Blog
YANS 2019 参加報告① 〜チャットボットの運用における自然言語処理の活用〜
アドテクスタジオAIメッセンジャーの友松、杉山、戸田です。
8/26-8/28にホテルエミシア札幌で行われたNLP若手の会(YANS)2019にて発表を行いました。今回弊社からは9名が参加し、スポンサー発表1件, ポスター発表3件(共同研究を含む)を行いました。


- スポンサー・ポスター発表S03:サイバーエージェントにおける自然言語処理の取り組み
- ○張培楠(株式会社サイバーエージェント)
- [学生]ポスター発表 P63:修辞技法を考慮したキャッチコピー自動生成に向けた研究
- ○丹羽彩奈, 岡崎直観(東工大), 西口佳佑, 亀山千尋, 毛利真崇(サイバーエージェント)
- ポスター発表 P83:デジタル広告における商品特徴を考慮した広告文の自動生成
- ○脇本宏平(サイバーエージェント), ○川本峻頌(明大), 張培楠(サイバーエージェント)
- ポスター発表 P84:チャットボットの運用における自然言語処理の活用
- ○戸田隆道, 杉山雅和, 友松祐太(サイバーエージェント)
本ブログではP84の「チャットボットの運用における自然言語処理の活用」についての発表報告をさせていただきます。ブースターセッション, ポスター
P83「デジタル広告における商品特徴を考慮した広告文の自動生成」の発表報告については、後日こちらのブログにアップ予定です。
AIメッセンジャーについて
AIメッセンジャー(以下AIM)は自動応答のチャットボットと有人対応が切り替え可能な対話接客プラットフォームです。主に企業様のお問い合わせページなどで提供されカスタマーからの質問に自動で応答を行います。自動応答のチャットボットはFAQに基づく用例ベースの対話システムとシナリオによるルールベースの対話システムのハイブリッドです。
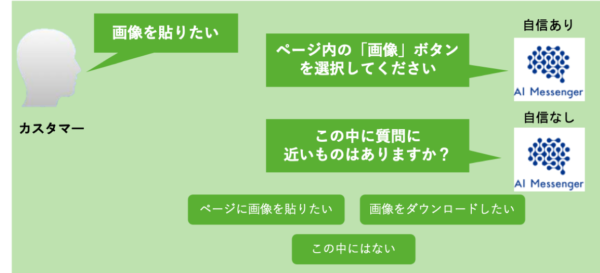
用例ベースの対話システムの回答精度を高めるためには大きく分けて2つの要素が挙げられます。
* ・モデルの賢さ
* ・モデルが参照するデータ(FAQ)の網羅性およびクオリティ
一見、1つ目のモデルの賢さの方に目がいきがちですが、FAQの網羅性およびクオリティを高めることは同等かそれ以上に重要になります。どんなにモデルが賢くても、用意されたFAQが貧弱だとチャットボットはユーザの質問に答えることができません。
FAQの網羅性およびクオリティを高めるために、日々運用が人手によって行われています。以下はその運用プロセスになります。
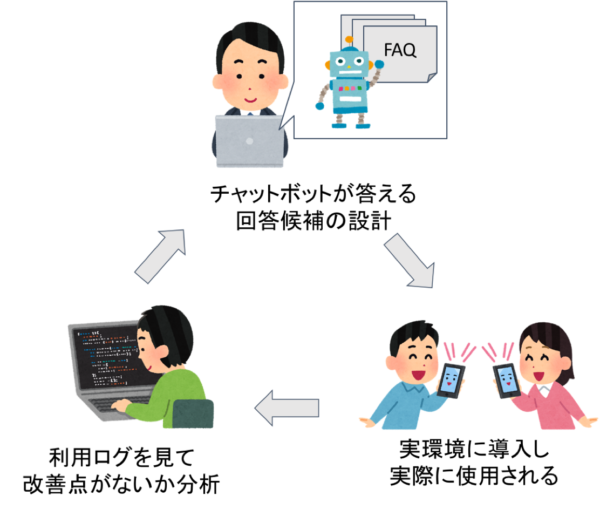
AIMでは、この人手による運用をできるだけ効率的に行うために自然言語処理の技術を活用しています。今回のYANS2019ではその取り組みの一部について発表を行いました。
- チャットボットの機能と関係のない問い合わせのフィルタリング
- 表記揺れ辞書の自動構築
- 利用ログからの新たな回答候補の生成
- リグレッションテスト
チャットボットの機能と関係のない問い合わせのフィルタリング
実環境に導入されたチャットボットは導入時には想定しなかったような問い合わせを行われることが少なくありません。その一つがチャットボットの機能と関係のない問い合わせです。例えば下記のようなゲーム広告や不幸の手紙(チェーンメール)です。

6割以上がこういった問い合わせで占められてしまった導入先環境もあり、チャットボット改善のためのログ分析の際に視認性が悪くなってしまうため、事前にフィルタリングが必要です。
今回の取り組みではルールベースで抜き出した、チャットボットの機能と関係のない問い合わせを正例、チャットボットの回答候補であるFAQ文章を負例として分類器を作成しました。手動ラベリングしたテストデータで評価を行ったところ、ROC AUC=0.812となり、完全に自動でフィルタリングを行うには少し心もとないため、閾値を調整することでフィルタリングを行える機能をログ分析のビューに追加しました。現在運用チームで重宝される機能の一つとなっています。
表記揺れ辞書の自動構築
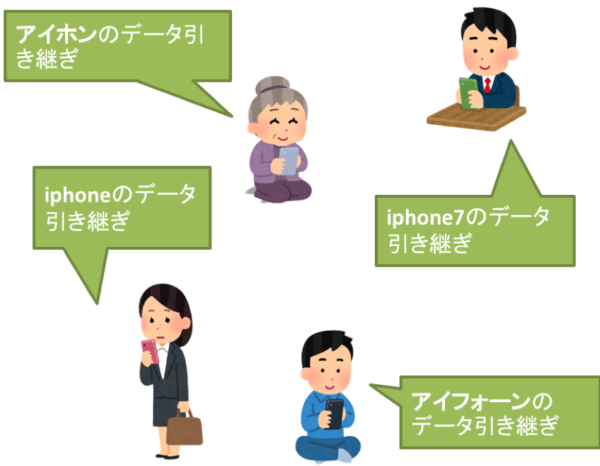
AIMのチャットボットではユーザの自由な入力を許可しています。
iPhoneという単語一つとってみても「iPhone」, 「iphone」, 「アイホン」, 「iphone7」, 「アイフォーン」など様々な言い回しで問い合わせが来ます。
また、iPhoneとAndroidを区別したほうがいい場合(iPhoneとAndroidで解決法が異なる場合)と区別しなくてもいい場合(スマホとして認識されれば良い場合)などドメインによって表記揺れの要件が変わって来ます。
ドメインごとに表記揺れ辞書を網羅的に構築するのは非常に困難です。
そこで、ユーザの発話データやFAQデータから教師なしで表記揺れ辞書を作成するのが本研究のモチベーションになります。
表記揺れ語を抽出するにあたって、単語の分割を行いたいところですが、サービス固有の単語やチャットならではの言い回しによってうまく単語の分割ができないことがあります。そこでSentence Pieceを用いた分割を行います。Sentence Pieceはコーパス中の文字の並びから意味のある分割を学習します。
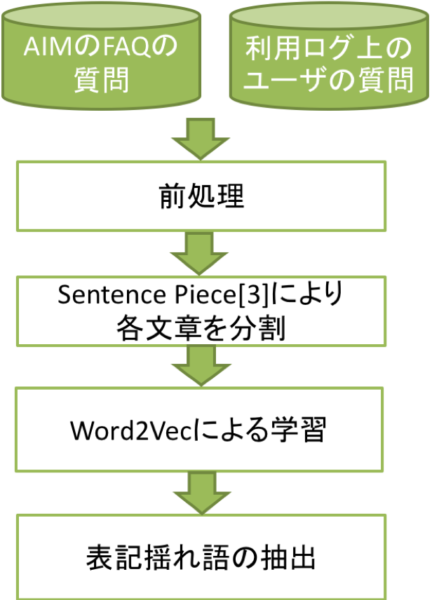
表記揺れ辞書構築の手順は上記フローの通りです。
対象データ
* ・AIMが保持するFAQデータ
* ・AIMの配信ログのユーザ発話
フロー
1. 小文字化など正規化を行う前処理
2. Sentence Pieceによりトークンで分かち書きを行う
3. Word2Vecにより分散表現を学習
4. 表記揺れ対象語を入力として近いトークンを抽出
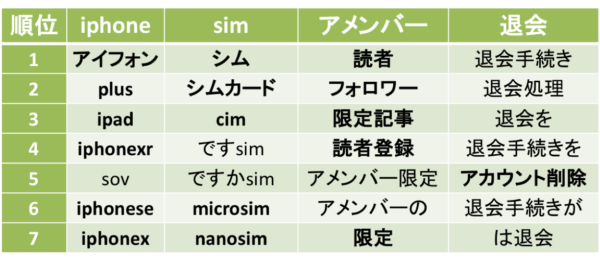
上記の表は想定される表記揺れ語と抽出された候補です。
「iphone」にたいしてはカタカナ表記の「アイフォン」や各機種をあらわす「iphonexr」、「iphonese」、「plus」などが抽出することができました。
また、「アメンバー」というブログを特定のユーザに配信することができる機能である、サービス特有の単語においては、「読者」や「フォロワー」などのほかに、通常単語分割すると分離されてしまう「限定記事」や「読者登録」なども抽出することができました。
一方で課題として、「です」や「の」など助詞や助動詞にあたる部分がうまく分割されずに現れているという点が挙げられます。
今後の取り組みとして次のようなことを考えています。
1. 各ハイパーパラメータ(特にSentence Piece)のチューニング
2. 「です」や「の」などの余計な部分の除去
3. 表記揺れが起こりそうな語の予測(現在は入力に対して表記揺れ候補をサジェスト)
4. FAQ応答のロジックに表記揺れを吸収する機構を追加
利用ログからの新たな回答候補の生成
現在チャットボットの回答候補は、クラスタリングした問い合わせを人間が確認し、その内容をまとめることで作成しています。これは非常に手間のかかる作業で、作業者ごとの表記揺れなどの属人化などの課題があります。理想的には問い合わせログから自動で回答候補を生成したいと考えていますが、今回はその前段階としてクラスタリングされた問い合わせの集合から、そのクラスタを代表する問い合わせを抽出する試みを行いました。
抽出方法はEmbedRank(Kamil Bennani-Smires , Claudiu Musat , Andreaa Hossmann, Michael Baeriswyl, Martin Jaggi “Simple Unsupervised Keyphrase Extraction using Sentence Embeddings”, CONLL 2018)のキーフレーズ抽出手法を参考に、問い合わせの各文章の文書ベクトルをクラスタ内全体のベクトルと比較し、最も近い問い合わせを抽出する、という手法を使用しました。
結果としては長文に引っ張られてしまったり文法的に違和感のある文書が抽出されてしまったりと、まだまだ実用化は難しそうでしたが解決しなければならない課題を認識できました。
リグレッションテスト
これまで紹介した取り組みにより、人手で行なっている運用の支援・自動化が現実的になってきました。しかし、自動で回答候補を追加したり表記揺れを整形することで挙動が変わり、これまで回答できていた質問に回答できなくなる可能性があるため自動生成した文言をそのまま追加することは危険です。
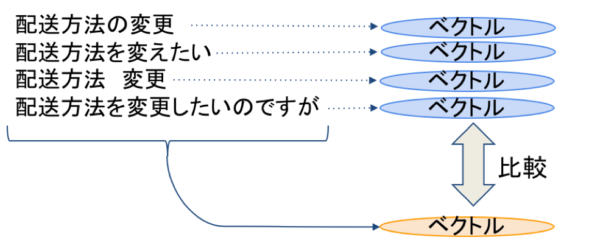
なぜそのようなことが起こるのかについて説明します。AIMではユーザーの質問と、よくある質問として用意している質問群(用例)の類似度を計算することでユーザーの質問内容を推定し回答候補を提示します(図1)。質問間の類似度を計算するための特徴量としてTF-IDFなどの素性を用いているのですが(図2)、これらは類似度の予測モデルを更新せずとも用例を更新するだけで変化するため、それによって類似度が変化しこれまで回答できていた質問に答えることができなくなる可能性があるためです。
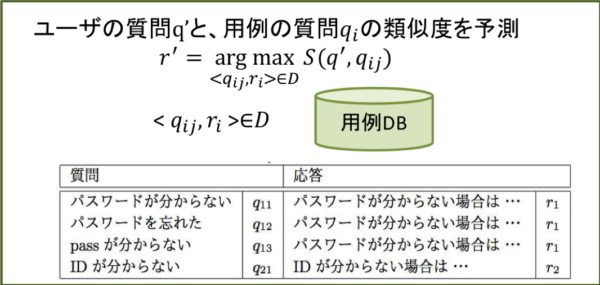
図1
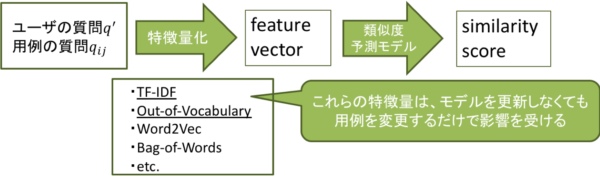
図2
そこで用例の変更前後で、過去にユーザーから送られた質問とその時の回答候補、そして提示した回答候補が選ばれたか否かを事前に確認するための環境を作成しました。
例えば図3のように、これまで回答候補の5番目がユーザーに選択されていた質問に対して、用例変更後に類似度が下がりその選択肢が提示できなくなるケースでは、ユーザーの思う正しい回答候補が上位から消えてしまい、選ぶことができなくなってしまいます。
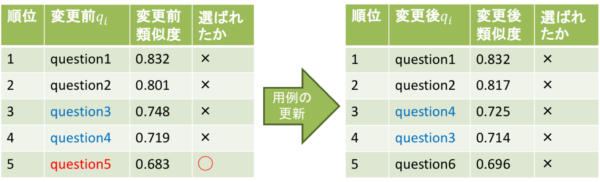
図3
このように過去の質問に対して類似度や順位がどのように変化するか、また新しく追加した用例が期待する動作をしているかを確認することができるようになることで、機械的に用例の変更可否を判断できるようになり運用の支援や自動化に向けた取り組みを安心して行うことができます。
今後はオフラインでのテスト環境だけでなく、オンラインでのA/Bテストを行い評価するための環境も充実させていく予定です。
まとめ
以上、NLP若手の会(YANS)2019での活動報告でした



ポスターセッションでは非常にたくさんの方に来ていただき、ご自身の知見の共有や鋭いご指摘など今後の活動に活かせそうなご意見をたくさんいただきました。ありがとうございました。
今回紹介した取り組みは現在モジュール別に独立して動いていますが、今後はそれらを統合し、より人手による作業の削減に取り組んでいきたいと思います。
最後に、今回発表したように、私たちは実プロダクトとしてリリースされているチャットボットで収集された対話データを使った研究開発を行なっております。
共同研究やインターンに興味がある方はぜひお問い合わせ下さい。
Author