Blog
IJCAI-ECAI-2018 で発表してきました
こんにちは、AI Lab の馬場です。
理化学研究所の前原さんとの共同研究が IJCAI-ECAI-2018 に採択されたので、研究に携わったメンバー +α で7月16-19日に開催された本会議に参加してきました。その様子をレポートしたいと思います。
IJCAI-ECAI-2018
「IJCAI(国際人工知能会議)」は、世界中の様々な人工知能分野の研究者が一堂に集い毎年開催される国際会議で、「NIPS」「ICML」「KDD」「AAAI」などと並んで、人工知能分野で権威ある国際会議の1つです。2018年は「ECAI(欧州人工知能学会)」と共同開催となっています。
また、今年から初めて Federated AI Meeting(FAIM)として「IJCAI」「ICML」「AAMAS」「ICCBR」「SoCS」の5つの会議が同じ会場で同時期に開催されました。ある会議のチケットで他の会議が聴講可能になったりするとてもお得な(?)取り組みとなっており、スケジュールの後半で開催されたIJCAI本会議ではICMLやAAMASから参加されている方が多くいらっしゃいました。
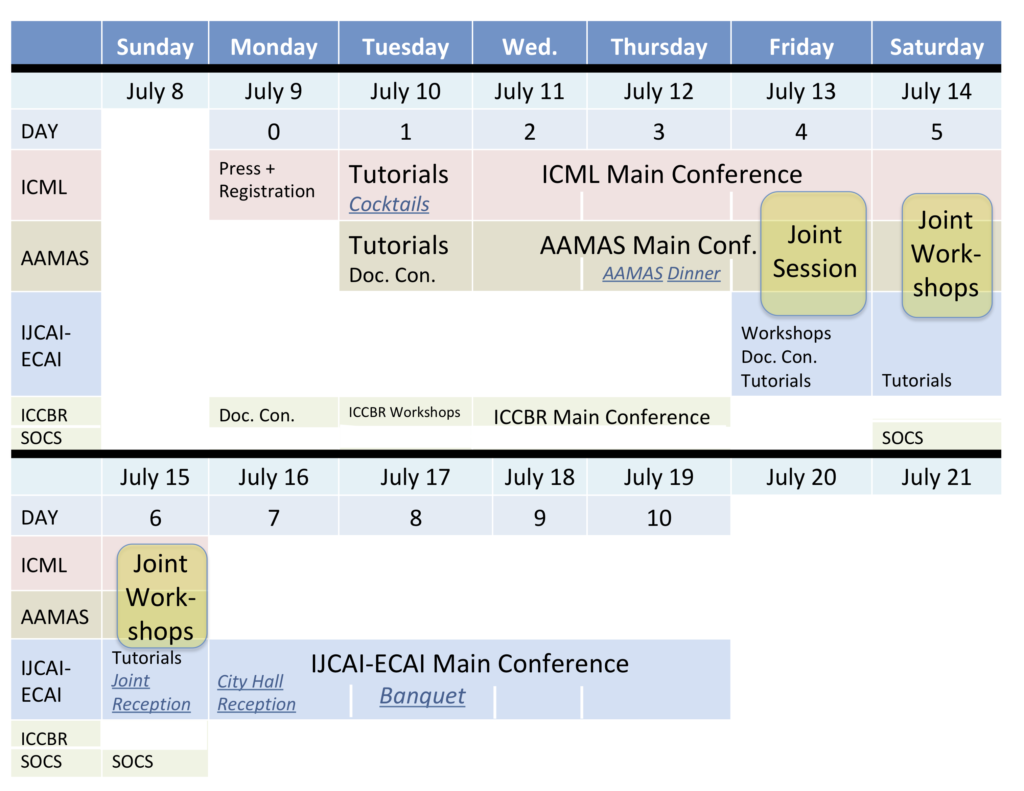
(FAIM 全体のスケジュール:https://icml.cc/Conferences/2018/FAIMticket より引用)
会場は Stockholmsmassan という会場で、まるでコミケ会場のような非常に大きな施設でした。IJCAIでは9セッションが並列で開かれており、企業の展示やポスター発表なども日中ずっと開催されていて、とてもたくさんの人が行き来していましたが、まだまだ部屋が余っていて驚きました。周辺は静かで穏やかな雰囲気で、電車で数駅いくとすぐに市街地に出られるとてもカンファレンスに適した会場でした。

( http://www.stockholmsmassan.se/ より引用)
カンファレンスの最初に行われるOpeningにて、採択率などの数字が紹介されました。前年比37%増の3470本もの論文が投稿され、採択率は20.5%で採択本数は710本。いよいよ採択率20%を切りそうな勢いです。参加登録は2500名で前年比20%増。IJCAIは非常に幅広い領域のトピックを扱ってますし、これからもまだまだ増えそうに思えます。

論文投稿数の推移がこちら。つい3年前(2015年)と比較しても約1.5倍に増えています。

採択率と国ごとの割合がこちら。採択率は21%(20.5%)で年々下がってきているように感じます。また、採択論文の国別割合はダントツで中国が1位で46%。次いで、EU、USA。日本は17本で2.4%で、ドイツやイタリアとほぼ同じ数でした。頑張らねば。

そして、研究領域ごとの採択率がこちらです。スライドだと採択率がわかりにくいので表にしてみました。機械学習手法の論文投稿数が最多で1808本。機械学習の応用と合わせると全体の43%を占めています。次いで、Computer Vision、Multi-Agent Systems。こうしてみると、同時開催されている ICML や AAMAS と同じような研究領域の投稿が多いことがわかります。
| 研究領域 | 投稿数 | 採択数 | 採択率 |
| Machine Learning | 1808 | 356 | 0.1969 |
| Computer Vision | 613 | 131 | 0.2137 |
| Machine Learning Application | 609 | 122 | 0.2003 |
| Multi-Agent Systems | 498 | 100 | 0.2008 |
| Natural Language Processing | 480 | 102 | 0.2125 |
| Knowledge Representation | 412 | 81 | 0.1966 |
| Humans and AI | 260 | 38 | 0.1462 |
| Planning and Scheduling | 235 | 44 | 0.1872 |
| Search and Game Playing | 190 | 42 | 0.2211 |
| Uncertainty in AI | 188 | 41 | 0.2181 |
| Constraints and Satisfiability | 162 | 41 | 0.2531 |
| Robotics | 136 | 25 | 0.1838 |
共同研究論文:「ブランディング広告のための最適入札戦略」
本会議の初日に、採択された共同研究論文「Optimal Bidding Strategy for Brand Advertising(ブランディング広告のための最適入札戦略)」を前原さんに発表していただきました。

本論文では、インプレッションのたびにオークションが開催され、オークション勝者に広告表示権が与えられるリアルタイム入札において、ブランディング広告の効率的な配信手法を提案しています。心理学者のヘルマン・エビングハウスによって導かれた、人間の脳の「忘れる仕組み」を表した「エビングハウスの忘却曲線」を利用し、ユーザーのブランド認知率を最大化するオンライン最適化アルゴリズムを提案しました。これにより、「新規ユーザーには積極的に配信する」「すでに十分認知度が高いユーザーには広告配信を抑える」などといった配信の制御ができるようになり、リアルタイム入札の「ユーザーごとに細かい配信を行える」という強みを活かすことで、より効率的なブランディング広告施策が見込めます。
また、当日に発表された論文のポスター展示が常に行われており、なかなか参加者が集まるタイミングが掴めませんでしたが、何名かの研究者と意見を交換することができました。
(ポスター発表で意見を交換する様子)

(論文の著者メンバーで記念撮影)
聴講した研究発表のレポートたち
参加したメンバーが聴講した研究発表のうち、面白かったものや印象に残ったものをいくつかご紹介します。
Translations as Additional Contexts for Sentence Classification
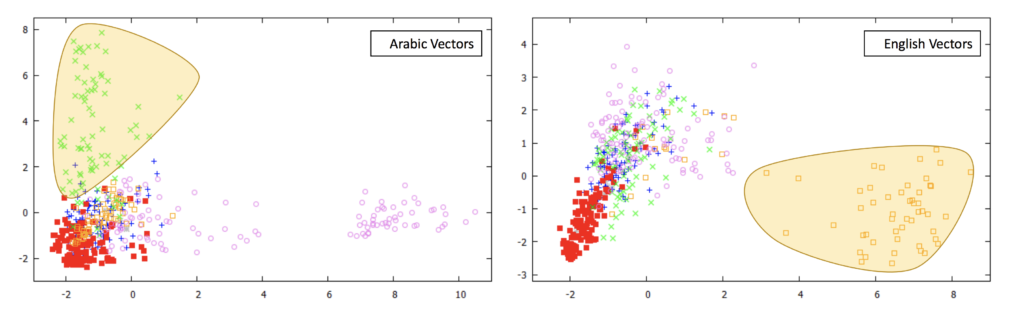
ある文章を複数の異なる言語で訳して文章のベクトル表現を獲得することで、文章分類の精度向上を実現した論文です。図のように、同じ文章たちをアラビア語と英語でそれぞれ翻訳して文章ベクトルを得ると、片方の言語ではうまく表現できてないクラスの文章がもう片方の言語では非常に偏ったベクトルを持っています。翻訳精度が高い場合には、複数の言語で獲得した文章ベクトルを単純に入力として連結する手法でもうまくいくようですが、本論文では精度が低い場合にもうまく分類できる Multiple Context Fixing Attachment(MCFA)というアテンションベースの手法を提案しています。結果を見ると、どの言語がどの文章を分類する際にうまく効くかをアテンションで表現できていて非常に面白かったです。
Teaching Machines to Ask Questions
Question AnsweringタスクはDocumentとQuestionが与えられた際にAnswerを返すタスクですが、この論文では逆にDocumentとAnswerが与えられた際に、それを問うhuman-likeで自然なQuestionを作ろうという新しい発想を採用しています。Seq2seqにGANを組み合わせたモデルで、文章の多様性を表現する潜在変数や、質問のクラス(5W1H)ごとの特徴をとらえるための観測変数なども利用し、自然で多様な文章を生成できることを報告しています。SQuADデータセットを使って評価しており、様々な評価尺度において比較手法よりも高い精度を出していて、人による自然さや流暢さに関する5段階評価でも平均4.1という高いスコアを実現しています。今後、対話システムにおける異なる感情からの発話生成へ応用を計画しているとのこと。
Aspect-Level deep collaborative filtering via heterogeneous information networks
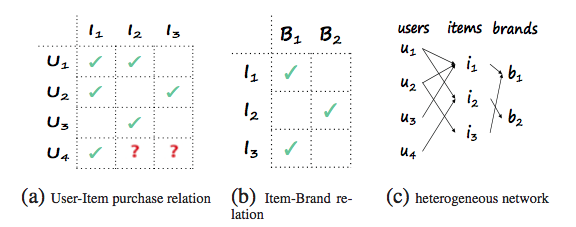
推薦システムで頻繁に使われる協調フィルタリングは、ユーザーとアイテムの関係をモデル化するものですが、一方でアイテムには、例えば映画の場合なら監督や出演者など、より上の階層の情報を利用できる場合があります(図)。これらをこの論文では”アスペクト”と呼び、複数の”アスペクト”を利用することで推薦の質を向上させたり、コールドスタート問題にうまく対処するための”アスペクトレベル協調フィルタリング(NeuACF)”を提案した論文です。
このようなアスペクトが複数あると、例えば映画→ユーザー評価→映画、映画→監督→映画、映画→出演者→映画、など、様々な経路(meta-path)での類似度を考えることができます。これらの類似度行列を全て利用し、予測に効きそうなものをアテンションによって統合するニューラル協調フィルタリングを作ることができきます。
この論文で仮定されている構造は実データにもよくありがちで、アテンションをつかってこれらを統合するのが非常にうまいなあと感じました。実際にいろいろなデータセットでSOTAを達成しているようです。
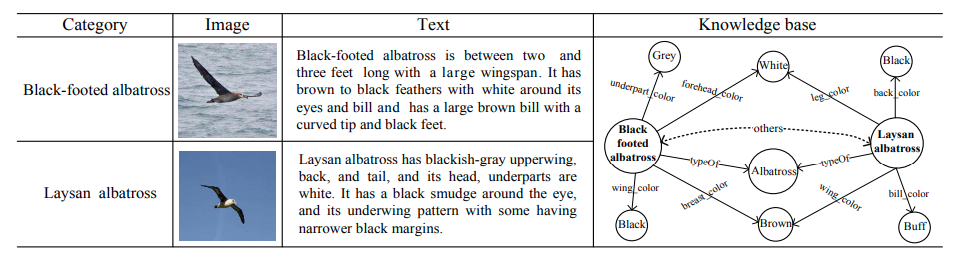
Fine-grained Image Classification by Visual-Semantic Embedding
画像分類において、クラス内のサブクラスを識別する問題(たとえば、鳥の画像の中から、さらにどの種類の鳥かを当てる)があります。これは一般的に非常に難しいタスクであるため、画像に加えてサブクラスの説明文やナレッジベース(図)など別の情報源を補助的に活用することが試みられているようです。
まずword2vecなどの手法を使って文章やナレッジベース等のメタデータをベクトル化することができます。分類したいサブクラスを単なるカテゴリカルなラベルでなくベクトル空間に埋め込み、ベクトルへの回帰問題として学習モデルを作ることで、補助情報を活かすことができます。
特徴量でなくラベルのほうに情報を入れるというのはおそらく元々zero-shot learningと呼ばれるタスクで使われるやり方なのですが、これをサブクラス識別問題にも使うのは近年試されているようです。この論文では(1)画像の局所的な特徴を発見するニューラルネットワークと、(2)前段で抽出した局所特徴と大域的な特徴量を両方使って分類問題を解くネットワークの2種類を用意し、さらにこれら2つを同時にend-to-endで訓練する方法を提案して、高い分類精度を得ています。
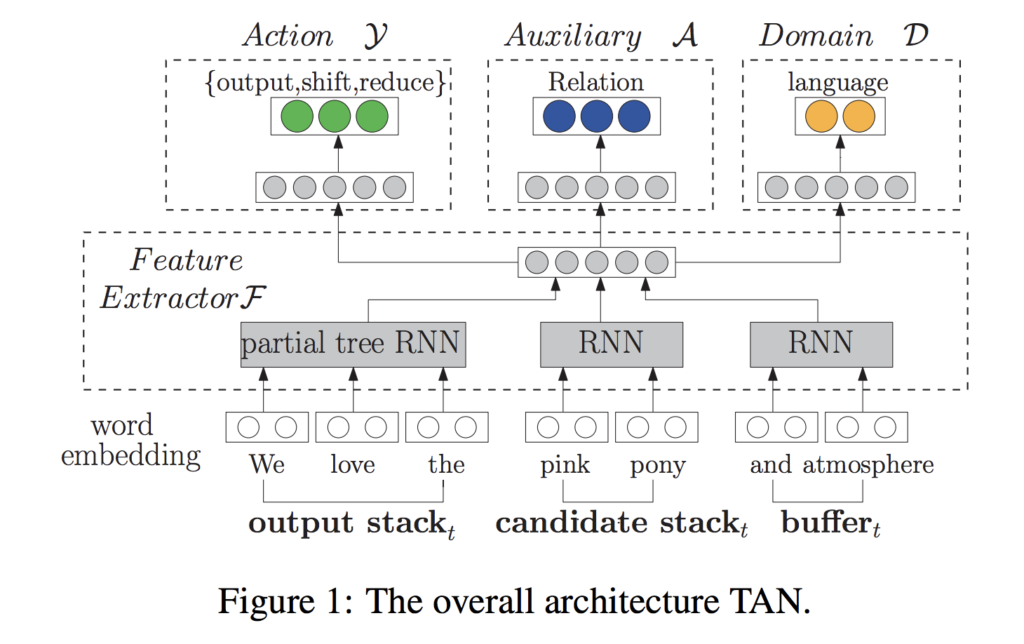
Transition-based Adversarial Network for Cross-lingual Aspect Extraction
アスペクト抽出のタスクは英語などメジャーな言語ではよく研究されているが、他の言語ではアノテーションされたコーパスがなく対処されてこなかったとされています。この論文では転移先対象へのアノテーションなしで言語間の転移学習をするモデルを提案しています。構文解析で一般的な Shift-Reduce アルゴリズムを Domain Adversarial Network (DAN) と統合して言語間で不変な特徴を学習し、言語間で単語数が異なる表現への適応や、構文情報の利用を可能にしているところが興味深いです。英→仏で特に大きく精度を改善しています。
おわりに
本会議中、会場の空きスペースのようなところでチェスのゲームAIを競うコンペが開催されていたのが印象的でした。人同士がチェス盤に向かい合ってはいるのですが、PCをチラチラ見ながらシステムの指示通りに盤面を操作する姿は、未来の人間の働き方をイメージさせる何かがありました。僕ら人間は非常に柔軟で汎用性のある優れた身体を持っていて、それこそが人工知能にない要素なのかもしれないなと。将来、人工知能の指示通りに完璧に動ける人が高所得者となるのかもしれないな、なんて妄想したりしました。
また、スウェーデンで山火事が多発していたらしいことを最近知ったのですが、会議中に滞在していたストックホルムは非常に快適で過ごしやすい環境でした。気温も最高24℃ぐらいで夕方には20℃前後で、夜22時になっても日本の夕方ぐらいの明るさがあったのでテンション高めに散策などができました。どこにいっても wifi が通っていてモバイル wifi などがなくともなんとかなりますし、お金もすべてカード払い。お店の人の愛想が非常によく、住みやすい街ランキングにランクインする理由がわかります。街並みが非常に美しく、「魔女の宅急便」のモデルとなったガムラスタンの景色は忘れられない思い出となりました。バンケットも沈没して引き上げた300年前の帆船を展示している博物館で開催され、歴史のある展示物を見ながらご飯を食べるという体験をしました。こういった体験も研究の糧となる気がするので、さらに研究成果を出して色々な街でより良い体験を得に行けたら最高だなと思います。

(バンケット会場となったVasa Museum)
Author