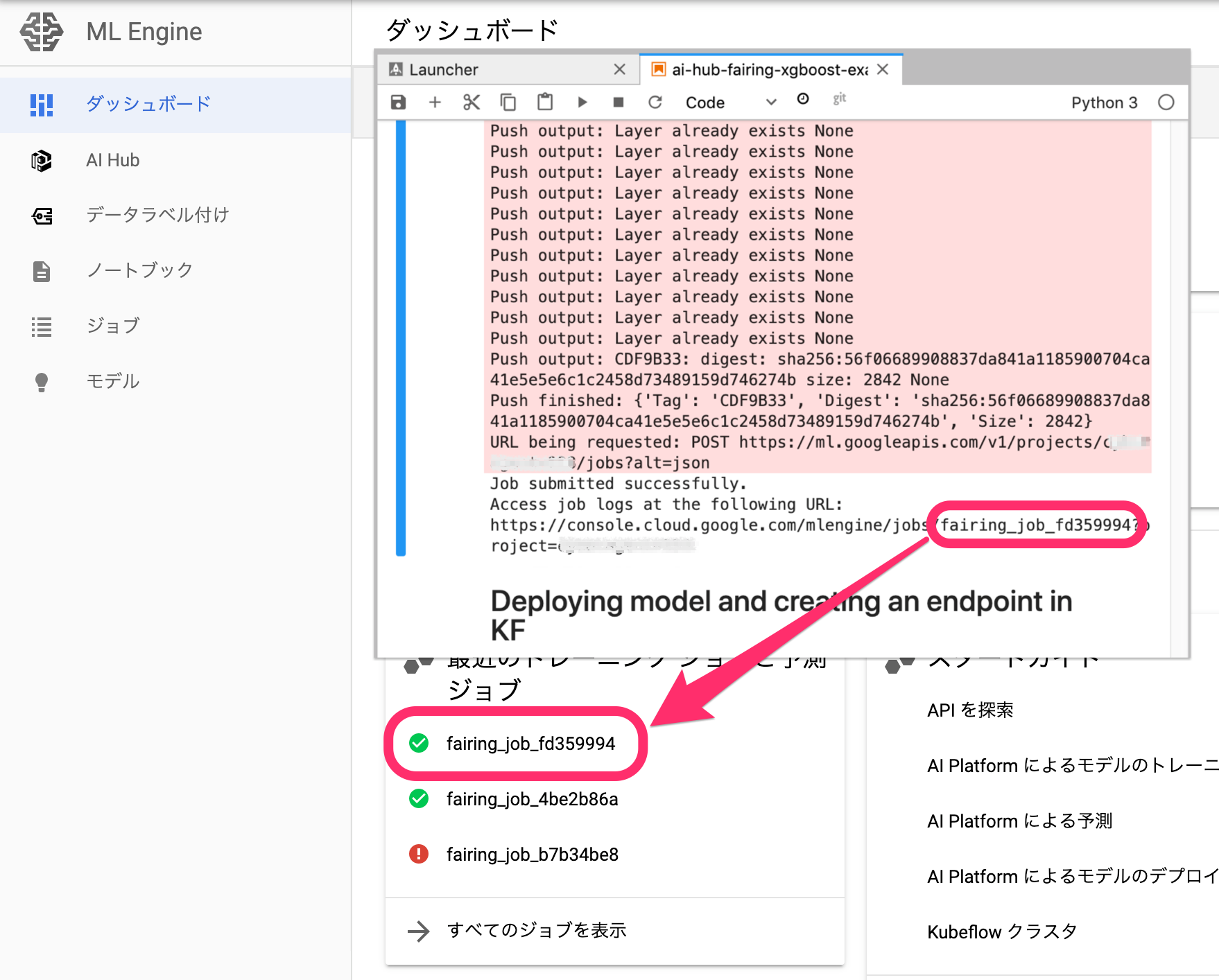
訓練を行う function をコンテナ化し、GCR に push して Kubeflow で実行するところまで、 fairing が行ってくれます。
これはすごいですね。
AI Platform のダッシュボードを開くと、訓練済みモデルとして表示されます。
5. serving で サービス化する
fairing を使うと、notebook 上で訓練したモデルを Kubeflowクラスタの serving にサービスとしてデプロイすることもできちゃいます。
作成した TitanicServe と、 書き出した訓練済みモデルを指定して fairing を実行します。
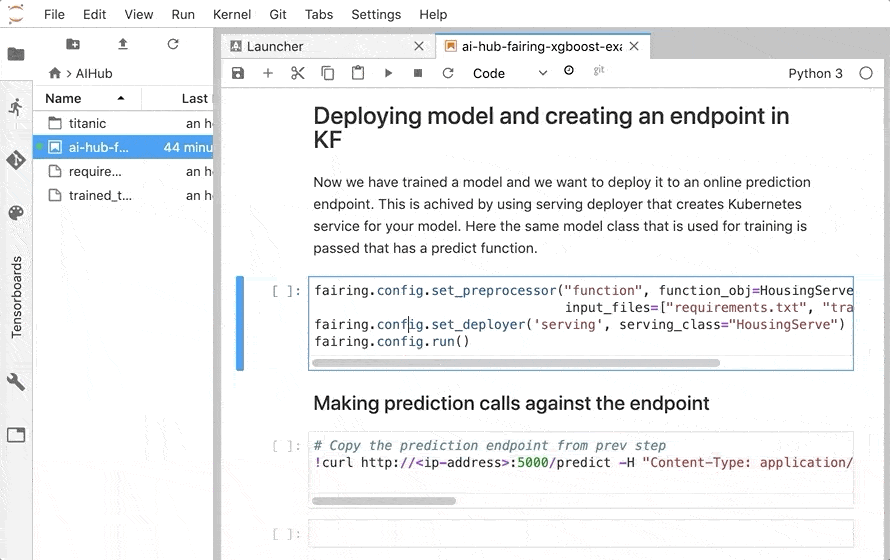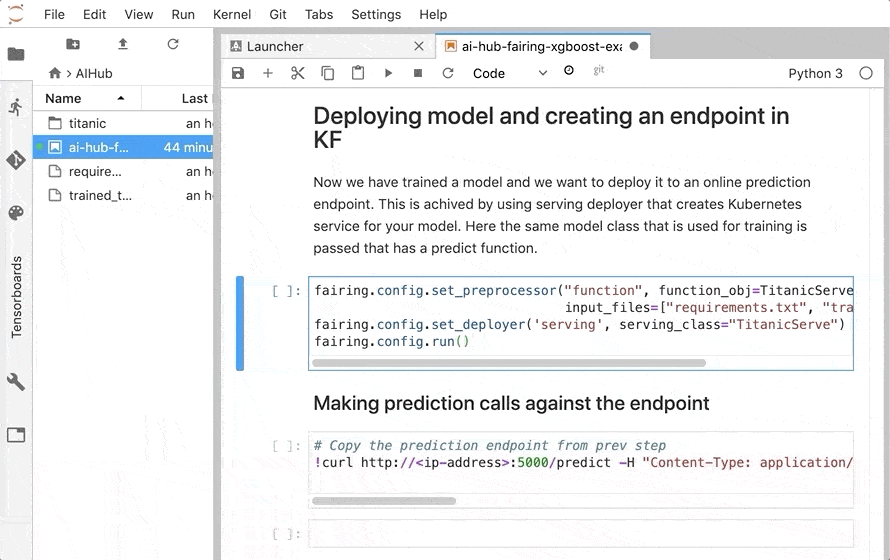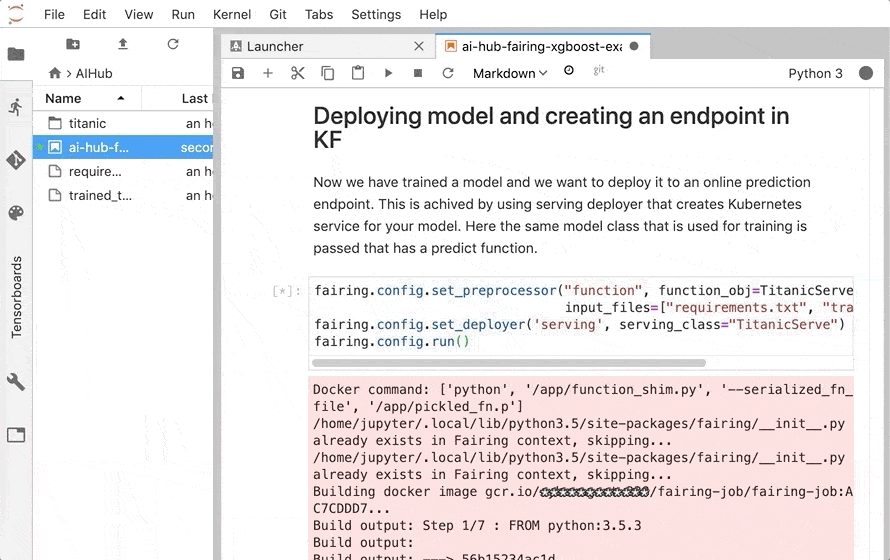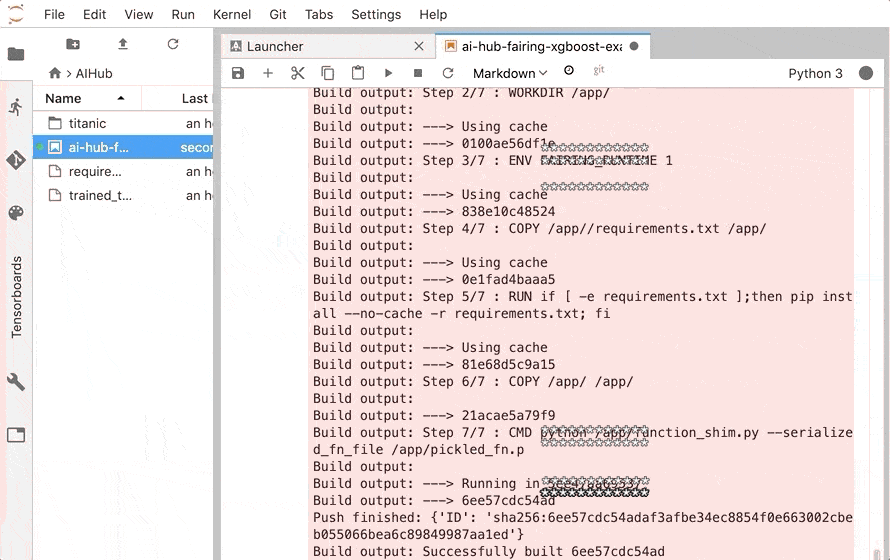
Kubeflow クラスタに デプロイされ、 エンドポイントが公開されます。
notebook にアウトプットとして出力された エンドポイントに、 train.csv の 一行を POST してみます。

結果が返ってきました。
まだ少し開発途上感のある AI Hub と Kubeflow Fairing ですが、 Google さんの掲げる AI の民主化 を体現するようなコンポーネントで、今後の期待大だと思いました。
その他、個人的に気になったのは
- BigQuery の UI から Dataflow SQL を実行し、 Pub/Sub と BigQuery をストリーミング JOINする機能
- Visual Studio Code の エクステンションである Cloud Code
- Docker コンテナをサーバーレスで実行できる Cloud Run
- BigQuery BI エンジン
あたりでしょうか。
機会があったらこれらの記事書きたいところです。
それでは最後までお読み頂きありがとうございました。
Author