Blog
最近の Transformer × Video
こんにちは、AI Lab の鈴木智之 (@tomoyukun) です。
最近、NLP分野で大きく成功した Transformer [1] が様々な研究領域で応用され始めており、最新論文をチェックしていく中で見ない日はないほどとなりました。今回はそんな中でも動画認識、特に動画分類において Transformer (及びそれを構成する計算機構) を応用した研究事例を紹介したいと思います。
動画分類は各動画に割り当てられたクラス (行動、イベント等) の分類問題です。動画認識というと行動検出・物体追跡・動画キャプション生成など動画を入力に定義される様々なタスクを含みますが、その中でも動画分類は汎用的な動画認識モデルのベンチマークタスクの一つとして位置付けられる、最も基本的なタスクです。
※ この記事は Transformer 自体の解説は含みません。Transformer に関しては元論文 [1] の他に以下の記事がわかりやすいのでおすすめです。
紹介論文リスト
- Non-local neural networks (2018)
- Video Transformer Network (2021)
- Is Space-Time Attention All You Need for Video Understanding? (2021)
- An Image is Worth 16×16 Words, What is a Video Worth? (2021)
- ViViT: A Video Vision Transformer (2021)
Non-local Neural Networks
Xiaolong Wang, Ross Girshick, Abhinav Gupta and Kaiming He. Non-local neural networks. CVPR, 2018.
論文リンク
Non-local Neural Networks は Transformer を構成する計算機構である self-attention が初めて導入された動画認識モデルです。特徴マップの各位置座標をトークン (NLPにおける単語) とみなした self-attention を 2D / 3D CNN に導入します。Query / Key / Value はそれぞれ、各位置座標の特徴ベクトルの線形写像によって計算されます。各線形写像のパラメータは位置座標間で共有されているので、Point-wise (1 × 1 × 1) 畳み込み処理 として実装可能です。
最終的には以下のように、self-attention の入力と出力の要素和をとる non-local blockを構築し、CNN の中間層に導入します。
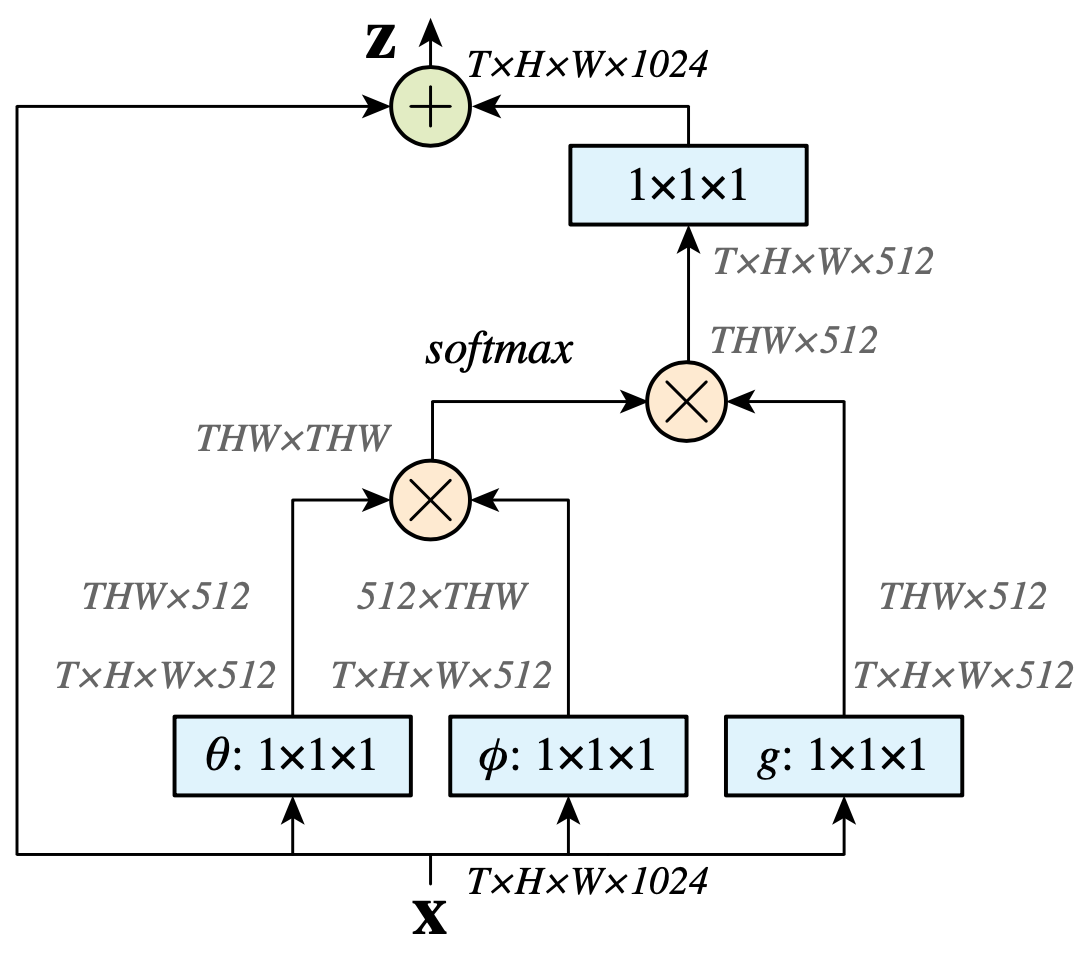
(図は元論文より引用)
評価は行動分類データセット Kinetics-400 [2] を用いて行われています。2D / 3D CNN のいずれにおいても、non-local block の導入による精度向上が確認され、畳み込み処理とは相補的な効果があることが示されました。また、2D CNN からの時間拡張として、畳み込みを 3D にするよりも non-local block によって時空間的関係を考慮する方が少ない計算コストの増加で高い精度向上を達成できることが確認されました。
下図は、ある位置 (矢印の始点) から見たときの attention が強い上位 20 の位置座標 (矢印の終点) を可視化した例になります。行動分類に有用な関連位置に強い attention が当てられていると主張されています。

(図は元論文より引用)
Video Transformer Network
Daniel Neimark, Omri Bar, Maya Zohar and Dotan Asselmann. Video transformer network. arXiv:2102.00719, 2021.
論文リンク
Video Transformer Network (VTN) はフレーム単位で抽出された特徴量をトークンとして Transformer ベースの時系列モデルに入力し動画単位の出力行うモデルです。フレーム単位の特徴抽出には 2D CNN やTransformer ベースの画像認識モデル Vision Transformer (ViT) [4] が、時系列モデルには Longformer [5] が用いられています。Longformer は attention の範囲を近傍に制限することで入力長に対して線形時間で計算可能となった Transformer で、より長い時間長の動画入力に対応するために用いられています。
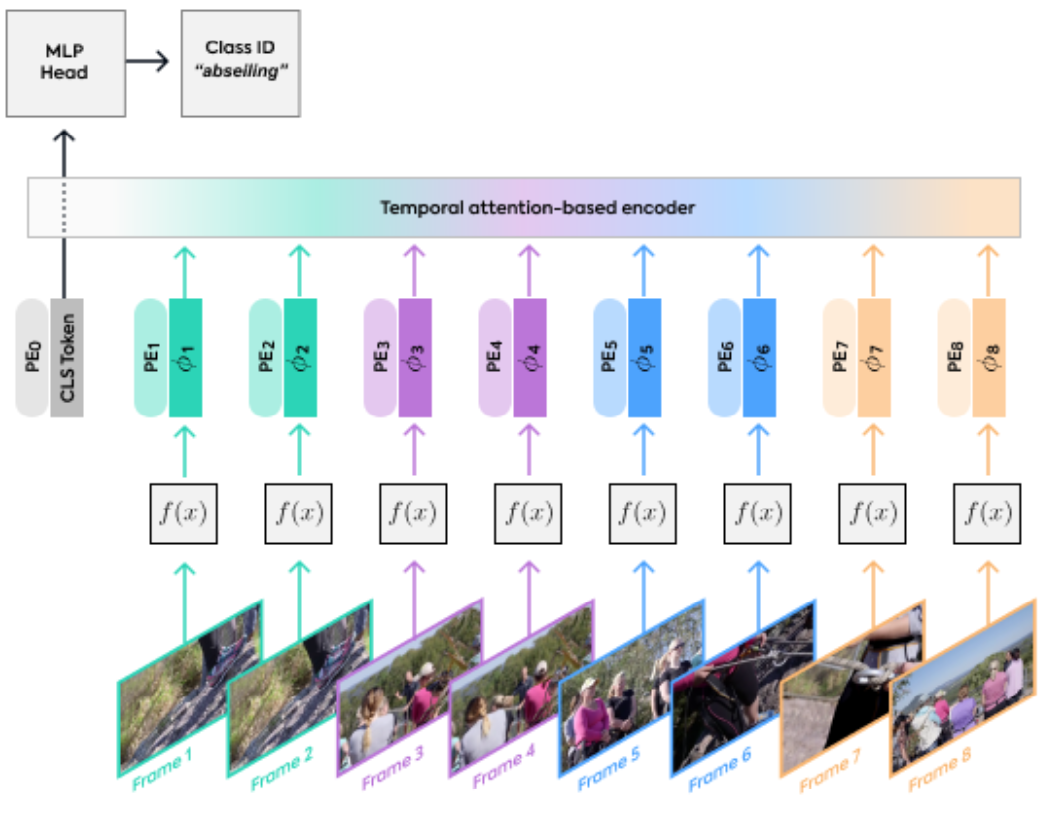
(図は元論文より引用)
VTN の推論は multi-view、full-video の2つの方法が用いられています。multi-view 推論は、動画から決まった時空間的大きさにトリミング・クロップされたものを一つの “view” とし、それを動画全体から一様に複数抽出、それらに対するモデルの出力結果の平均を動画全体の出力とします。一方で full-video 推論は、動画全体をモデルに入力し、動画全体の出力を得ます。multi-view 推論における view 数の設定にもよりますが、論文中の設定 (30 views) においては full-video 推論の方が multi-view 推論よりも計算コストが少ないです。一般に、学習時には推論時よりも多くのメモリを必要とするため、行動分類におけるモデルの学習は view 単位の入力で行われます。このように学習された 3D CNN ベースのモデルは multi-view 推論の方が精度が高くなりますが、VTN においては full-video 推論が multi-view 推論と同等以上の精度を記録しています。最終的に、多少実験不足感はあるものの、 Kinetics-400 [2] において VTN + full-video の設定で既存手法に匹敵する精度をより少ない計算コストで実現しています。
また、Kinetics-400 において VTN への入力を時間方向にランダムシャッフルしても精度が変わらないという興味深い結果が得られています。Transformer は Positional encoding によって各トークンの位置情報を考慮しますが、Positional encoding の使用に関わらず、この現象が確認されています。ここから、少なくとも論文内の設定では、VTN (における Transformer) は入力を集合として捉えており、時系列情報としては捉えていないことが推測されます。動画を時系列情報として捉えなくても行動分類がある程度解けてしまうというのはなかなか衝撃的です。
Is Space-Time Attention All You Need for Video Understanding?
Gedas Bertasius, Heng Wang and Lorenzo Torresani. Is space-time attention all you need for video understanding?. arXiv:2102.05095, 2021.
論文リンク
これまで紹介したモデルは CNN と Transformer を組み合わせたものでしたが、この論文で提案されている TimeSformer は Transformer のみで構成された動画認識モデルです。Transformer のみを用いた画像認識モデル ViT [4] と同様に、動画の各フレームをパッチに分割したものをトークンとみなし、これらを線形写像によって埋め込み表現としたものを Transformer に入力します。
TimeSformerでは、計算コスト削減のために attention の対象となる範囲を制限しています。下図のように複数の制限方法を比較し、精度が最も高く計算・パラメータ効率も良い Divided Space-Time Attention を採用しています。Divided Space-Time Attention では時間方向のみの attention と空間方向のみの attention が連結されたブロックを複数連結して全体のモデルを構築します。
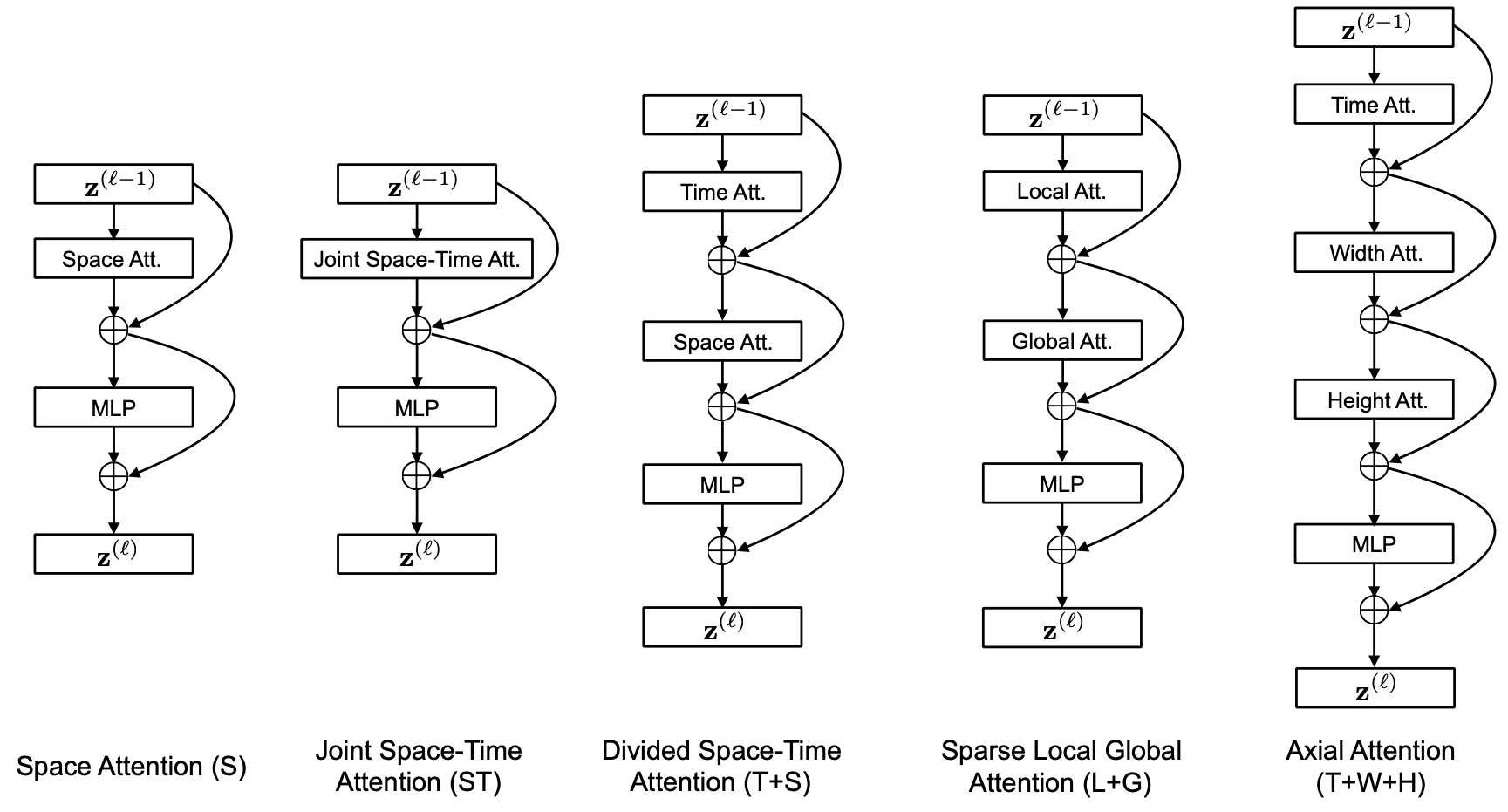

青で表された注目パッチに対する attention の対象範囲を他の色で表しています。 (図は元論文より引用)
実験では、Kinetics-400 [2]と Kinetics-600 [3] において、既存手法と比較して大幅に少ない計算コストで最も高い精度を達成しました。注意点として、TimeSformer への入力は既存手法と比較して時間方向に疎にサンプリングされ、時間的に広い範囲をカバーしたものになっています。その代わりに、推論時の view 数を少なくしており、この部分が計算コストと精度のトレードオフ改善に大幅に効いています。
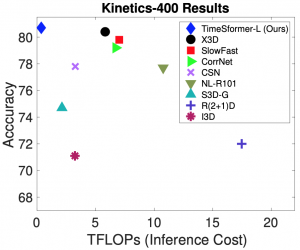
(図は元論文より引用)
さらに、長時間の動画を含む HowTo100M [6] データセットにおいて時間的に広い範囲を入力とする同一の条件で 3D CNN ベースのモデルと TimeSformer を比較し、TimeSformer が 3D CNN ベースのモデルを大きく上回る精度を記録しています。ここから、TimeSformer は時間的に広範囲のモデリングに向いていることが主張されています。
一方で、SomethingSomething v2 (SSv2) [7] では 3D CNN ベースや動き特徴に着目した既存手法を下回る精度となりました。SSv2 は Kinetics-400 / 600 と比較して、より詳細な動きパターンの認識が重要なデータセットとして知られており、TimeSformer はそういった情報の抽出が苦手である可能性が伺えます。また、TimeSformer の学習に必要なデータ量に関しても興味深い記述があります。まず、TimeSformer は ImageNet で事前学習を行っているのですが 、動画データセットからのスクラッチ学習には失敗したと述べられています。ただし、これに関する具体的な実験結果や詳細は記載されていません。さらに、Kinetics-400 と SSv2 において、学習データ量を変化させたときの精度を記録しています (下図)。Kinetics-400 では、常に 3D CNN ベースのモデルを上回っているのに対し、動きパターンの認識が重視される SSv2 では学習データ量が少ない条件で 3D CNN ベースのモデルを下回る結果となっています。ここから、TimeSformer は動きパターンの認識により多くの学習データを要する可能性が述べられています。

(図は元論文より引用)
An Image is Worth 16×16 Words, What is a Video Worth?
Gilad Sharir, Asaf Noy, Lihi Zelnik-Manor. An Image is Worth 16×16 Words, What is a Video Worth?. arXiv:2103.13915, 2021.
論文リンク
この論文で提案されている Space Time Attention Model (STAM) はアーキテクチャとしては VTN と同様で、入力のサンプリング方法は TimeSformer の設定と近いです。学習時・推論時共に動画全体から決まったフレーム数を疎にサンプリングし view 数を大幅に抑えることで、Kinetics-400 [2] において計算コストと精度のトレードオフを既存手法と比較して大幅に改善しています。
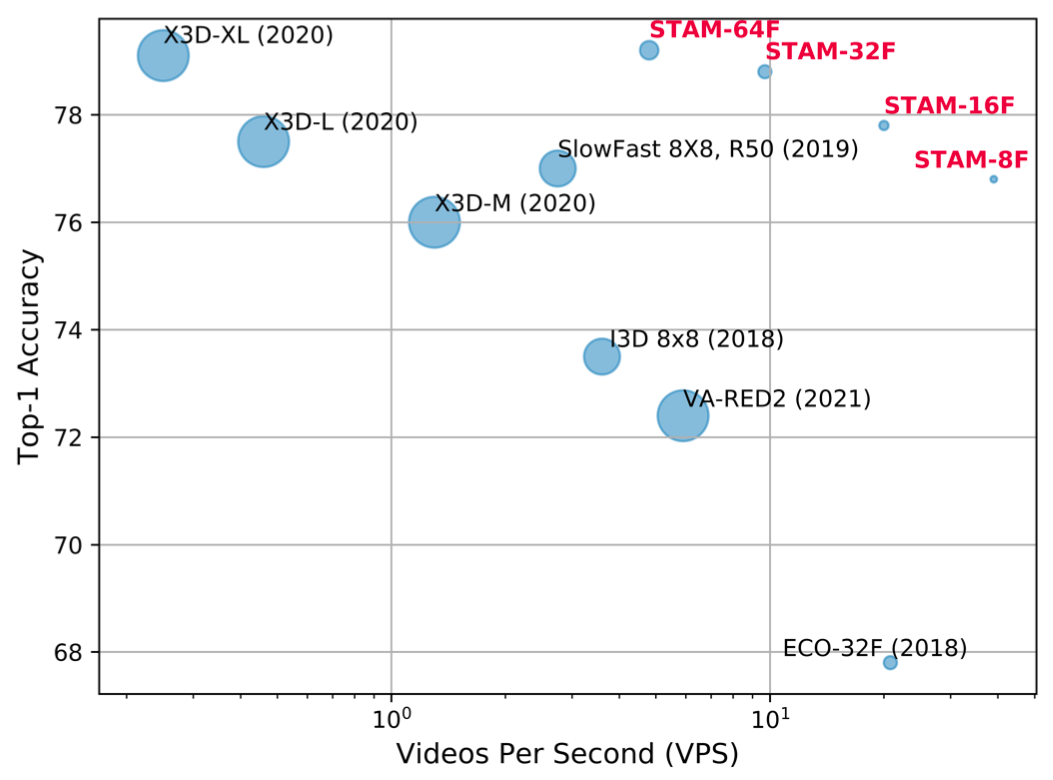
(図は論文より引用)
論文中では 3D CNN ベースのモデルに対して疎なフレームサンプリングを用いた場合は Transformer ベースのモデルと異なり大幅に精度が低下する結果が報告されており、Transformer が時間的に広範囲で疎な入力に向いていることがさらに裏付けられます。
ViViT: A Video Vision Transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lucˇic ́, Cordelia Schmid. ViViT: A Video Vision Transformer. arXiv:2103.15691, 2021.
論文リンク
この論文では Transformer ベースの動画認識モデルの各要素や学習方法に関して、詳細な議論・実験が行われています。
まず、入力動画のトークン化についての二つの方法を比較しています。一つは、動画の各フレームをパッチに分割したものをトークンとし、各トークンを線形写像して埋め込み表現を得る方法 (Uniform frame sampling) で、これまで紹介したモデルと同様の方法です。この処理はパッチの大きさがフィルタサイズとなる 2D 畳み込みと見ることができます。もう一つが、動画を時空間のボクセルに分割したものをトークンとし、各トークンを線形写像して埋め込み表現を得る方法 (Tubelet embeding) です。こちらはボクセルの大きさがフィルタサイズとなる 3D 畳み込みと見ることができます。提案モデルは ImageNet で事前学習された ViT のパラメータを初期値に使用しますが、画像入力を想定して設計された ViT には Tubelet embeding に対応するパラメータが存在しません。そこで、ViTのトークン化に使用される 2D フィルタのパラメータを時間方向に繰り返す初期化方法 (Filter inflation) と 3D フィルタの時間的に中心の部分をのみにコピーし他の部分はゼロ初期化する方法 (Central frame) が取られています。
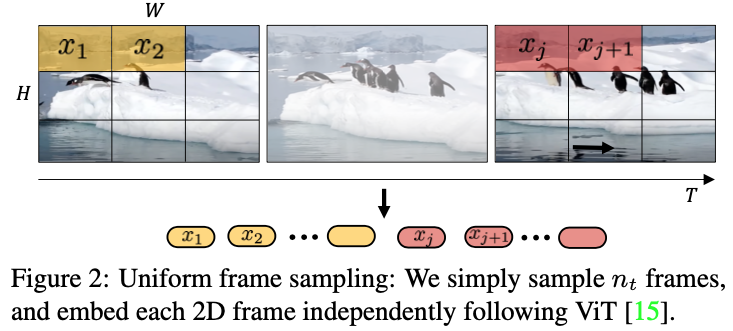
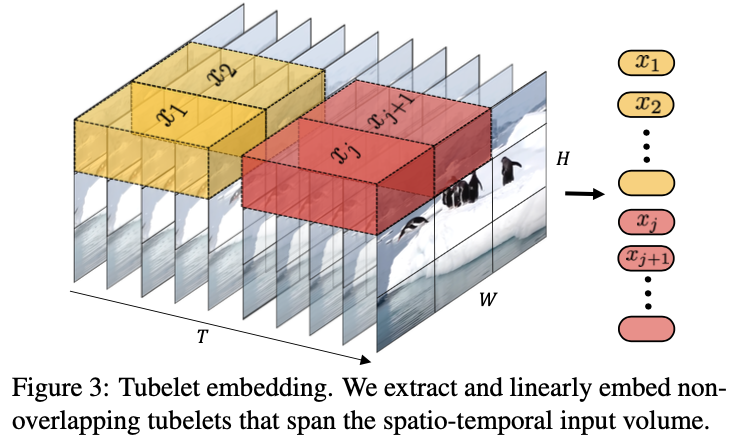
比較実験では、Central frame で初期化されたTubelet embedding が最も良いものの、Filter inflation やランダム初期化と比較すると Uniform frame sampling の方が良い結果となりました。
また、attention の対象範囲に関しても検討がされています。TimeSformer で用いられている Divided Space-Time Attention を含む複数の方法を比較し、Factorised Encoder (下図)という設定が計算コストと精度のトレードオフ観点で優れた結果を残しています。Factorized Encoder は attentionの範囲を同じ時間座標に制限した Spatial Transformer で 時間単位の特徴を抽出した後、それらの関係を考慮する Temporal Transformer に入力する設定で、STAM や VTN と同じ設定です。
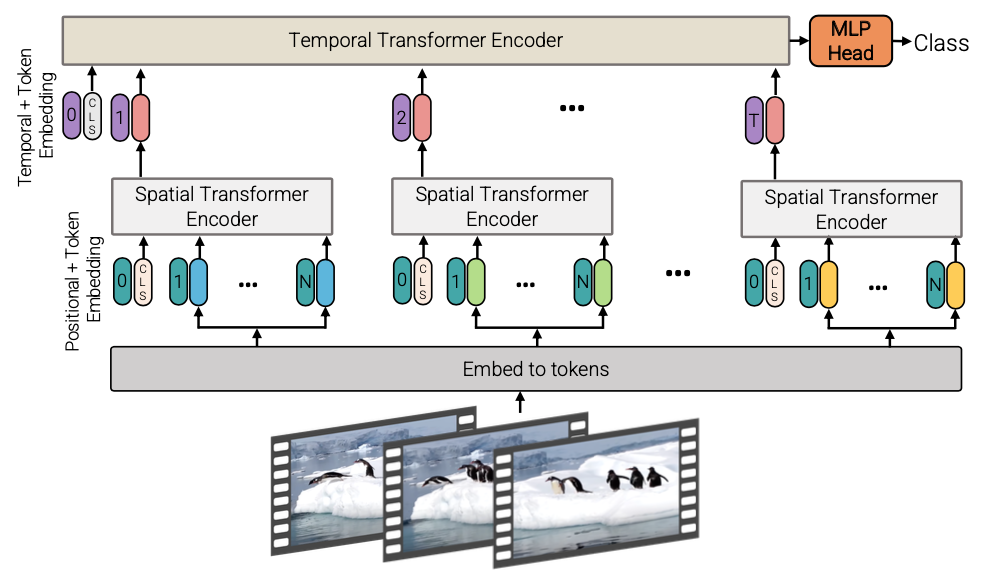
(図は元論文より引用)
さらに、正則化手法や事前学習に関しても実験が行われています。画像や動画のデータ構造に関する事前知識を元に設計された CNN に対して、Transformer ベースのモデルは表現能力が高い反面、小規模なデータセットでうまく学習させるには正則化や事前学習が重要であると述べられています。CNN ベースのモデルにも使用される一般的な正則化に加え、比較的大規模な動画データセットである Kinetics-400 [2] で事前学習を行うことで、特に小規模な動画データセットである Epic Kitchen [8] や SSv2 [7] において精度が大幅に改善し従来手法を超える水準に達しています。
以上の各検討を反映した提案モデル ViViT (Video Vision Transformer) を Kinetics-400 / 600 [3]、Moments in Time [9]、Epic Kitchens-100、SSv2 というメジャーな動画分類データセットで網羅的に評価し、従来手法を超える精度を達成しています。しかし、詳細な動きパターンの認識が重要な SSv2 における評価では Kinetics-400 における事前学習や強い正則化を施しているのにも関わらず、従来手法との差は他のデータセットと比べて僅かでした。ここから、ViViT は詳細な動き特徴の抽出に関して改善の余地があると述べられています。
最後に
Transformer の動画分類への応用が本格的に増え始めたのは、画像認識における Transformer モデルである ViT (Vision Transformer) [4] が登場した去年10月以降のここ数ヶ月のように思います。そのため、今回紹介した論文はプレプリントを多く含み、提案や実験に重複する部分もありました。そういった中で、動画分類における Transformer の性質に関して複数の論文から見えてくることを書いてみようと思います。
まず、Transformer ベースの動画認識モデルは時間的に広範囲で疎にサンプリングされた入力に向いていることが考えられます。 STAM や TimeSformer の研究では、密なサンプリングを要する 3D CNN ベースの手法に対して、入力に使用するフレーム数を大きく減らしたことが計算コストと精度のトレードオフの大幅な改善に寄与しています。
一方で、詳細な動きパターンの認識にはまだ課題がありそうです。疎にサンプリングされた入力の場合に詳細な動きの抽出が難しいのはある意味当然ですが、そうではない ViViT でも 実験結果からこの部分の課題が挙げられていました。
また、Non-local neural networks 以外の研究では、比較手法では使用していない ImageNet-21k [13] という非常に大規模なデータセットで事前学習された ViT のパラメータを転移しており、これが精度向上にかなり効いているように考えられます。スクラッチ学習がうまくいかなかったり (TimeSformer) 、小規模なデータセットでの学習には事前学習に加えて強い正則化が必要だったり (ViViT) と、Transformer ベースのモデルは CNN ベースのモデル以上に多くの学習データが必要であると推測されます。
上記のような課題に対するアプローチの一つとして、最近の画像認識 Transformer モデル において増えている [10][11][12] CNN ベースのモデルで行われてきたような入力に関する事前知識のアーキテクチャへの導入が動画認識 Transformer モデルにおいても進むのではないかと考えられます。
いずれにしても、現時点では NLP で成功した Transformer をほとんど形を変えずに応用してみた、というフェーズなので、今後動画データに対してどう着地していくのかが楽しみです。
参考文献
[1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N Gomez, Ł. Kaiser and I. Polosukhin. Attention is all you need. NIPS, 2017.
[2] J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. CVPR, 2017.
[3] J. Carreira, E. Noland, A. Banki-Horvath, C. Hillier and A. Zisserman. A short note about kinetics-600. CoRR, 2018.
[4] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold. S. Gelly, J. Uszkoreit and N. Houlsby. An image is worth 16×16 words: Transformers for image recognition at scale. ICLR, 2021
[5] I. Beltagy, M. E Peters, and A. Cohan. Longformer: The long-document transformer. arXiv:2004.05150, 2020.
[6] A. Miech, D. Zhukov, J.-B. Alayrac, M. Tapaswi, I. Laptev and J. Sivic. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. ICCV, 2019.
[7] R. Goyal, S. E. Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Fründ, P. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax and R. Memisevic. The “something something” video database for learning and evaluating visual common sense. CoRR, 2017.
[8] D. Damen, H. Doughty, G. M. Farinella, A. Furnari, J. Ma, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price and M. Wray. Rescaling egocentric vision. arXiv:2006.13256, 2020.
[9] M. Monfort, A. Andonian, B. Zhou, K. Ramakrishnan, S. A. Bargal, T. Yan, L. Brown, Q. Fan, D. Gutfreund, C. Vondrick and A. Oliva. Moments in time dataset: one million videos for event understanding. PAMI, 2019.
[10] H. Wu1, B. Xiao, N. Codella, M. Liu, X. Dai, L. Yuan and L. Zhang. CvT: Introducing Convolutions to Vision Transformers, arXiv:2103.15808, 2021.
[11] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin and B. Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv:2103.14030, 2021.
[12] S. d’Ascoli, H. Touvron, M. Leavitt, A. Morcos, G. Biroli and L. Sagun. ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases. arXiv:2103.10697, 2021.
[13] J. Deng, W. Dong, R. Socher, L. Li, K. Li and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. CVPR, 2009.
Author