Blog
Speech Gesture Generation 研究紹介 〜声から動きを作り出す〜
こんにちは。AILabの馬場です。
この記事は、CyberAgent Developers Advent Calendar 2019 11日目の記事です。
前日は、kitoko552 さんの NestedScrollViewを使ってSticky TabBarを実現する という記事でした。
この記事では、深層学習の登場で少しホットになってきたので、興味を持って調べていた “Speech Gesture Generation”(音声からジェスチャー動作を生成する技術)の研究について、個人的な整理も兼ねて、昔の手法と最近の手法を紹介してみます。
Speech Gesture Generation とは
Speech Gesture Generation は、人が話す音声からその人のジェスチャー動作を推定・生成するタスクです。人が話す声から、話の内容やイントネーションなどとの整合性のあるジェスチャーを自動で生成することを目指しています。
 (Learning Individual Styles of Conversational Gesture より引用)
(Learning Individual Styles of Conversational Gesture より引用)
例えば VTuber や遠隔操作ロボットなど、中に人がいるタイプのエージェントは、中の人の動きをそのままエージェントの動きとしてマッピングすることが多いですが、中の人の負担が大きかったり、意図していない動きが反映されてしまったり、動きの計測誤差によって滑らかでないガタガタした動きになったりと、嬉しくないことがよく起こります。また、自律的に動くコミュニケーションロボットやバーチャルエージェントに関しても、その動きを人手でゼロから作成する手間は計り知れませんし、自然な動きにするにはパラメータが多すぎて制御しきれないという課題もあります。
そういった背景もあり、ここ数年の CV や HCI、VR などの国際会議で相次いでモデルの提案がされています。
古き良きルールベースジェスチャー生成
人手で全部設計するの大変とか抜かしておいてアレですが、1994年あたりでは J. Cassell さんたちがルールベースジェスチャー生成をゴリゴリに設計しています。
1. ANIMATED CONVERSATION:Rule-based Generation of Facial Expression, Gesture, Spoken Intonation for Multiple Conversational Agents
2. BEAT: the Behavior Expression Animation Toolkit
3. Nudge Nudge Wink Wink: Elements of face-to-face conversation for embodied conversational agents
彼らは、2体のエージェントの会話において、その会話内容とイントネーションからエージェントの顔の表情、ジェスチャーを決定するまでのルールを設計しています。(ここではジェスチャーに絞って紹介)
論文 1 では、銀行での会話の一幕を例に、会話中に現れるジェスチャーを次の4種類に分類しています。
- Iconics(映像的): 指示対象の形態,動作,位置関係などを再現しようとするジェスチャー
- 例:両手の親指と人指し指で長方形を作って「小切手」を表す動き
- Metaphorics(暗喩的): 抽象的な内容を空間上に視覚化しようとするジェスチャー
- 例:動物の口のような形をさせた手を、体側に引いてくる動きで「(お金を)引き出す」
- Dietics(直示的): 指差しジェスチャー
- 例:地面を指差しながら「”この”銀行」
- Beats(拍子): 発話の音に合わせて、指や手で拍子をとるようなジェスチャー
これらの代表的なジェスチャーを下記のルールで会話中の単語にアノテートしていきます。(ここでは少し簡略化して紹介します)
- Iconics/Metaphorics ジェスチャーは、会話中に初めて出てきた、または、聞き手が初めて聞く単語に対してつける
- 会話中の各単語の意味を分類し、該当するジェスチャーを対応づける(論文内ではたぶん手動
- 例1)有形で具体的な物を表す単語には Iconics ジェスチャー
- 例2)抽象的な物を表す単語には Metaphorics ジェスチャー

すべての会話にジェスチャーが対応づいたら、次はジェスチャーとイントネーションとのタイミングを合わせていきます。
- 会話テキストをTTS(Text-To-Speech)に入れて出てきた音声から、音調句(一続きに発音されるまとまり)に含まれるジェスチャーをすべて収集する
- 代表的なジェスチャーが含まれていれば、そのジェスチャーが音調句の最初もしくは前から始まり、次のジェスチャーか核強勢アクセント(一番強いアクセント)のどちらか先にくる方の前に終わるように設定する
- 核強勢アクセントに一致するようにジェスチャーのストローク動作を設定する
- ストロークが終わるか最後のBeatsジェスチャー終わるとすぐに、リラクゼーション(停止動作?)を設定し、リラクゼーションの終わりは音調句の終わりあたりになるように設定する
やってることは当たり前といえばそうなんですが、単語とジェスチャーの対応づけと、ジェスチャーと音声イントネーションの対応づけを、ルールとして丁寧に整理整頓(?)されている印象で、まずはルールでジェスチャー作っていきたい人にとってはとても参考になる情報だと思います。
(ただ、実際の論文にはさらにもう少し詳細な条件やルールが記載されてるので、参考にされる方は元論文をしっかりとお読みください。)
会話内容があらかじめわかっていて、単語の意味が正確に分類できていて、単語ごとのジェスチャーをあらかじめ作成しておけば、設計次第でワークするかもな?という印象。このジェスチャーについて評価している記述を見つけられなかったので、ほんとにこれでちゃんと動くのか試してみたい。
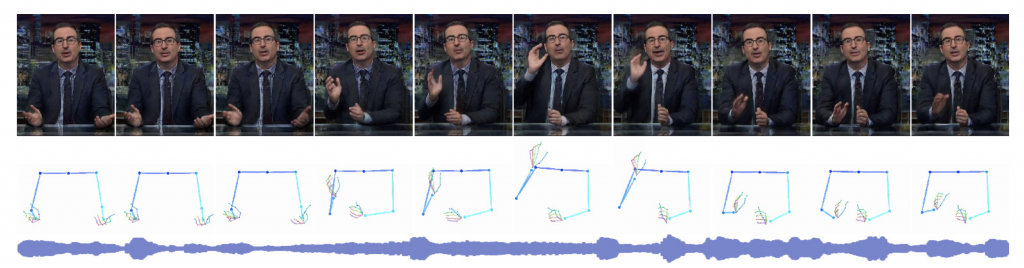
CVPR2019: Learning Individual Styles of Conversational Gesture
(論文より引用)
先ほどのルールベースの時代から月日は過ぎて2019年。それまでの間に HMM や Restricted Boltzmann Machines 、Bi-LSTM など様々なモデルを使って、音声からジェスチャー生成手法が報告されてきましたが、つい先日CVPR2019に採択された論文が話題になっていました。
動画を見る限り、音声から見事にジェスチャーを予測できているように見えます。さらにGANで映像生成まで行なっているのはすごいですね。ただ、論文のメインはあくまで Speech から Pose(骨格)のシーケンスを推定する部分です。特にこの論文では、話者特有のジェスチャーを学習することを目的にしています。
提案手法では、音声をスペクトログラム画像に変換し、その画像から 2 次元の Pose を予測しています。その予測には、U-Net と呼ばれる、画像から画像を生成する畳み込みネットワークベースのエンコーダーデコーダーモデルを用いていて、さらに、そのモデルをGeneratorとしてGANの枠組みを取り入れ、平均的な位置に予測が収束するのを防ごうとしています。
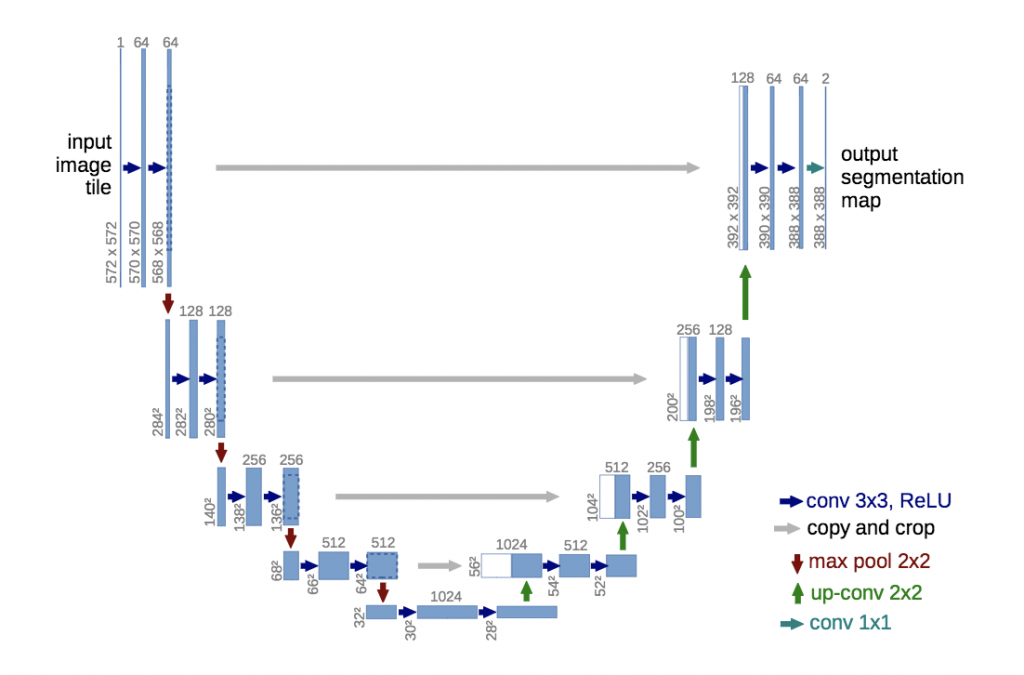
(U-Net アーキテクチャ:U-Net 論文より引用)
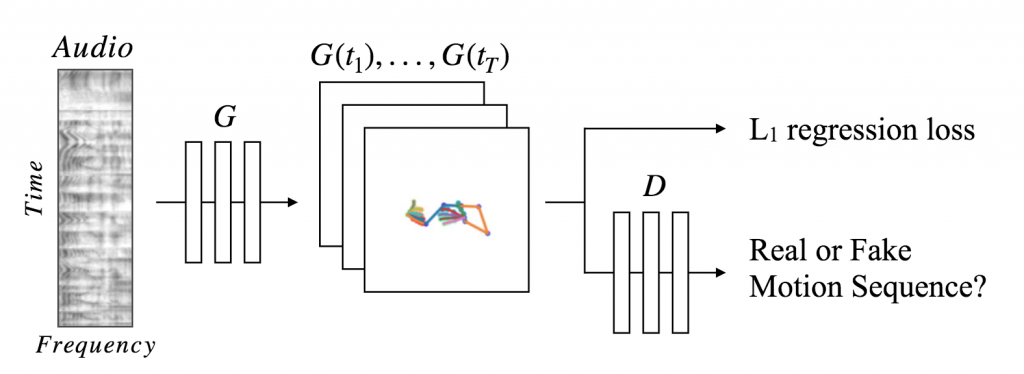 (提案モデル)
(提案モデル)
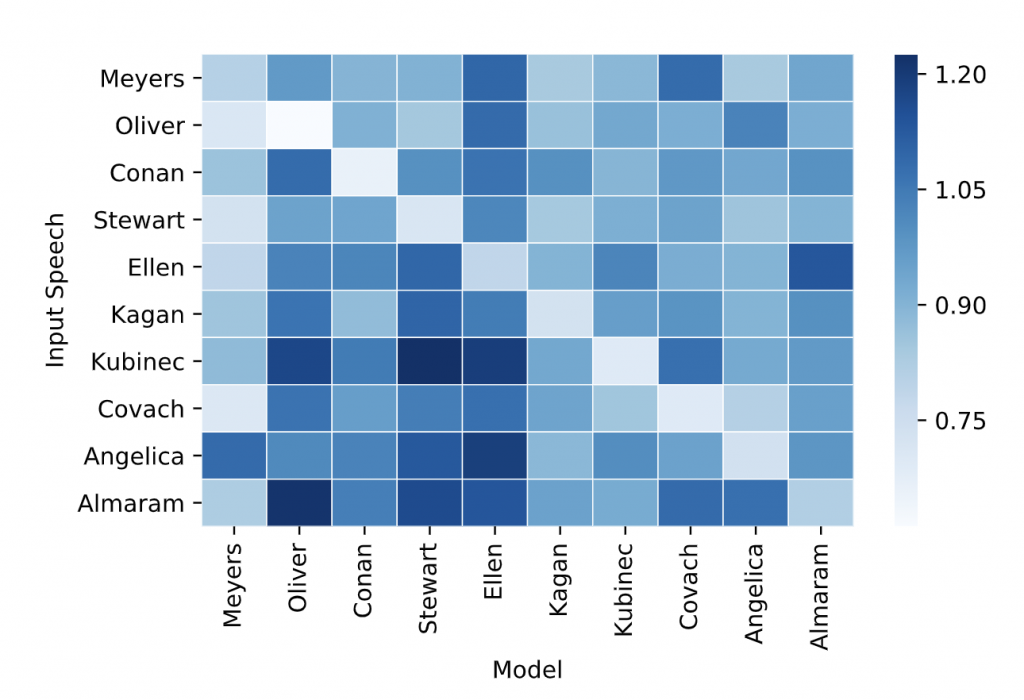
定量的な評価として、ランダム選択(同じ話者の別のシーンを無作為に選択)や NearestNeighbor、 RNN ベースのモデルより予測誤差(L1 Loss)が低く、骨格点の推定精度(PCK)も最も高いことを示しています。また、下図のように、各話者のテストデータに、他の話者で学習したモデルを適用したスコアも比較しています。対角成分、つまり、ある話者で学習したモデルはその話者に対して最も精度が高い(色が薄い)ことから、話者ごとの特徴を学習できているとしています。
さらに、感性的にも評価しています。4秒か12秒の入力音声とともに、実際の骨格と生成した骨格のシーケンス(動画)を同時に被験者に見せ、音声と一致している方を選ぶという評価方法を300名の被験者で行なっています。また、音声はダイナミックな動きが多い話者(Oliver)と比較的動きの少ない話者(Meyers)を対象としています。その結果が下図です。
提案手法よりもランダムやNNの方が評価が高いのが面白いですね。筆者曰く、そもそもジェスチャーがレストポジション(休止位置)にあることが多いため、別シーンの本物ジェスチャーを持ってくるランダムやNNは、認知的に説得力があるとのこと。なので、平均位置への収束を防いだGANあり提案手法は、ダイナミック話者(Oliver)において高い評価を得ています。
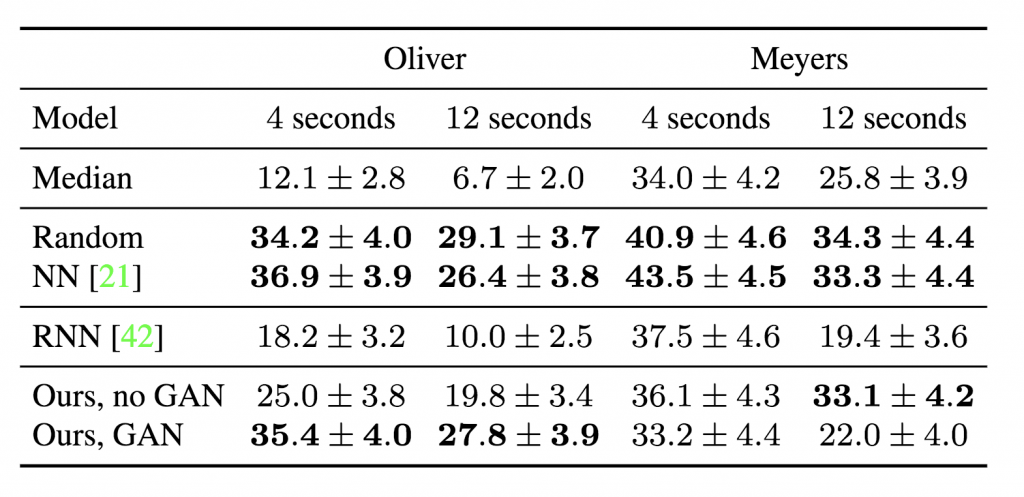 (Human Studyの結果。数値は被験者が騙された時間のパーセンテージ)
(Human Studyの結果。数値は被験者が騙された時間のパーセンテージ)
個人的には、音声データを扱うのでRNNが真っ先に候補に上がりそうなところですが、音声データをスペクトログラム画像にしてからCNNベースのモデルで学習させるのも効果がありそうだと知れたので、業務で研究している遠隔操作ロボットの動作生成に取り入れていきたいなと考えています。
### おわりに
今回は、古き良きベーシックなルールベースなジェスチャー生成モデルと、深層学習を用いたインパクトのあるジェスチャー生成モデルを紹介しました。もちろん、これら以外にも、同じく深層学習(こちらはRNN)を用いた手法 [K. Takeuchi, HAI2017], [Y. Ferstl, IVA2018] 、映像ではなくロボットの動作へ転用している論文 [Y. Yoon, ICRA2019]、などたくさんの研究者が興味深い結果を出していますので、気が向けばそれらもまとめて載せたいと思います。おわり。
Author