Blog
AAAI 2019参加報告:主にゲーム理論について
こんにちは、CADyVEの新卒1年目の金子(@coldstart_p)です.
先日開催されたAAAI 2019に参加してきました. 前半としてAI Lab 経済学チームの安井さんがバンディットと因果推論周辺についての記事を書いていましたが, 今回はその後半に当たる内容となっています. この記事では主にゲーム理論周辺における内容のレビューをしていきます.
自分は学部生だった頃に経済学部でゲーム理論のゼミに入っていたのですが, 内容は不完全私的観測の繰り返し囚人のジレンマゲーム(詳細はこちらの本を参照してください)の実験を行うというものでした. このゲームの均衡を解析するというゼミ教官の神取道宏先生の研究プロジェクト[1]に続く流れのもので, 学生はソフトを用いて実際に囚人のジレンマゲームを行ったり, 実験結果をディスカッションしたりということをしていた記憶があります. このような設定における均衡計算は非常に困難という理由もありその研究プロジェクトには九州大学の横尾先生や電通大の岩崎先生などComputer Science系の先生方も参加されていて, 学部生ながらそのような研究は当時としては(今も?)珍しい印象がありました. そのようなComputer ScienceとEconomicsの交差点に触れることができたことは幸運でした.
さて, AAAIの話に戻りますが, 感想としてはとにかくゲーム理論系のレベルの高い研究が多くて驚きました. 学部生の時に先述の経験をしておきながらCS系のゲーム理論の研究がここまで豊穣である事を知らなかったのは恥ずかしい話でした.
AAAIでゲーム理論関連の発表を聞いていた感想としてCS系のゲーム理論の研究とecon系のゲーム理論研究ではCS系の成果に驚くと同時になんとなく断絶があるように感じました. 実際, 帰国後に大学院でゲーム理論をやってる同期や後輩に聞いてみましたがAAAIで発表されているような話を知っていた人は皆無でした. 現地でもCS-econ系に興味のある学部時代の後輩と再会したので話をしたのですが, やはり彼も知らなかったようで, 先述の神取先生の研究プロジェクトで共著をされていた岩崎先生がこんなpostをなされていたので少なくとも経済学方面で殆ど知られていないのはある程度事実なのだと思います.
という事で経済学部で「ゲーム理論を学部生まで割と真面目に学んでいた身から見たAAAIのゲーム理論研究の感想」という趣旨での記事となります.記事に違和感や批判などあればご指摘いただけると幸いです.
Game Theory in AAAI
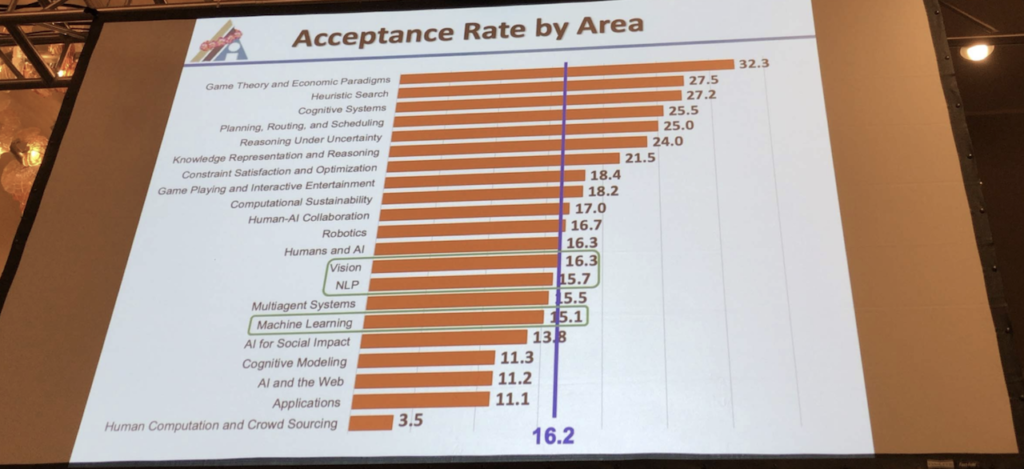
AAAIは個人的にはほぼゲーム理論系の学会でした. 上の画像のGame Theory and Economic Paradigmsというセッションがそれですが, 非常に高いAcceptance Rateで, Game Theory and Economic Paradigmsだけでも第10部までセッションがあり他の分野と比べ最大数でした. ここまで多かった理由は複数あると思いますが, 元々AAAIはCS系のゲーム理論研究が集まる場という経緯があるらしく非常にハイレベルの論文が集まる上に, 敵対的学習の論文もこの枠で複数採択されているという所にもよるかと思います.
特にゲーム理論系の研究者で目立っていたのがTuomas Sandholm先生でした. 彼は近年だとポーカーでトッププロ4人に大勝したAI “Libratus“の開発で有名です. トッププロに大勝したゲームAIというと囲碁におけるAlphaGoが有名ですが, 自分の手番においてその前に起きた情報(相手の取った手など)が全て観測可能な完全情報ゲームと違い, ポーカーは相手の取った手などのそれまで起きた情報の全てを把握できない不完全情報ゲームという違いがあります. このような不完全情報ゲームにおいてトッププレイヤーをAIが倒したというのが画期的なポイントでした. この不完全情報ゲームについての話は後の論文レビューでも触れていきます.
AAAIでのSandholm先生のスケジュールをまとめると
- 1日目 : Automated Mechanism DesignというメカニズムデザインのTutorial Session
- 2日目 : RL+ゲーム理論ワークショップ(Reinforcement Learning in Games)でパネルディスカッション登壇
- 3日目 : Honorable Mention Paperの発表(発表自体は共著者によるものでしたが)
- 5日目 : Invited Talk(動画)
と, 会議全日程を通じて非常に存在感がありました. ただ存在感があっただけでなく, 個人的にも最も鮮烈だったのはSandholm先生周りの研究でした. まずはゲーム理論が必要な理由について簡単に解説してから, Sandholm先生のペーパーなどを紹介したいと思います.
なぜゲーム理論が必要なのか
ナッシュ均衡
そもそもなぜゲーム理論がこれらの研究に必要なのかという話から入ります. たまにゲーム理論×ビジネスといったビジネス書を見ることがありますが, 実世界でも自分のことだけ考えて利益を最大化しようとしてもうまくいかないことは多くあります. 交渉において, 相手のインセンティブなどを考えず自分の利益だけを最大化しようとすれば, 交渉が決裂してしまう事がその最たる例と言えるでしょう. この様な状況では相手の出方を考えつつ自分がどうやったら利益を最大化を出来るだろうと考えるのが最終的に自己の利得を大きくする選択となるでしょう. このような「自分の利益が相手の行動に依存し, 相手の利益が自分の行動に依存する」といった相互依存的な状況をゲーム的状況といいます. この分析のために必要な概念がナッシュ均衡です. これは非常にざっくりいうと「お互いに,自分の戦略から逸脱しても利益を挙げられない状態(戦略の組)」, 要は「自分ひとりが戦略を変えても得ができない」安定した状態のことです. 経済学などではナッシュ均衡が成立しているという仮定のもとで実際の経済データを分析したり, CSの成果ではゼロサムゲームの条件下ですがナッシュ均衡をひたすら計算することでプロ4人に大勝するポーカーAI(Libratus)の作成が可能になったりしています. ゲーム的状況というのは実際に多くの人や意思決定主体が現実で直面しているはずですが, この中でどのようにすれば「合理的な」決定が可能かを導くツールであるというのがゲーム理論が必要な理由になってきます.
CS系とEcon系のギャップ
部分的にしか見ていない上に乱暴な区切りだとは思うのですが, AAAIでCS系のゲーム理論研究を見た上での感想です. 経済学はやはり社会科学なので, 近年だとどのように「合理的でない人間の行動を上手く説明できるだろうか?」とか「人間行動を説明できるようにゲーム理論を修正できるだろうか?」という方面に向かっていって, その流れの中で脚光を浴びているのが実験/行動経済学だと思っています. また,それとは別にゲーム理論のアプリケーションとしてメカニズムデザイン/マッチングといった領域がCS系とecon系のゲーム系研究者の融合先になっているのかなと思っています.
一方でCS系のゲーム理論研究として個人的に一番素晴らしいと思った成果がやはりLibratusです. 実はポーカーAIにはDeepStack というもうひとつ有名なものがあり, こちらは局面の評価をDeepLearningで行うというアプローチをとっています. Libratusの方はひたすらに部分ゲームというゲームの一部分を解く詳細化アプローチとゲームを抽象化して大雑把に解く抽象化アプローチで性能を挙げているため純粋にゲーム理論の成果の一つと言えると思いますが, これらの成果からは人間行動の説明とかどうでもいいからとにかく「合理的」なエージェントを作ってしまおうという気概を感じました. 実際, Sandholm先生がReinforcement Learning in Gamesワークショップのパネルディスカッションで「ゲーム理論は合理的なエージェントを表現することを担っている」というようなことを話していました. RLでは, 「最も合理的なエージェントが何をするのか?」というのは重要になってきますが, そのようなエージェントを獲得する事自体が難しいという状況があり, ゲーム理論の均衡概念はそれを示す一つの鍵になってくるのかもしれません. 個人的に「使える事に意味がある」CS系と「説明する事に価値がある」Econ系のゲーム理論研究に結構な断絶を感じたポイントはここだったと思います.以下の論文レビューではこの上記の「使える事に意味がある」という視点と「説明する事に価値がある」という両面から感想を述べていきたいと思います.
気になった論文レビュー
“Solving Imperfect-Information Games via Discounted Regret Minimization” (Link)
先述のHonorable Mention Paperで不完全情報ゲームにおけるナッシュ均衡の計算アルゴリズムについての論文です. 囲碁などの完全情報ゲームでは相手の取った手が全て観測可能なため,「実現している状態が一体何か」ということを考える必要はないのですが, ポーカーのような不完全情報ゲームだと相手が何を捨てて何の手札を引いたかということは見ることはできないので想定される状態が非常に多くなってしまいます. したがって, 例えば全てのありえる状態やパターンを考えて最適な戦略を求めるなどのことをすると必要な計算量が非常に大きくなってしまうので, この計算量をどのように抑えるかが大事になってきます.
そこで, Counterfactual Regret Minimization(CFR)というアプローチを取ります. Regretというのはざっくり言えば「最適戦略を選択したときと現在の戦略を選択した時の利得の差分」なのですが, ゼロサムゲームにおいてはりRegretの最小化問題を解けば近似的なナッシュ均衡(ε-ナッシュ均衡)を実現できるPolicyが得られることが定理[2]として知られています. これを不完全情報ゲームについて拡張したものがCFRなのですが, これの何が嬉しいかと言えば不完全情報ゲームでも上記のようなPolicyが得られる, つまり不完全な情報の中でも合理的な選択が可能ということです.
CFRでは平均戦略というものを更新していきます. そもそも戦略という言葉を曖昧に使ってきたのですが, ゲーム理論における戦略は, 自分が過去に得られている情報に対する行動の分布のことで, 行動計画書のようなものだと説明されたりもします. 平均戦略というものはその戦略をとった時にある状態が実現する確率で重み付き平均をとったもの(戦略は分布なのでこのような操作が可能なわけです)で, CFRはCounterfactual Regretが正, つまり現在得られている平均戦略より得をすることが可能なときにのみ平均戦略を更新するというアルゴリズムです. その後, CFR+[3]という改善手法が提案され, Counterfactual Regretが負の際は0にすることで更に計算量の抑制を実現しました.
本論文では, Linear CFR(LCFR)という新しいアルゴリズムを提案しています. これは, CFR+ではどうしても収束が遅くなってしまうゲームが存在するという問題を解決するもので, 「平均戦略の更新アルゴリズムにおいて時点tのiterationのたびにtで重み付けをする」というアルゴリズムになっています. 論文中では, 3つの行動に対応する報酬が0 , 1 , -1000000,というゲームにおいてはCFR+では収束まで471407回のiterationが必要な一方でLCFRだと970回でよいという結果を挙げています. これは, 初期のあまり良くないiterationを更新のたびにtで重み付けることで割り引くことができるため, 上記のような報酬が負の報酬が異常に高いゲームなどでは特に有効になるようです.
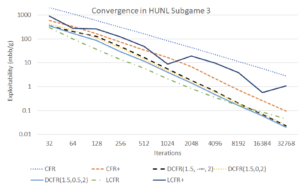
(Linear CFRの結果. 論文内より)
上記の図はポーカーでのパフォーマンスです.下に行くほどどれだけナッシュ均衡に近いかを示すグラフですが, LCFRがCFR+より早く正確に収束していることがわかります. しかし, LFCRだとゲームの設定によっては収束先がCFR+より悪くなったり, CFR+より遅い収束をすることがあるため, 論文内ではLCFRを一般化したDiscounted CFR(DCFR)というアルゴリズムを提案しています. DCFRを用いた場合はあるパラメータ設定の下では常にCFR+よりoutperformしたそうです.
「使う」という視点だと純粋に収束が早くパフォーマンスもよいアルゴリズムの提案ということで当然嬉しい研究で, 論文中の定理2で2人ゼロサムゲーム下でのε-ナッシュ均衡への収束も保証されてるので実用的だとは思います. しかし, テクニカルセッションの初日で自分がこの発表をいきなり聞いた感想は今まで知っていたゲーム理論研究と文脈が違いすぎてどこが面白いのかわからずに非常に困りました. 今から思うとこの論文は「合理的なエージェントを作る」という文脈で捉えるべき話だったと思いますが, 「それならば非合理なエージェントにどう対応するか?」 という話が次に紹介する論文の内容になってきます.
“Quasi-Perfect Stackelberg Equilibrium”(Link)
均衡の精緻化というトピックについてあつかった論文です. ナッシュ均衡はプレイヤーの合理性を強く仮定しすぎるなどの理由から不自然なものが均衡とされてしまうことがあります. したがって, これらの不自然な均衡を取り除きたいというモチベーションが生まれるのですが, 均衡になんらかの制約を課すことで均衡の範囲を制限することで不自然な均衡を取り除く事ができます. この様な不自然な均衡を取り除く処理を精緻化と呼び、この論文ではシュタッケルベルグ均衡についての精緻化を行っています.
シュタッケルベルグ均衡というのは, シュタッケルベルグモデルという寡占市場モデルにおける均衡です. 企業1が生産量q1を先に選んだあとに企業2が生産量q2を後に選ぶという先攻後攻のある寡占市場における競争モデルをシュタッケルベルグモデルといいます. 他には先攻を警備側, 後攻を侵入者側としてモデル化した警備ゲーム理論という分野でよくこのモデルが用いられるそうで, AAAIのセッションでも警備ゲームに関する発表がいくつかありました. ここに準完全均衡という精緻化均衡の概念を適用して解を導出したものが, この論文内で準完全シュタッケルベルグ均衡(Quasi-Perfect Stackelberg Equilibrium)とよばれるものです. 準完全均衡は摂動完全均衡を更に精緻化したもので, 摂動完全均衡というのはざっくり言えばプレーヤーが僅かな確率で誤りを犯しても依然均衡になる均衡のことです. プレーヤーが完全に合理的ならば誤りは犯すことはないのですが, 実際は人間は完全に合理的ではないということで導入された均衡概念になります.
本論文では, この準完全シュタッケルベルグ均衡について, 種々の定義を行った後に成立についての定理の証明や計算アルゴリズムの提案などを行っています. 論文中ではSandholm先生たちはシュタッケルベルグ均衡の解析というよりかは, 準完全均衡を強調して重要性を主張しているように見えました. 個人的には均衡の精緻化周りの研究は経済学方面で盛んにやられていたイメージだったので, 特にシュタッケルベルグ均衡という学部生でも知っている均衡の精緻化というトピックがまだ残っていてしかもCS系でやられていることにかなり驚きを感じました. 「説明する」という文脈だと均衡の精緻化というトピックは大事で, 経済学方面でも準完全シュタッケルベルグ均衡を用いた応用研究が可能かもしれません.(そのまま使っても面白い研究にはならないかなと思いますが…) 「使う」という文脈だと先程も述べたように今は「合理的なエージェントを作る」という視点から「合理的ではないエージェントにどう対応するか」という視点にSandholm先生などは目を向け始めているのかなという感想をいだきましたが, 特にSandholm先生の研究の幅の広さは恐ろしいと思わされました.
“From Recommendation Systems to Facility Location Games”(Link)
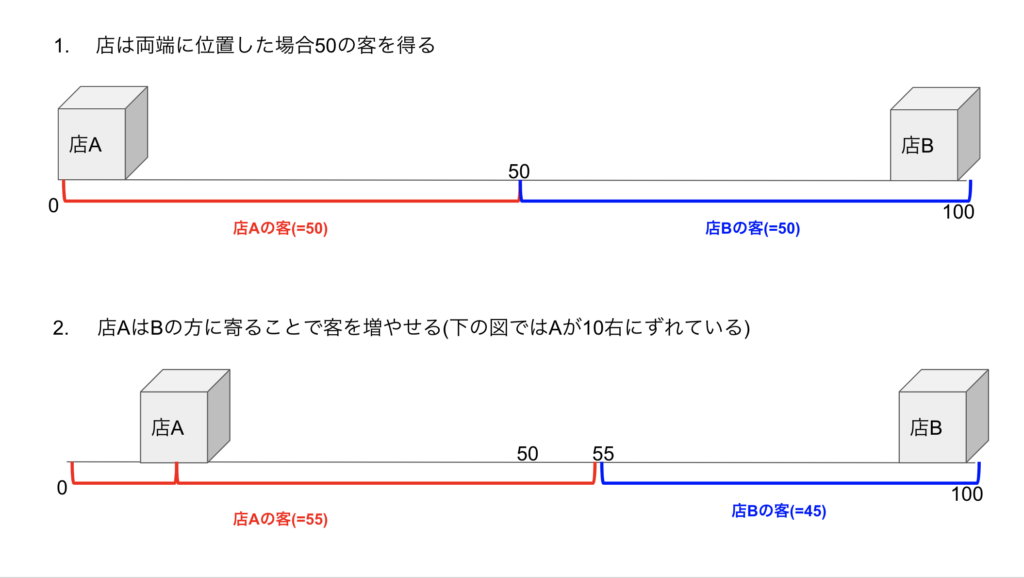
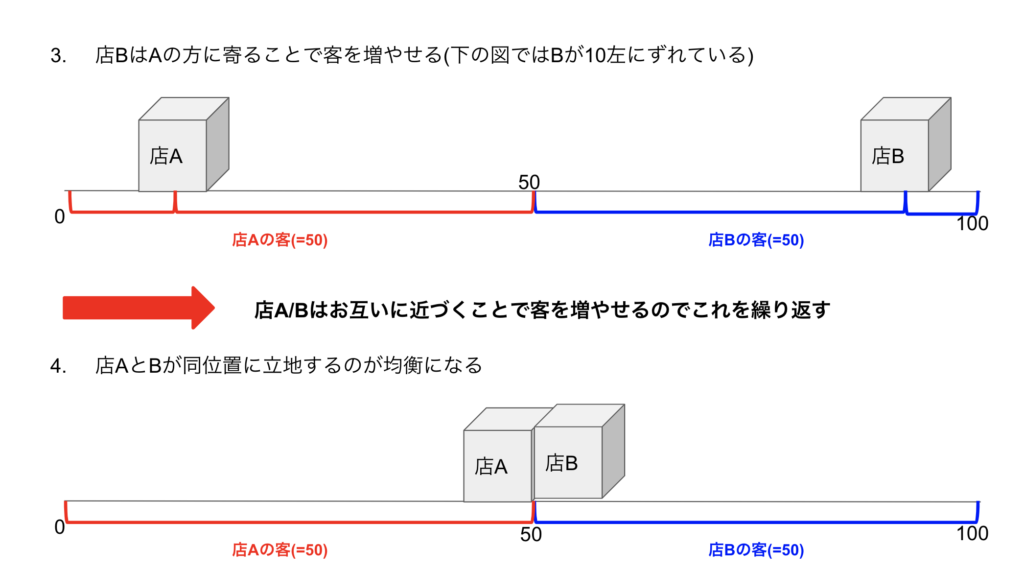
こちらはSandholm先生のPaperではないのですが, アイディアが非常に面白かったので紹介します. 古くからゲーム理論にはホテリングゲームという2次元の店舗立地問題があり, 2店舗で行う場合は同じ真ん中の位置に立地することが均衡になることが知られています. 3店舗以上だとこの結論は成り立たないのですが, しばしば電気屋やコンビニが極めて近くに立地することの説明に使われたりします. 以下は2店舗のホテリングゲームの大雑把な解説図です. それぞれの店舗は0から100の間の位置に立地可能で, お客はこの0から100に均一に散らばっていて近い方のお店に行く(等距離の場合は1/2の確率でAかBに行く)という設定になっています. このとき, 店は下の2,3のプロセスを繰り返してどんどん近づくことで結局同じ真ん中の位置に立地することが均衡になります.(別の位置で同じ位置に立地しても少しズレるだけでお客がいきなり増えるので均衡にはなりません)
本論文では推薦システムをこのホテリングゲームで定式化しており, 推薦エンジンはコンテンツができるだけ多くのユーザーに表示されようとコンテンツ表示を最適化してしまうため, コンテンツ制作者はとにかく表示回数を増やすためにユーザーに”近く”なる様にコンテンツを作成するという戦略が考えられます. 結果, 前述の2店舗ゲームのように似通ったコンテンツが作成されてしまい, コンテンツはユーザーの効用はほぼ無視して作られることになるので、結果として社会的厚生が悪化してしまう(かもしれない)という問題があります. この問題に対処するために, いわゆる”仲裁者”を導入することを提案していて, この仲裁者による社会的コストをおさえつつ, より厚生を上げるような均衡に誘導するようなデザインを提案しています. 推薦システムをホテリングゲームで表現するという視点とメカニズムデザイン的な視点の組み合わせは非常に面白かったです.
経済学的な視点だとミクロ経済学の授業では「経済モデルをどのように上手く抽象化してモデリングするかが一番センスの見せ所だ」という教えを今まで受けていたのもあり, この論文ではそういう点で非常にセンスを感じました. 「使う」という意味ではこのホテリングゲームだと2次元のケースしか考えていないので理論的にはその拡張が大変そうだと思いましたが, この様な状況が実際の状況でも起こりそうなのであればそれを判断できそうなKPIを設定して観測・対処するなどのデータサイエンスのタスクによる対処を考えるのが良さそうかつ面白そうだと思いました.
アドテク企業におけるゲーム理論
最後に, 簡単にどうやってゲーム理論をアドテクビジネスに応用できるかなと考えた話をして終わります. 個人的には学生の頃からゲーム理論の”有用性”に関しては甚だ疑問でした. 人間行動の説明のための寓話(Fable[4])を語るツールとして面白いとは思っていましたし, 今になって思えばゲーム理論やミクロ経済学を学んだことで戦略的な思考や通常とは異なる視点といったものが身について得をしていると思うことはあるのですが, アドテク系の民間企業という中で企業にとって価値のあるような応用が可能なのかという点については全く見当がつきませんでした. 当然ネット広告はオークションなのでSSPにメカニズムデザインやマッチング理論を適用できるとは思いますが企業にとっても嬉しい研究というのは非常に難しいと思っていましたし, 少なくとも複数均衡や限定合理性のことを考えるとゲーム理論をWeb企業における予測ツールの一つとして使うのは厳しいと思っていました. そういう点ではゼロサムゲームのポーカーという条件下ではあるのですが, とにかく「合理的」であることでお金を稼ぐことに成功していたLibratusは直接お金になっているという点でわかりやすく嬉しいものを見たなと思っています.
「使う」という視点だと, Sandholm先生の先述の「ゲーム理論は合理的なエージェントを表現することを担っている」という発言を再度引きますが, アドテクにおいても合理的なエージェントを作ろうとする(例えばそれはbidderかもしれませんし他のなにかかもしれませんが)と重要になってくるはずで, アドテク外の他の分野でも関わってくるかもしれません. 「説明する」という視点だと, 3本目に紹介したホテリングゲーム論文のように鮮やかに推薦システムなどの現在のインターネットサービスで重要な位置を占めるシステムをモデリングしてサービス改善に繋がるような示唆を与えられる研究は非常に面白く感じました. 理論的に複雑なモデルに拡張するのは非常に難しいかもしれませんが, 企業だと実際にA/Bテストなどで検証も行いやすいためこのような形での活かし方も可能なのかなという事を思いました. 非常に素人考えですし一人で考えてても限界はあるのですが面白そうなことができる気はしているので「アドテク方面でゲーム理論使って面白いことをやりたい!」と考えているCS/Econ系の研究者+学生の方がいらっしゃったら冒頭の私のTwitterなどにお気軽に連絡していただけると幸いです.
引用
[1] “部分観測可能マルコフ決定過程を用いた私的観測付き繰り返しゲームにおける均衡分析プログラム”,ジョヨンジュン,岩崎敦,神取道宏,小原一郎,横尾真,情報処理学会論文誌,53(11), 1882-7764, 2012
[2] Zinkevich, Martin, et al. “Regret minimization in games with incomplete information.” Advances in neural information processing systems. 2008.
[3] Tammelin, Oskari. “Solving large imperfect information games using CFR+.” arXiv preprint arXiv:1407.5042 (2014).
[4] Rubinstein, Ariel. Economic fables. Cambridge, UK: Open Book Publishers, 2012 (和訳あり)
Author