Blog
CyberAgent AI Lab at ICCV 2021
AI Labの山口です。2021年10月11日から2021年10月17日にかけて、コンピュータビジョン分野の国際会議であるICCV 2021がオンラインで開催されました。弊社プレスリリースでもお伝えしている通り、今回AI Labからは2件のポスター発表をしてきました。この記事では会議の全体概要や傾向を含めて、ICCV 2021でのサイバーエージェントの取り組みをお伝えします。
ICCV 2021全体概要
ICCVは隔年開催され、CVPR、ECCVと並んでこの分野では最も権威のある会議の一つです。2021年は全体で6,152件の投稿があり、1,612件の研究が採択されました(採択率26%)。採択されたもののうち210件はオーラル発表、残りがポスター発表になっていました。著者の所属を国別で見ると中国が全体の43.2%と最も多く、米国23.6%、英国3.6%と続き、日本からは2.0%があったようです。メインの研究発表の他にも基調講演やソーシャルイベントなど様々な催しが開かれ、2つあったパネルセッションでは古典的手法と新しい深層学習系手法についてどのように分野として関わっていくべきか、コンピュータビジョンにおける産業界の役割、といった議論が見られました。

図1: ICCV 2021の発表文献のタイトルから生成したワードクラウド。
研究トピックに着目すると、公式サイトで見られるように、Transfer/Low-shot/Unsupervised learning、Image and video synthesis、Recognition and classificationといったテーマが最も多く見られました。図1は発表タイトル一覧から作成したワードクラウドです。このほかに今年の特徴として個人的に目についたのは、NLP分野での流行からコンピュータビジョン分野でもよく見かけるようになったTransformerアーキテクチャを使った研究、大規模データセットでの自己教師あり学習に関する研究、そして3Dデータに対するニューラルネットワークの応用があったように思います。TransformerはMarr Prizeを受賞したSwin Transformerをはじめ、数多くの発表でモデルに採用されていました。自己教師あり学習はCLIPのように大規模データセットからの事前学習により汎用的なモデルが学習できることが近年示されていることから、トピックの流行が続くのではないかと思われます。また、昨年のECCV 2020の発表から引き続いて急速に研究が進展しているNeRFや3Dシーン復元、3Dデータセットに関する研究が受賞しています。
AI Labからの発表
AI Labからはクリエイティブ制作に関する2件の研究を発表してきました。
De-rendering Stylized Texts

図2: 入力となるラスタ画像からテキストのレンダリングに必要なベクトル情報を復元、再編集を可能にします。
ポスターやバナー広告などのデザインドキュメントは、一度ラスタ画像としてピクセルに描画されてしまうと再編集することが難しくなります。本研究ではラスタ化されたテキストをベクター形式に再構成するための手法を開発しました。ベクター形式に変換するにあたっては文字を認識するだけではなく、その文字を描画する際に指定されたスタイリング情報や位置情報を正確に予測し、さらにテキストの後ろに隠れている背景まで推定しなければなりません。本研究ではテキストのベクター形式の情報をフィードフォワードで推論するモデル、フィードバックで推定結果を調整するモデルを組み合わせ、高い精度でテキストをベクター形式に再構成する手法を提案しています。これにより、例えば既存の広告効果が高いバナー広告を再利用して、広告効果が高そうなデザインを迅速に制作するようなワークフローが可能となります。
CanvasVAE: Learning to Generate Vector Graphic Documents

図3: CanvasVAEはグラフィックドキュメントをランダム直接生成する他、中間的なデザインを補間して生成することもできます。
近年GANなどの生成モデルを用いて情景や顔の画像を生成する手法が提案されてきましたが、バナー広告などのベクター形式のドキュメントを直接生成するような手法は見られませんでした。本研究では初めてベクター形式のドキュメント構造を直接生成するようなモデルを提案、そしてその研究のためのデータセットを公開しました。CanvasVAEではランダムにドキュメントテンプレートを生成したり、複数のドキュメントの中間的なデザインを生成したりすることができます。この手法を発展させることで、例えばバナー広告のようなデザインドキュメントを自動生成することが可能になると期待されます。
注目する研究発表
AI Labからの発表以外にもICCVでは数々の興味深い研究発表が見られました。ICCVの発表の全部を紹介することはできませんが、クリエイティブに関する発表数件を以下に紹介したいと思います。
LayoutTransformer: Layout Generation and Completion With Self-Attention
図4: LayoutTransformerは自己再帰型で逐次的にレイアウトを生成する。(論文Fig 1より引用)
Maryland大学のGuptaらによる研究、自己再帰型のTransformerを利用して2Dドキュメントや3D物体の形状など様々なレイアウトを生成させています。
DocFormer: End-to-End Transformer for Document Understanding

図5: DocFormerによるシーケンスラベリング(要素のラベリング)の結果。(論文Fig 4より引用)
書類などのドキュメント画像を理解するため、Transformerベースのモデルで教師なし学習し、ドキュメント分類や要素抽出といった4種類のタスクで性能評価を行なった研究。テキスト、見た目、空間配置に関する相互作用をうまく扱うことで全てのタスクで高い性能を達成したことを報告しています。
Unsupervised Layered Image Decomposition Into Object Prototypes
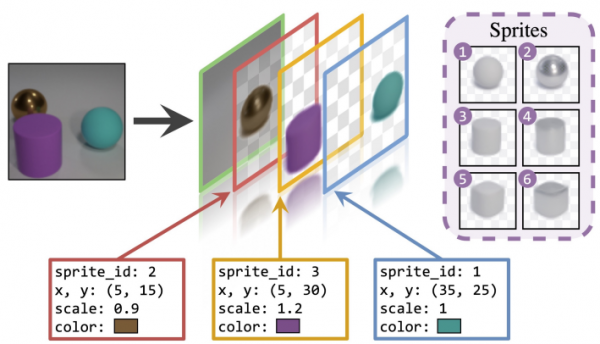
図6: 画像をSpriteに分解(論文Fig 1より引用)
教師なしで画像をSpritesと呼ばれるレイヤー単位に分解する、ベクター化の手法の一種を提案しています。微分可能なSpriteの合成により再構成誤差を少なくするように学習を進めます。
おわりに
AI Labではクリエイティブ制作ワークフローを変革する研究開発に取り組み、研究成果の一部は極予測AI、極予測AI人間、極予測トリミングといったサービスに利用されています。CVPR 2021に引き続き、ICCV 2021でもクリエイティブ制作に関連する研究発表が複数見受けられました。AI Labはクリエイティブ制作に関わる研究をリードする存在として今後も難易度の高い研究プロジェクトに取り組んでいく予定です。
プレスリリース記事
Author