Blog
Goptunaを使ったGo言語におけるベイズ最適化の活用
はじめに
形状のわからない関数(ブラックボックス関数)の最大値あるいは最小値を求める手法として、ベイズ最適化が広く利用されています。機械学習モデルのハイパーパラメーター最適化を中心に活用が進んでいますが、入力とそれに対する評価値さえ設計できればあらゆる問題に適用できます。
例えばFacebookでは、MLモデルのチューニングはもちろん、映像コーデックのエンコードパラメーター 1、AR/VRハードウェア設計、HHVM JITコンパイラのパラメーターチューニングにベイズ最適化を適用するため BoTorch や Axの開発を進めています (F8 2019の発表 Product Optimization with Adaptive Experimentation を参照)。
弊社では多くのサーバーシステムでGo言語が採用されていますが、サーバーのgoroutine数やキャッシュシステムのメモリーバッファーサイズの調整など、システムの性能に影響を与えるあらゆるパラメーターチューニングをベイズ最適化によって自動化できるといいでしょう。今回はGo言語のベイズ最適化ライブラリを調査しつつ、そこで見つかった問題を解決するためPythonのハイパーパラメーター最適化ライブラリOptunaをGoに移植しました (c-bata/goptuna: Bayesian optimization framework in Go)。これらの性能とパフォーマンス比較結果を合わせて紹介します。
ベイズ最適化の概要
まずはベイズ最適化がやっていることを解説します。0から10の範囲の実数値をとるパラメーターによってシステムの性能が変わるとします。この中でシステムの性能が最もよくなるパラメーターを選びたいのですが、最も基本的なアイデアは次の2つです。
- 0, 1, 2, …, 10と一定の間隔でパラメーターを変化させながら、性能がよくなるパラメーターを探ってみる (Grid Search)
- 0から10の値をとる乱数値をパラメーターとして与え、性能がよくなるパラメーターを探ってみる (Random Search)
これらは非常にシンプルな手法ですが、最適と思われる解にたどり着くには多くの評価回数が必要そうです。ブラックボックス最適化において1回の評価に時間がかかる状況も多く存在することから、少ない評価回数でより最適な解にたどり着けるといいでしょう。
例えば人間であれば、過去の結果をもとに次にどのパラメーターを評価するとよさそうかなんとなく想像が付きます。既に選んだ中でいい評価値を得られた点があれば、その近くはいい評価値が得られそうですし、かといって近くのパラメーターばかり評価するのではなく、全く評価していないパラメーターがあればそこはまだ探ってみるといい評価値が得られるかもしれません。こういった人間の感覚に近い探り方はベイズ最適化で実現できます。その流れは次の通りです。

These illustrations are created by Masahiro Nomura.
まず目的関数を予測する代理モデルを構築し、不確かさを考慮するため代理モデルから獲得関数を計算します。最後にその獲得関数の最大値をL-BFGSなどを用いて求め、次の探索パラメーターとして選択します。State-of-the-Artなベイズ最適化手法として、ガウス過程(GP: Gaussian Process)を代理モデルとして使用する手法や、Parzen Estimatorを代理モデルとして使用するTPE、Random Forestを代理モデルとして使用するSMACが知られています。
- GP (Gaussian Process)
- TPE (Tree of Parzen Estimators)
- Pythonライブラリ: Hyperopt, Optuna 2
- 論文: Algorithms for Hyper-Parameter Optimization
- SMAC (Sequential Model-based Algorithm Configuration)
go-bayesoptによるGPベースのベイズ最適化
Go言語でもベイズ最適化を活用するために、既存のライブラリを探してみたところ、 go-bayesopt というGPベースのベイズ最適化ライブラリが見つかりました。star数は現段階でそれほど多くありませんが、Facebookのエンジニアでgo-pryの開発者ということもありコードも読みつつ調査してみました。最新のgonumには存在しないAPIも叩いてはいたのですが、少し直せば動作しました (既にupstreamにマージされています)。検証に用意したのは次のプログラムです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
package main import ( "log" "math" bayesopt "github.com/d4l3k/go-bayesopt" "github.com/d4l3k/go-bayesopt/gp/plot" ) func main() { X1 := bayesopt.UniformParam{ Name: "X1", Max: 10, Min: -10, } X2 := bayesopt.UniformParam{ Name: "X2", Max: 10, Min: -10, } o := bayesopt.New( []bayesopt.Param{X1, X2}, bayesopt.WithRandomRounds(10), bayesopt.WithRounds(100), bayesopt.WithMinimize(true), ) x, y, err := o.Optimize(func(params map[bayesopt.Param]float64) float64 { x1 := params[X1] x2 := params[X2] log.Printf("x1: %f, x2: %f\n", x1, x2) return math.Pow(x1-1, 2) + math.Pow(x2-2, 2) }) if err != nil { log.Fatal(err) } log.Printf("x: %#v\n", x) log.Printf("y: %f\n", y) fp, err := plot.SaveAll(o.GP()) if err != nil { log.Fatal(err) } log.Printf("plot: %s\n", fp) } |
目的関数として最小化問題 \((x1-1)^2 + (x2-2)^2\) を用意しました。その最適なパラメーターは \((x1, x2) = (1, 2)\) です。最初にRandom Searchによるパラメーターの選択を10回行った後、代理モデルとしてGP、獲得関数としてUCBを用いたパラメーターの選択が90回行われます。実行結果は次のとおりです。
|
1 2 3 4 5 |
$ go run _examples/main.go ... (中略) 2019/07/25 15:23:23 x: map[bayesopt.Param]float64{bayesopt.UniformParam{Name:"X1", Max:10, Min:-10}:1.0221672603083967, bayesopt.UniformParam{Name:"X2", Max:10, Min:-10}:1.8540991095989217} 2019/07/25 15:23:23 y: 0.021778 |
全100回の評価が行われ、最良評価値は、 \(f(1.022, 1.854) = 0.021778\) となりました。プロットされたグラフを見ると次のように、評価値の高そうな点を重点的に探っている様子が確認できます。
| X1の探索パラメーター分布 | X2の探索パラメーター分布 |
|---|---|
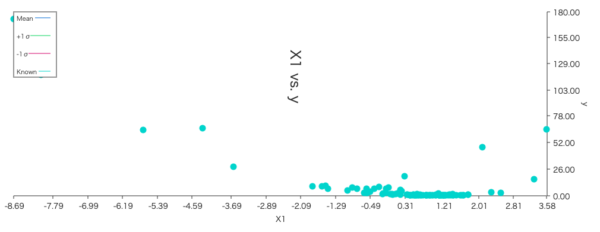 |
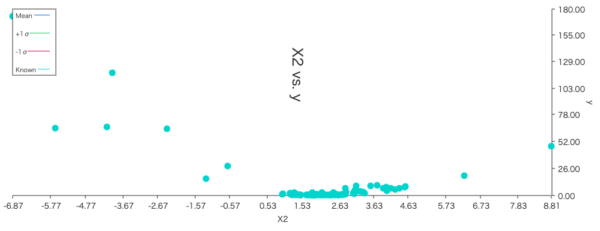 |
期待通りの挙動となっていますが、おそらく勉強用途で実装されていることもあり、実用する上では機能面や設計面で少し気になる点があります。EI(Expected Improvement)など別の獲得関数を使いたいケースでは追加で実装する必要があるでしょう。また100回の評価に5分程度かかっていて、実用を考えると実行速度の遅さが少し気になります。
GP回帰モデルからの推論は逆行列の計算なども含んでいて、一般に計算時間が長くなりがちです 3。
ガウス過程回帰モデルを構築するためのPythonライブラリとして有名なものに GPy やscikit-learn GaussianProcessRegressor などがあります 4。これらのライブラリはnumpyやscipyを通してLAPACK等が使われていますが、Go言語ではポータビリティを保つ上でそれらの使用を避けたいケースも少なくないでしょう。ブラックボックス最適化の活用の幅の広さからもPure Goで効率よく計算できると嬉しいです。
Goptunaの開発と性能評価
TPEであればPure Goでも十分な速度で実装ができそうです。既存のライブラリが存在しないため、ブログのネタづくりも兼ねて実装してみました。ソースコードはGithubで公開しています。
Goptuna: https://github.com/c-bata/goptuna
名前の通り Optuna をGoに移植したものですが、TPEやRandom Searchがすでに利用できます。また目的関数の設計もOptunaが採用しているDefine-by-Runインターフェースを採用しました。エラーハンドリングやOptionの指定方法など、いくつかGoらしい設計に変えているところもありますが、次のように直感的に使うことができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
package main import ( "fmt" "math" "github.com/c-bata/goptuna" "github.com/c-bata/goptuna/tpe" "go.uber.org/zap" ) func objective(trial goptuna.Trial) (float64, error) { x1, _ := trial.SuggestUniform("x1", -10, 10) x2, _ := trial.SuggestUniform("x2", -10, 10) return math.Pow(x1-1, 2) + math.Pow(x2-2, 2), nil } func main() { logger, _ := zap.NewDevelopment() defer logger.Sync() sampler := tpe.NewSampler(tpe.SamplerOptionNumberOfStartupTrials(10)) study, _ := goptuna.CreateStudy( "goptuna-example", goptuna.StudyOptionSampler(sampler), goptuna.StudyOptionSetDirection(goptuna.StudyDirectionMinimize), goptuna.StudyOptionSetLogger(logger), ) _ = study.Optimize(objective, 20) v, _ := study.GetBestValue() params, _ := study.GetBestParams() fmt.Println("result:", v, params) } |
float64 arrayの演算にgonumの提供する機能を使っていますが、blas等は使用していません。またgonum/matを使わずに実装しましたが、TPEのアルゴリズムはmatrix系のライブラリを使わなくても無理なく実装できるものでした。go-bayesoptと同じ条件で実行した結果を次に示します。
Random Searchの結果 (試行回数 100回)
|
1 2 3 4 5 6 7 |
$ go run _examples/simple_random_search/main.go ... (中略) 2019-07-25T15:38:13.118+0900 INFO goptuna/study.go:86 Finished trial {"trialID": "trial_100", "state": "Complete", "value": 18.845306588659962, "paramsInIR": "map[x1:-2.8258879781259587 x2:1.6366822473849254]"} Result: - best value 2.5904889254208054 - best param map[x1:0.4405659427118902 x2:0.7883530201915825] |
TPEの結果 (試行回数 100回. Random Search 10回を含む.)
|
1 2 3 4 5 |
2019-07-25T15:38:53.267+0900 INFO goptuna/study.go:86 Finished trial {"trialID": "trial_100", "state": "Complete", "value": 5.787230311617731, "paramsInIR": "map[x1:-0.9596342547271463 x2:0.604627684337362]"} Result: - best value 0.6195459685895217 - best param map[x1:0.7770961438621743 x2:1.2451093857329996] |
Random Searchがどの点を選択したかということに大きく影響されますが、今回のケースでTPEの結果はgo-bayesoptより悪く、Random Searchよりいいパラメーターを見つけました。今回の目的関数は、次元数が低く、そのパラメーターの中に質的変数(カテゴリ変数)が登場しないことから、GPが得意とされているものであることも一因として考えられるかと思います 5。
次は実行時間を比較してみましょう。目的関数はほとんど時間を使わないシンプルなものであることからこの実行にかかる時間は、ブラックボックス最適化ライブラリが消費している時間が支配的です。
| 試行回数 | go-bayesopt | Goptuna (random search) | Goptuna(tpe) |
|---|---|---|---|
| 50 | 0m51.887s | 0m0.022s | 0m0.030s |
| 100 | 5m39.491s | 0m0.024s | 0m0.053s |
GPは過去の選択点が増えると反比例的に必要な計算時間が増えてしまいますが、TPEは非常に高速に動作しました 6。Goで実装されたサーバーミドルウェアのパラメーターチューニングなどをする際にパラメーターの選択にあまりにも時間がかかっていては、利用が難しいかと思いますがGoptunaのTPEは十分に高速なケースがほとんどではないかと思います。
まとめ
今回はGoのベイズ最適化ライブラリgo-bayesoptを調査しつつ、今回用意したGoptunaとその性能を比較しました。GoptunaのTPEによるベイズ最適化は非常に高速に動作し、パラメーターの次元数が大きい場合や、質的変数(カテゴリ変数)を含むパラメーターであればGPを採用しているgo-bayesoptよりも良いパラメーターを見つけることができるかもしれません。
実験的に実装してみたものですが、結構気に入っているので今後も足りない機能を足していこうかなと思っています。みなさんもぜひ使ってフィードバックしていただければと思います。
脚注
- Optuna開発チームのsile氏は、最適なx.264のエンコードパラメーターをベイズ最適化を用いて探索し、x.264のプリセットの性能と比較した実験を行っています。面白い結果となっていますので、興味のある方はぜひ読んでみてください(Optunaを使ってFFmpegのエンコードパラメータを最適化してみる)。 ↩
- OptunaがTPEやRandom Search以外の手法を実装する上で、Samplerインターフェースの設計に問題がありました。今月リリースされたv0.13.0においてSamplerインターフェースの設計が修正され、scikit-optimizeのbackendが追加されたことから、目的関数の設計に注意点はありますがGPベースのベイズ最適化を活用することができます。 ↩
- 後述するTPEの計算量がイテレーション回数 \(t\) について\(O(t)\)の計算量であるのに対し GPは \(O(t^3)\) の計算量が必要です。 ↩
- GPyのコードは少し複雑になってしまっていて筆者はコードリーディングを一度諦めたのですがscikit-learnの方はシンプルなのでコードリーディングする際はおすすめです。scikit-learnの実装は速度が遅い印象はありますが、今投げているPRがマージされれば25%程度は早くなりそうです。マージされたらぜひ試してみてください scikit-learn/scikit-learn #14378 Avoid cloning kernel objects of GaussianProcess models ↩
- Eggensperger, K., Feurer, M., Hutter, F., Bergstra, J., Snoek, J., Hoos, H., and Leyton-Brown, K.: Towards an Empirical Foundation for Assessing Bayesian Optimization of Hyperparameters, in NeurIPS workshop on Bayesian Optimization in Theory and Practice (2013).)。 ↩
- プロファイリングによる調査までは行っていませんが、ここまでの差がついた要因として考えられるのは獲得関数をL-BFGSによって最適化する際に、局所解に陥ってしまうことを防ぐため探索の初期点を100000回程度変化させながら一番いい点を評価していることも挙げられそうです。 ↩
Author