Blog
【採択論文紹介】短絡的な予測の抑制手法 (TACL)
AI Lab NLPチームの本多です。この記事では、モデルが陥りがちな短絡的な予測を抑制し、頑健な予測を可能にする手法を紹介します。本研究の成果は Transactions of the Association for Computational Linguistics (TACL) に採択されています。
Not Eliminate but Aggregate: Post-Hoc Control over Mixture-of-Experts to Address Shortcut Shifts in Natural Language Understanding [Code]
Ukyo Honda, Tatsushi Oka, Peinan Zhang, Masato Mita
はじめに
自然言語理解タスクの主要なデータセットでは、アノテータの偏好や経験則、あるいは自然言語の構成的な特性などの影響により、ラベルと相関する単純な特徴量が存在していることが知られています。図1で例を見てみましょう。
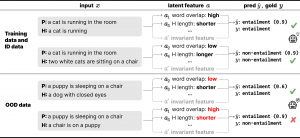
図1:ショートカットの例。
図1では含意関係認識を例にとっています。含意関係認識は、前提文Pに対して仮説文Hの内容が含意(entailment)、矛盾、無関係(図1ではまとめてnon-entailmentと表記)のどの関係(ラベル)であるかを判別するタスクです。図1上部は、学習データにおいてPとHの単語の一致率(a1, a2)やHの文長(a3, a4)がラベルと相関している様子を表しています。これらの特徴量は、学習データとそれと同一の分布から得られたデータにおいてはラベルに対する予測力を持つことになります。しかし、当然これらはラベルを決定する本質的な情報ではありません。図1下部のように、学習データと異なる分布から得られたデータにおいては、これらの特徴量とラベルとが同様には対応しない事例が容易に見つけられます。
このような単純な特徴量はショートカットと呼ばれ、機械学習における問題のひとつとなっています [1, 2]。これが問題であるのは、上で見たようにショートカットとラベルとの相関は簡単に変動してしまい、モデルがこれに依存すると予測の頑健性が損なわれるためです。加えて、単純であるがゆえにモデルにとって捉えやすく、学習・予測時に依存しやすいということが問題を深刻にしています。また、ショートカットは意図的にデータに混入されたものではないため、何がショートカットになっているのかわからないという問題もあります。
そこで、ショートカットへの依存を抑制して頑健な予測を行おうという研究がなされてきました [3, 4]。
提案手法
本研究では、この分布外データにおける予測の問題を、不確実性下の意思決定の問題と考えます。ショートカットを含む自然言語理解データでは、ラベル予測に本質的な特徴量に加えていくつかの特徴量がラベルと相関しています。ただし、それらの詳細は通常わかりません。今回対象とする分布外データで問題となるのは、いずれかの特徴量についてラベルとの相関が変動するがどの特徴量について変動するのかはわからない、ということです。そこで、どの特徴量に依拠して予測すればいいのかわからない不確実性のもとで最適な意思決定を行おうということを考えます。この目的のために提案する手法は、学習時と推論時の2つのパートから成っています。
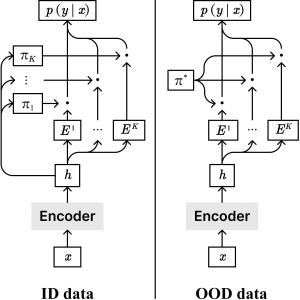
図2:提案手法概要。
学習時は、複数の特徴量がラベルと相関するというデータ構造をモデル化するため、mixture-of-experts (MoE) モデル、特にmixture-of-softmax (MoS) モデル [5] を用います 。それぞれ異なるパラメータを持つexpert (\(E^k\)) が入力事例\(x\)のラベルを予測し、router (\(\pi\)) が事例ごとにどのexpertの予測を用いるかの重みを決めます。また、各expertがそれぞれ異なる特徴量に基づいて予測するよう促進するため、自己注意機構 [6] にヒントを得たペナルティ項を提案しました。ここでは詳細は省きますが、異なる事例は異なる特徴を持つと仮定し、事例ごとに異なるexpertに割当てられるよう促進します(図3)。
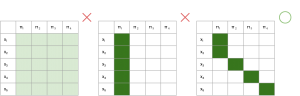
図3:理想的な事例割当ての例。
推論時は、どのexpertの予測を用いるべきかわからないという想定のもとで、最適な意思決定を行います。決定理論に基づいた2つの手法を提案しており、いずれもexpertの割当てを決定する\(\pi\)を、ルールベースの重み\(\pi^*\)に置き換えてexpertの予測の統合します(図2右)。1つ目のuniform weightingでは、どのexpertに依拠すべきかわからないが、どのexpertも同等によく予測できると仮定して、expertの予測の平均をとります。2つ目のargmin weightingでは、より悲観的な状況を考えます。各選択肢について不正解となるリスクが最も高い状況を想定し、そのような最悪の場合でも最も良い結果が得られる選択肢を選びます(図4)。直感的には、各ラベルで最も慎重なexpertの意見を聞いて判断するような選択となります。
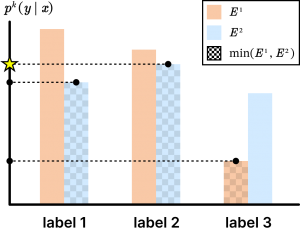
図4:Argmin weightingの例。
提案手法の詳細や既存手法との違いについてはぜひ論文をご覧ください。
実験
実験では、含意関係認識(MNLI)、言い換え同定(QQP)、事実性検証(FEVER)の3つの自然言語理解タスクにおいて、提案手法を適用することで分布外データ(OOD)において頑健な予測が可能になることを示しました(表1)。実験設定や比較手法の詳細は論文をご覧ください。また、論文では推論時操作の適応的な使い分けの可能性や、expertが捉えた特徴量の解釈性、要素技術ごとの影響などについても実験・議論しています。
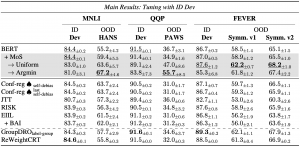
表1:主な実験結果。
おわりに
本研究では、MoEモデルと決定理論を用いることで頑健な予測を可能にする手法を提案しました。このような決定理論を用いた予測の後処理には、今後さらなる発展の可能性があると考えています。今回の研究は、NLPチームと、研究開始当時にAI Lab経済学チーム所属であった岡達志教授(慶應大)との研究議論から始まったものです。NLPチームでは、今回の研究や強化学習チームとの共同研究などのように、異なる専門領域との共同研究を進めてきました。今後も連携を深めつつ、広告文生成や関連する基礎研究について幅広く取り組んでいきます。毎年、博士課程の学生を対象にリサーチインターンシップを募集していますので、興味を持たれた方はぜひお声がけください。
参考文献
[1] Causally Motivated Shortcut Removal Using Auxiliary Labels (Makar et al., AISTATS 2022)
[2] Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond (Feder et al., TACL 2022)
[3] Don’t Take the Easy Way Out: Ensemble Based Methods for Avoiding Known Dataset Biases (Clark et al., EMNLP-IJCNLP 2019)
[4] Unlearn Dataset Bias in Natural Language Inference by Fitting the Residual (He et al., 2019)
[5] Breaking the Softmax Bottleneck: A High-Rank RNN Language Model (Yang et al., ICLR 2018)
[6] A Structured Self-attentive Sentence Embedding (Lin et al., ICLR 2017)
Author