Blog
TensorFlow2.0時代のTensorFlow Serving向けモデル出力
TensorFlow2.0がリリースになりましたね!
TensorFlow2.0からDefine by run形式を踏襲した、eager executionによる実行が基本になりました。しかし1.0時代のパフォーマンスを担っていた、処理のgraph化を捨てたわけではありません。2.0系からはtf.functionという機能を使って、Python構文のサブセットをハイパフォーマンスなTensorFlow graphへと変換できます。(より詳細にはこちら)
今回はAPIへの利用を睨んだ、取り回しのしやすいモデルファイルを作成することを目指します。肝となるのは、上記で述べたtf.functionを使って、学習済みモデルそのものに入出力の変換処理を加えることです。入出力の変換処理をモデルに追加することで、TensorFlow Servingを用いたAPI運用が格段に楽になり、バグも防げる可能性も高くなるでしょう。
実行環境は、Google Colaboratoryを利用し、Python3系とTensorFlow2.0系での実行を前提としており、今回の実行コード全体はnotebook形式でこちらになります。
予測モデルと入出力の摩擦
機械学習のモデルをアプリケーションなどに組み込む際に気をつけなければならないことの一つに、入力と出力の形式があります。この入力と出力の取り扱いを間違えてしまうとせっかく正しい予測をしても、例えばウェブアプリの画面に表示されている予測結果が全く違うものになってしまうことさえあります。
このような危険性について、TensorFlowのチュートリアルを例に考えてみましょう。このチュートリアルでは、シャツや靴などの体に身に着けるものの画像を入力すると、その種類を判定してくれるモデルを作成しています。このモデルを用いて、画像情報をHTTPリクエストで送るとその種類の判定結果をレスポンスするWeb APIを作ることを考えます。
TensorFlow Serving
TensorFlow Servingは学習したモデルをSavedModelとしてエクスポートすると、そのモデルの入出力に応じたAPIサーバーをたてることができるツールです。
では、「画像情報をHTTPリクエストで送るとその種類の判定結果をレスポンスするWeb API」は単純にチュートリアルで作ったモデルを保存し、SavedModelに載せるだけで完成でしょうか?
実はこのモデルから上記のWeb APIを作成するためには、大きく二つの処理を追加する必要があります。
入力について
まずはモデルの入力について考えてみましょう。
モデルの入力は学習時のデータの形式に左右されることになりますが、一般的に画像の場合は numpy array のような実数の配列になってきます。
しかしながらアプリケーションが画像を取り扱う場合に、実数の配列で保持してることはあまり考えられません。例えば、JSONリクエストで画像をPOSTする際には、配列で送るよりもBase64で画像をエンコードしたデータを送る方法がより一般的です。
では、例えばあるサーバーが別のサーバーからBase64で画像を取得して、それを今回の予測APIサーバーにリクエストを送る場合はどうでしょう?その場合リクエストの送り元が、画像データをBase64から配列に変換する処理を行うことになります。しかしエンコードした画像をどのようなサイズの配列に処理するのか、画像情報の配列は正規化するのかなど、いわゆるデータの前処理を学習スクリプトを睨みながらクライアント側に実装することになります。
これらの前処理はモデル固有なので、モデルサーバーに受け持ってもらえる方が責務としてもすっきりしますし、変換処理がずれたために予測がうまくできないなどのバグも出にくくなるのではないでしょうか?
出力について
次に出力について考えます。
チュートリアルで作成したモデルの出力は、各クラスに属する確率が出力されるのみになります。
具体的には
|
1 2 3 |
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] |
のように、文字列の配列で定義したクラスの順番に則って
|
1 2 3 4 |
array([5.2581032e-07, 1.4517748e-09, 2.5350946e-08, 9.0922248e-09, 1.5219296e-08, 2.0876075e-03, 2.2626289e-06, 6.2742099e-02, 8.7106038e-08, 9.3516731e-01], dtype=float32) |
のような出力が得られます。
これを上で述べたWeb APIで動かす場合 、配列の10番目が 9.3516731e-01 でもっとも確率が高いため、 Ankle boot を予測結果として返すように処理を加えて上げる必要があります。このような状態だと、APIを叩くクライアント側とコミュニーケーションミスでT-shirt/topとTrouserが入れ替わるだけで、せっかく正しい予測をしていても、クライアントが得る結果が全く異なるという危険性を孕んでしまいます。
このようにモデルの入力と出力は、学習時のままだと非常に扱いづらいばかりかバグを生みやすい状態で、全くもって取り扱いやすい状態ではないと言えます。
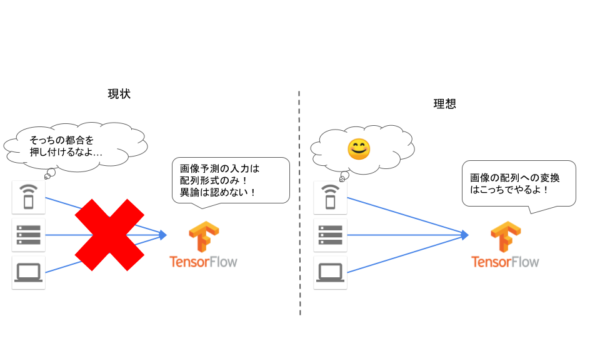
モデルに変換処理を埋め込む
モデルの入出力のために、使う側が入出力に気を使い続けるのは事故の元です。そこでモデルそのものに入出力の処理を含めてしまうことを考えましょう。
TensoFlowは、特に2.0系から、Define by run形式を取り入れていますが、あまり変更のないPython処理をGraphとして固めて、Python実行の遅さをカバーする機能を提供しています。
これを利用して、入出力をモデル側で調整できる状態で保存し、それをTensorFlow Servingに受け渡すことで機械学習に関する責務をすべてモデルサーバーに押し込むことができます。
モデルの構築
具体的なコードでみていきましょう。
モデルの構築はチュートリアルを踏襲しますので、詳しい説明はそちらを参照ください。
ここではモデル構築のコードを簡単な説明にとどめます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import tensorflow as tf fashion_mnist = tf.keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() train_images = train_images / 255.0 class_names = [ 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] |
まずデータセットの用意を行い、学習データの正規化とラベルの整理を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
model = tf.keras.Sequential([ tf.keras.layers.Input(shape=(28, 28), name='image'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax', name='output') ]) model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) model.fit(train_images, train_labels, epochs=10) |
その後モデルの構築をKerasで行い、学習を行います。上記の二つのコードを走らせることで精度がおおよそ90パーセントのモデルが得られると思います。
これで学習済みモデルの準備が整いました。
入力処理の追加
画像をHTTPのリクエストで受ける場合に、選択肢の一つとしてあげるのがBase64エンコードされた画像をJSONのリクエストとして送る方法です。
その場合、モデルはBase64で受けたものを実数の配列型に変換しなければ予測を実行できません。
その処理を追加していきましょう。
|
1 2 3 4 5 6 7 |
def _base64_to_array(img): img = tf.io.decode_base64(img) img = tf.io.decode_image(img) img = tf.image.convert_image_dtype(img, tf.float32) img = tf.reshape(img, (28, 28)) return img |
上記の関数は、Base64エンコードされた画像データを、配列として変換します。
この関数とモデルを繋げるためには、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@tf.function(input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string)]) def serving(input_images): def _base64_to_array(img): img = tf.io.decode_base64(img) img = tf.io.decode_image(img) img = tf.image.convert_image_dtype(img, tf.float32) img = tf.reshape(img, (28, 28)) return img imgs = tf.map_fn(_base64_to_array, input_images, dtype=tf.float32) predictions = model(imgs) return predictions |
のように、tf.function を利用すれば、一つのGraphとして表現することが可能です。
これで、入力をBase64の画像情報で予測を成り立たせることができるようになりました。
出力処理
入力側の処理はうまく解決できましたが、出力側はどうでしょうか?
未処理のモデル出力は各クラスの確率がただ吐かれるのみなので、実際何のクラスとして予測されたのかはいちいちクラス定義の配列を参照する必要があります。
ここもモデルに埋め込んでしまいましょう。
|
1 2 3 4 5 6 7 8 9 10 |
def _convert_to_label(candidates): class_names = [ 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] max_prob = tf.math.reduce_max(candidates) idx = tf.where(tf.equal(candidates, max_prob)) label = tf.squeeze(tf.gather(class_names, idx)) return label |
上の処理はもっとも確率の高いクラス名を返すように処理を行う関数で、以上をまとめると
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@tf.function(input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string)]) def serving(input_images): def _base64_to_array(img): img = tf.io.decode_base64(img) img = tf.io.decode_image(img) img = tf.image.convert_image_dtype(img, tf.float32) img = tf.reshape(img, (28, 28)) return img imgs = tf.map_fn(_base64_to_array, input_images, dtype=tf.float32) predictions = model(imgs) def _convert_to_label(candidates): class_names = [ 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] max_prob = tf.math.reduce_max(candidates) idx = tf.where(tf.equal(candidates, max_prob)) label = tf.squeeze(tf.gather(class_names, idx)) return label return tf.map_fn(_convert_to_label, predictions, dtype=tf.string) |
という計算Graphの定義が行えます。
これを
|
1 2 3 4 5 6 |
version_number = 1 tf.saved_model.save( model, export_dir='/opt/model/transformed_for_serving/{}'.format(version_number), signatures=serving) |
としてSavedModel形式で保存すると、TensorFlow Servingで入出力の整備されたクラス名予測サーバーが即座に建てられます。
実際に
|
1 2 3 4 5 |
$ tensorflow_model_server \ --rest_api_port=8501 \ --model_name=f_mnist \ --model_base_path="/opt/model/transformed_for_serving" |
のようなコマンドでサーバーを起動するとモデルサーバーが利用でき、10種類の画像に対して
|
1 2 |
{'predictions': ['Ankle boot', 'Pullover', 'Trouser', 'Trouser', 'Shirt', 'Trouser', 'Coat', 'Shirt', 'Sandal', 'Sneaker']} |
といったレスポンスが返ってきました。
まとめ
このようにTensorFlowの tf.function の機能を使い、入出力をコントロールすることで、TensorFlow Servingで立ち上がるAPIサーバーの取り回しのしやすさが格段にあがります。また今後TensorFlow2.0がメジャーバージョンになるにつれて環境が整備されていくことが期待されますが、AI PlatformのServing機能がこれに追従することで、フルマネージドな環境で取り回しのいいAPIが簡単に作れることになると思われます。今後もTensorFlowの、運用やユーザービリティを睨んだアップデートを期待していきたいと思います。
Author