Blog
ACMMM2021 参加報告
AI Lab の鈴木智之 (@tomoyukun) です。10月末に開催されたマルチメディア分野の国際会議である ACM MultiMedia (ACMMM) 2021に参加してきました。AI Lab からはレイアウト生成に関する早稲田大学との共同研究成果について Main track にてオーラル発表 (*1) がありました。また、AI Lab の研究員で構成されたチームが会議に併設されたMultimedia Grand Challenge の動画広告認識コンペティションに参加し受賞 (*2) しました。本記事では会議の概要と気になった研究発表について報告します。
*1 AI Lab、マルチメディア分野のトップカンファレンス「ACM Multimedia」にて共著論文採択 ー最適化による制約を満たしたレイアウトの生成手法を提案ー
開催概要
ACMMM はマルチメディア分野のトップカンファレンスの一つです。いわゆる本会議である Main track の今年の投稿数は 1942 件、採択数は 542 件で採択率は 28% でした。そのうちオーラル発表は 179 件で投稿数された論文のうちの 9.2% となりました。他の情報系トップカンファレンス同様、投稿数は増加傾向にあり分野への関心が依然として高まっていることが伺えます。
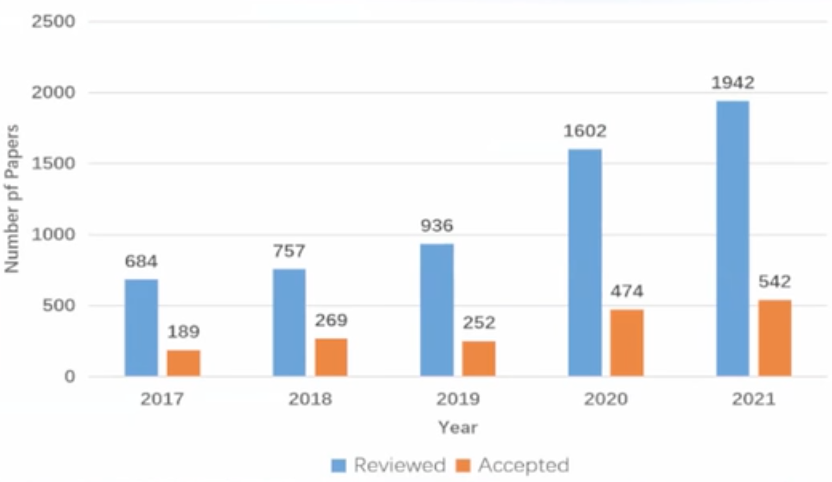
(図は会議の Opening Ceremony より引用)
会議のハイライトの一つに「Scientific Diversity」を掲げているように、機械学習を用いて多様なデータモダリティの生成・認識を行う取り組みから新しいソフト・ハードウエアの開発に関するものまで非常に幅広い研究トピックが扱われていました。また、Main track の研究発表に加え、今回初めて設けられた Industrial track、その他 Demo session / Multimedia Grand Challenge / OSS competition など学術研究から産業応用的な内容の発表まで網羅されており、非常に聞き応えがありました。
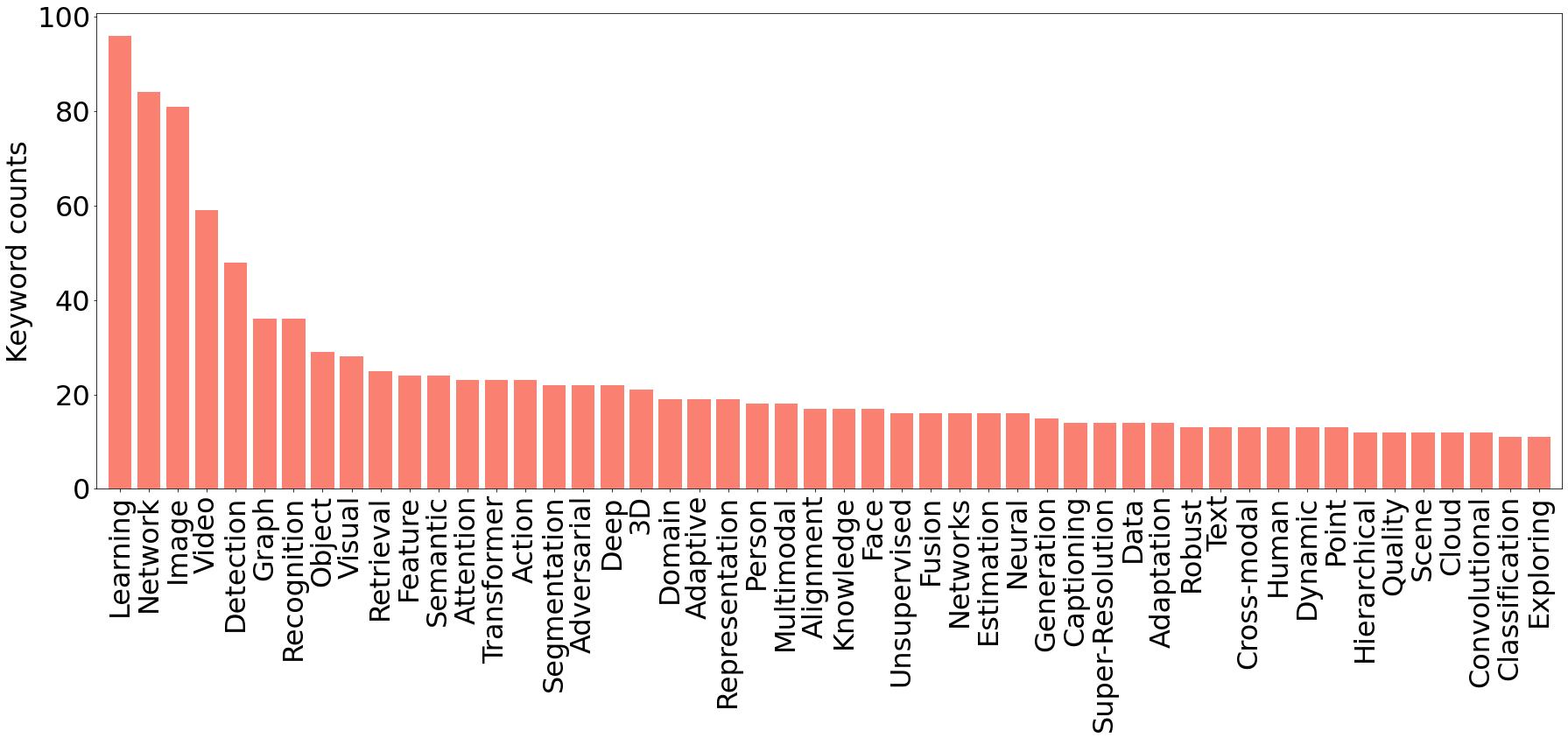
上の図は Main track に採択された論文タイトルから抽出した上位50の頻出キーワードのヒストグラムです。データモダリティに着目すると Image / Video / Visual などのワードが目立ち、多様なデータモダリティを扱う研究が集まる ACMMM の中でも、画像・動画データへの注目度が高いことが伺えます。また手法に着目すると Attention / Transformer をキーワードに含む研究が多いことがわかります。Transformer は様々な入出力形式を扱うことができる汎用性の高いアーキテクチャであるため、扱うデータに関わらず使用している研究はとても多く見られました。
開催形式に関してですが、バーチャル開催であった昨年に対して今年はバーチャルとオンサイト (中国、成都市) 参加が選択可能なハイブリッド開催で、AI Lab からはバーチャル参加をしました。バーチャル参加者は基本的にオンサイトで行われるオーラルセッションのライブを見て、チャットで質問をするという参加スタイルです。ポスターセッションはオンサイトでしか実施されず、バーチャル参加者は事前に録画されたプレゼンテーション動画・ポスター・Proceedings にアクセスできるのみでした。Whova というイベント運営アプリを通して、チャット形式で著者に質問ができるようになってはいましたが、実際に質問や議論がされている発表はかなり少なく寂しい感じとなっていました。ハイブリッド開催によってオンサイト参加が選択できるようになったことは喜ばしい一方で、やはりバーチャル側の置いていかれている感という課題は出てくると感じました。早く情勢が落ち着き、気兼ねなくオンサイト開催ができるようになることを祈りたいです。
その他印象的だったのは、採択論文の著者のうち中国人著者が 74% 以上も占めていたことでした。中国開催ということで投稿数も多かったかもしれませんが、マルチメディア分野における中国の勢いを感じます。
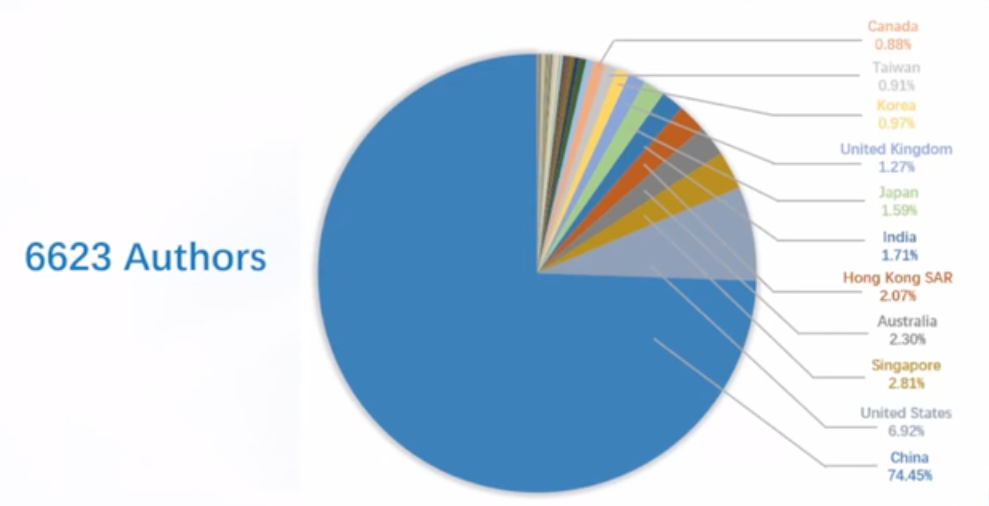
(図は会議の Opening Ceremony より引用)
注目する発表
上述のように多様なセッションで多くの興味深い発表がされていましたが、ここでは Main track、Industrial track、Demo session の中から受賞論文を含むマルチメディアデータの生成・認識に関する注目発表を簡単に紹介していきます。
生成系
Video Background Music Generation with Controllable Music Transformer
[Best Paper Award]
Shangzhe Di, Zeren Jiang, Si Liu, Zhaokai Wang, Leyan Zhu, Zexin He, Hongming Liu, Shuicheng Yan
Proceedings、arXiv、コード、プロジェクトページ
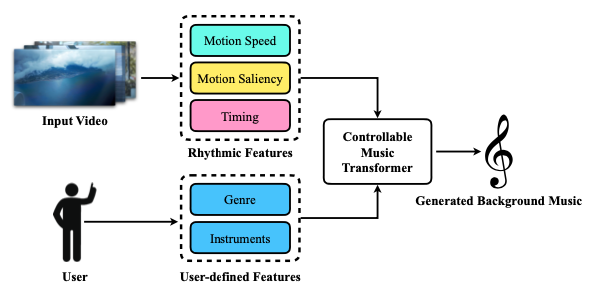 (図は元論文より引用)
(図は元論文より引用)
Best Paper Award を受賞したのは映像に合うBGMの生成に関する研究でした。リズム・ジャンル・楽器の情報を条件とする音楽生成モデルに、映像の動きから計算したリズム情報とユーザが指定するジャンル・楽器情報を入力することで映像に合うBGMを生成します。音楽生成モデルは Transformer をベースとし、既存の公開データセット Lakh MIDI Dataset で学習しています。一方で映像の動きからリズムへの変換は hand-craft に設計された情報を用いたルールで行われます。生成されたサンプルはプロジェクトページで見ることができます。提案手法が考慮しているのは映像の動きとBGMのテンポの対応のみですが、BGM生成という難しい課題のできそうな部分に焦点を当て、学習とルールに上手く分けて解き、結果として高い品質で生成を実現したことが高い評価につながったのではないかと思います。
Learning Fine-Grained Motion Embedding for Landscape Animation [Main track]
Hongwei Xue, Bei Liu, Huan Yang, Jianlong Fu, Houqiang Li, Jiebo Luo
Proceedings、arXiv

(図は元論文より引用)
画像からタイムラプス動画を生成する研究です。隣接フレームから計算されたオプティカルフローを潜在表現に埋め込むエンコーダと潜在表現とフレーム画像からオプティカルフローを再構成するデコーダを学習します。ここで semantic segmentation により分割された領域ごとに潜在表現が抽出され、デコードの際にも領域ごとに異なる潜在表現が用いられます。こうすることで、画像全体に似た方向の動きを付与してしまう傾向にある従来の手法に対して、領域ごとに異なる動きの付与が可能となっています。また、高い生成品質を実現するために Flickr から 10000 件以上の高解像度なタイムラプス動画を学習データ用に収集しています。
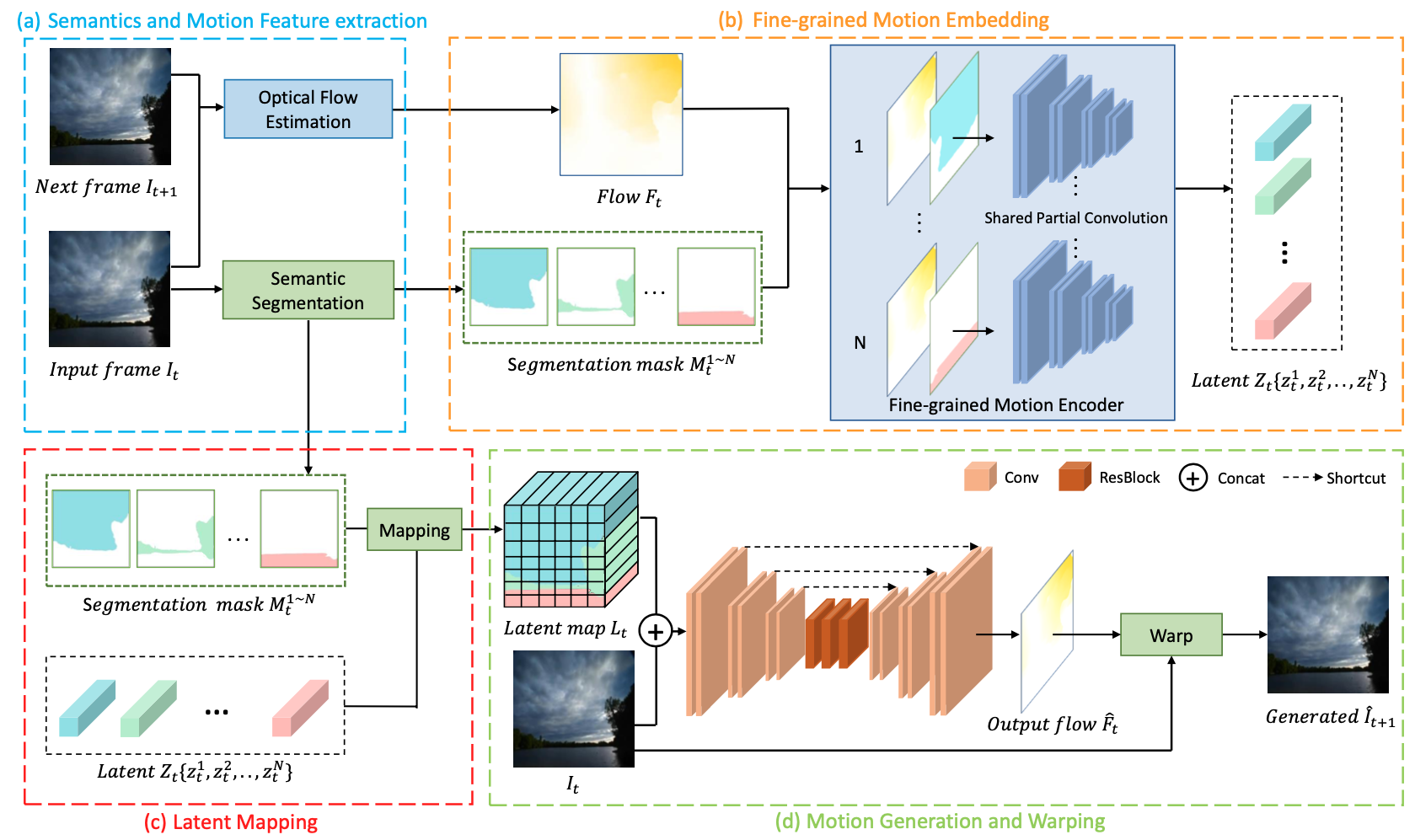
(図は元論文より引用)
Diverse Multimedia Layout Generation with Multi Choice Learning [Main track]
David D. Nguyen, Surya Nepal, Salil S. Kanhere
Proceedings
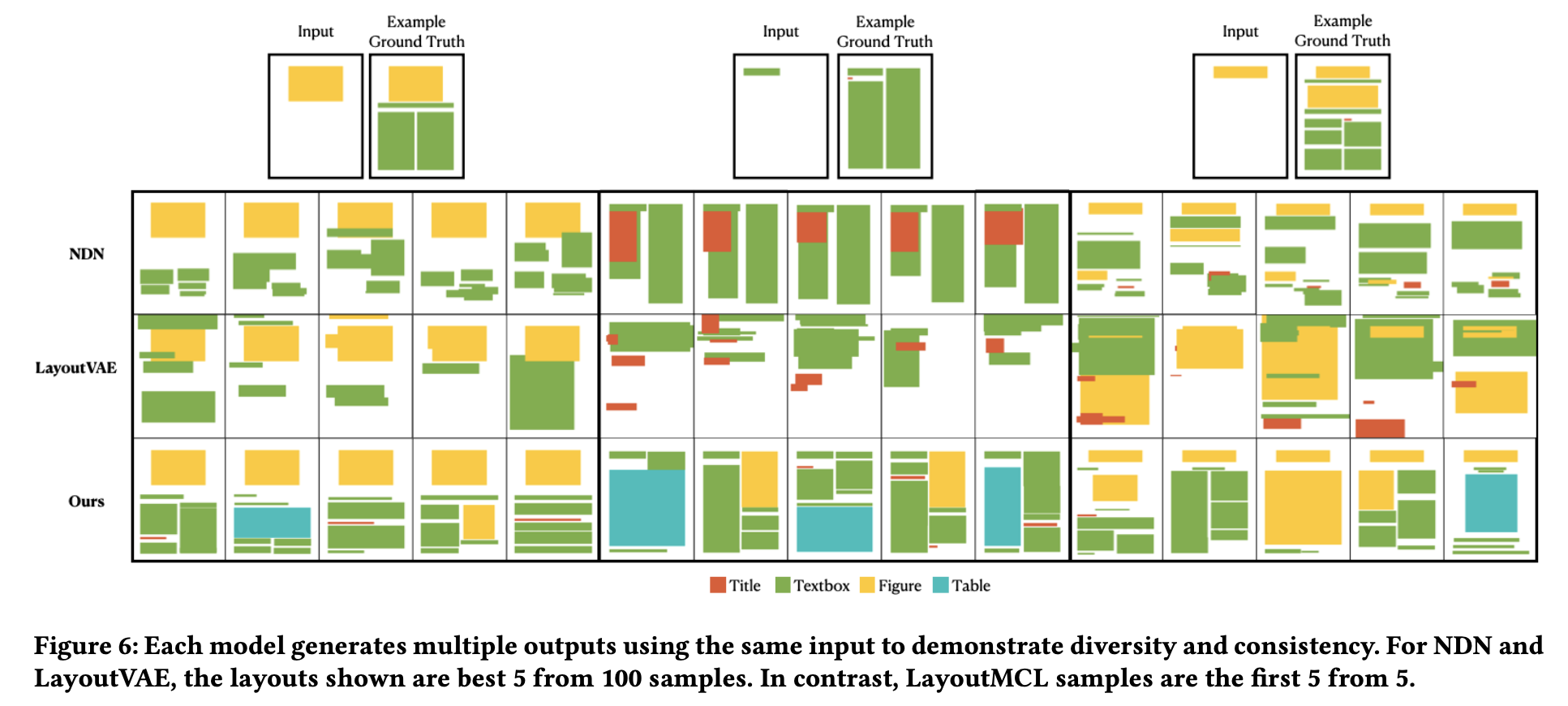
(図は元論文より引用)
自己回帰ベースのレイアウト生成に関する研究です。自己回帰モデルは、これまでの出力結果(レイアウト生成の場合は要素の位置情報など)を元に次の出力をするステップを繰り返して全体に対する出力を行います。レイアウト生成における要素の配置のように本来多様な解が考えられる問題において、単一の教師に近づくように自己回帰モデルの学習を行うと平均的な生成を行うモデルとなり、結果として生成の品質と多様性が損なわれる問題が存在します。そこで、この研究ではモデルに複数の候補を出力させ最も教師に近い候補のみにロスをかける学習方法が提案されています。また、複数の候補を選択するモデルも学習しテスト時に使用しています。実験では従来手法と比較して、生成品質と多様性が共に改善されていることを示しました。出力の多様性を生かした要素配置の推薦とユーザによる選択を繰り返すインタラクティブなレイアウト生成システムのデモも行われています。
Move As You Like: Image Animation in E-Commerce Scenario [Demo session]
Borun Xu, Biao Wang, Jiale Tao, Tiezheng Ge, Yuning Jiang, Wen Li, Lixin Duan
Proceedings
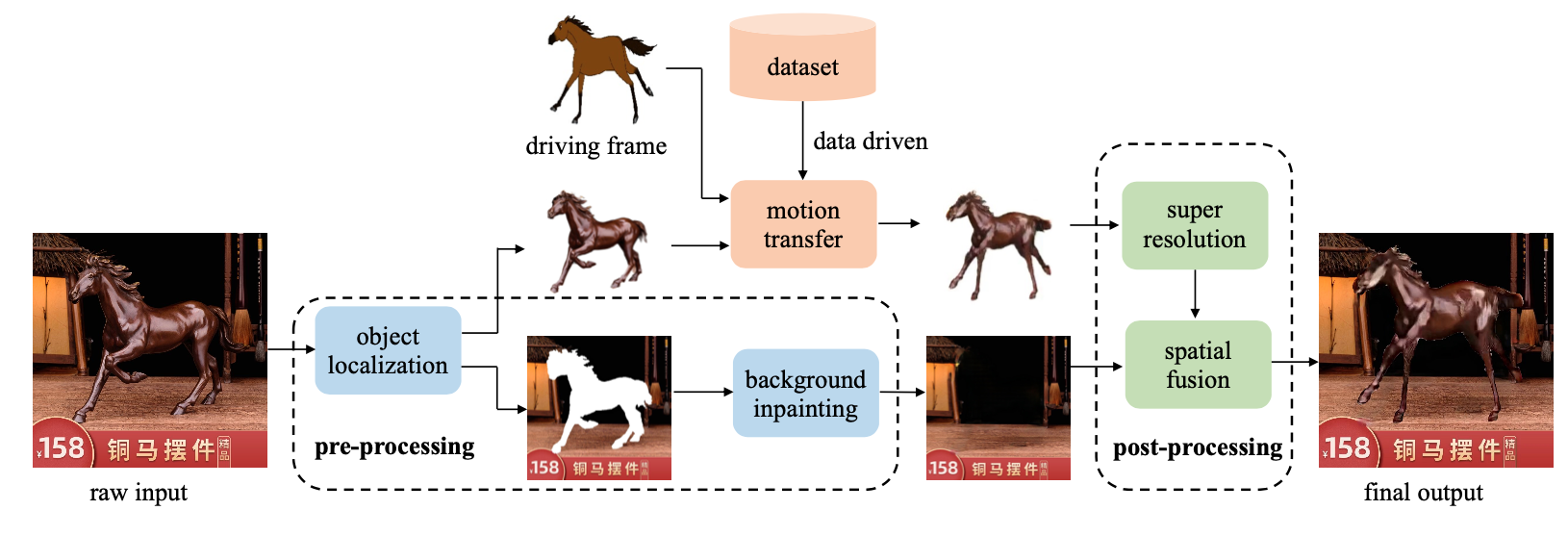
(図は元論文より引用)
ECサイトに表示される商品画像中の商品に動きを付与 (motion transfer) する取り組みです。提案システムは基本的に既存手法の組み合わせですが、これまでの motion transfer の研究の多くは人や人の顔など限定されたものを対象としてきたのに対してこの取り組みでは幅広い種類の物体を対象としています。まず、商品画像が含まれる前景領域 (source image) を切り出し、残った画像は背景画像として補完しておきます。次に、データセットから動きがついた同じ種類の物体 (driving image) を抽出し FOMM [Siarohin +, NeurIPS2019] という既存の手法によって source image に動きを転移します。最後に背景画像に動きのついた source imageを貼り付けます。動かしたい対象と同じ物体カテゴリの driving image がデータセットに含まれる必要があり対応範囲のスケールに関しては厳しさがあるものの、生成されたサンプルは魅力的でECサイトなどで見かけたらついクリックしてしまいそうな気がします。実際の生成結果は Proceedings の Supplemental Material で見ることができます。
 (図は元論文より引用)
(図は元論文より引用)
認識系
PIMNet: A Parallel, Iterative and Mimicking Network for Scene Text Recognition
[Best Paper Candidates]
Zhi Qiao, Yu Zhou, Jin Wei, Wei Wang, Yuan Zhang, Ning Jiang, Hongbin Wang, Weiping Wang
Proceedings、aiXiv、コード(公開予定)
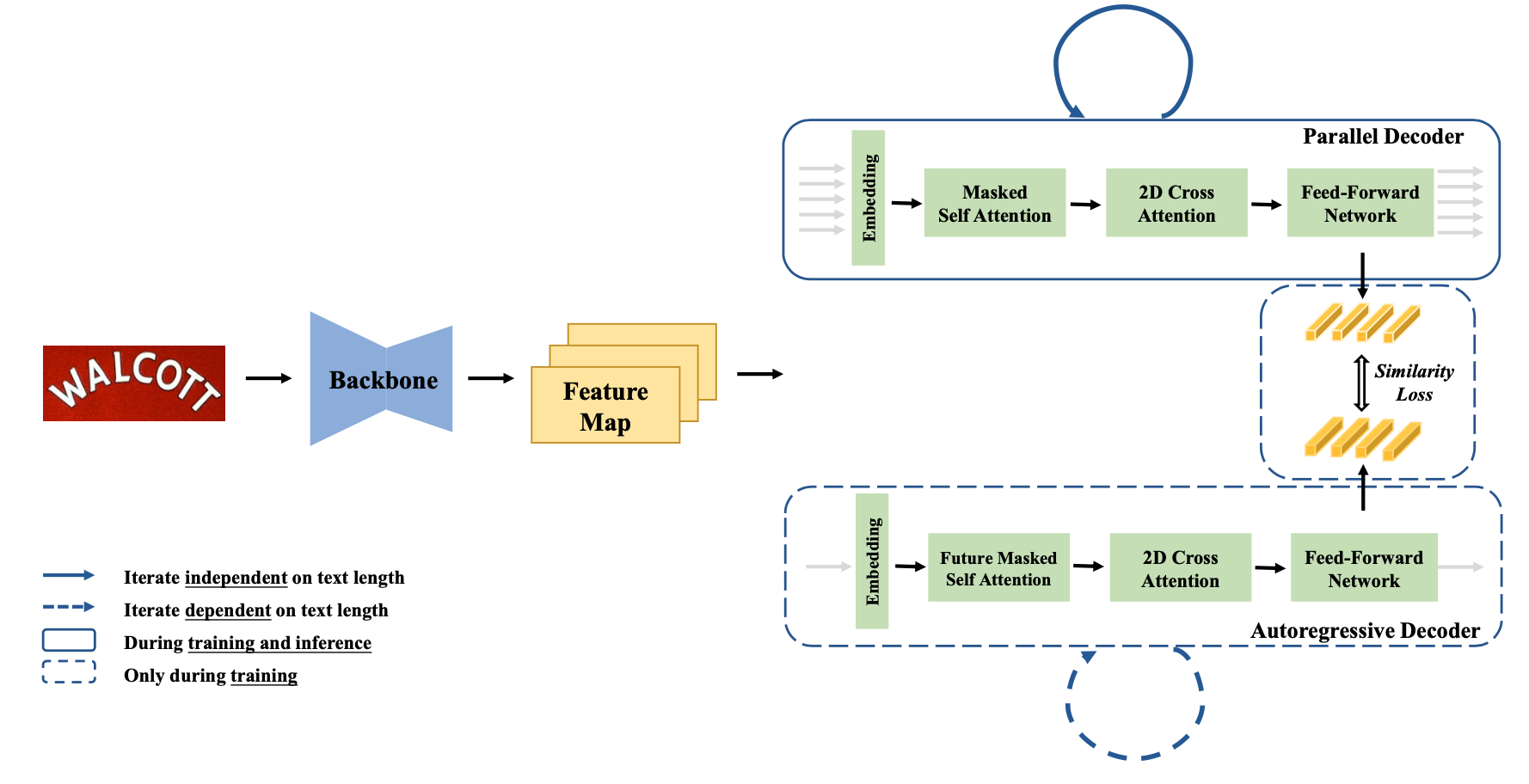 (図は元論文より引用)
(図は元論文より引用)
画像からテキストを検出・認識する scene text recognition において精度と処理コストのトレードオフを大幅に改善した研究です。一般に、検出された領域のテキストを認識する際に各文字 (charactor) を自己回帰的に認識するモデルは、各文字を並列に認識するモデルに対して高精度な一方で処理コストが高い傾向にあります。そこでこの研究では並列モデルと自己回帰的モデルをバックボーンを共有する形でそれぞれ学習し推論は並列モデルのみを用いて行うことで、軽量な並列モデルに対して自己回帰的モデルの知識を転移させる方法を提案しています。
Once and for All: Self-supervised Multi-modal Co-training on One-billion Videos at Alibaba [Industrial session]
Lianghua Huang, Yu Liu, Xiangzeng Zhou, Ansheng You, Ming Li, Bin Wang, Yingya Zhang, Pan Pan, Yinghui Xu
Proceedings
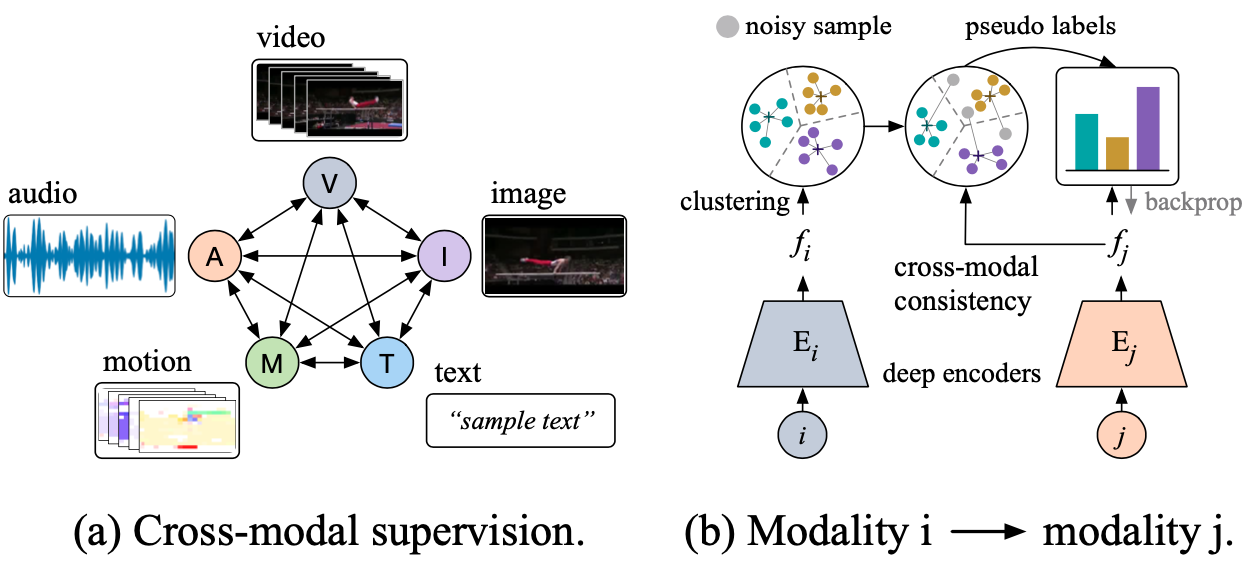
(図は元論文より引用)
Alibaba からマルチモーダル動画データを用いた事前学習手法の提案と、自社で保有する大規模マルチモーダル動画データを用いた実験に関する発表です。提案する事前学習手法はあるモーダルのエンコーダから得られる特徴表現をクラスタリングし、その結果を擬似的なクラスラベルとしてその他のモーダルのエンコーダを学習する、というものです。超大規模な動画データセット (0.5 PB、1.4億 動画) での学習を実現するために行った、並列化を駆使した処理の効率化についても紹介されています。実験では動画行動分類、画像分類の公開データセット (UCF101、ImageNet) への転移学習による精度向上のみならず、Alibaba の実プロダクトにおける推薦システムへの応用によりA/Bテストで測定したビジネス指標 (PV数、CVR 等) が改善されたことまで示されています。
Alibaba はその他にも Main track でECサイトにおける商品の画像・テキスト・属性情報を用いたマルチモーダルモデルの事前学習に関する研究発表 [Zhu +, ACMMM2021] 、Keynotes で中国語テキストと画像のコーパスで学習された中国語版マルチモーダル学習済みモデル M6 [Lin +, KDD2021] とその派生研究 (M6-T [Yang +, 2021]、 M6-10T [Lin +, 2021]、 UCF-BERT [Zhang +, NeurIPS2021]) について紹介 [Zhou +, ACMMM2021] していたりと、大規模データを用いたマルチモーダル学習済みモデルの構築にかなり力を入れていることが伺えました。
Efficient Multi-Modal Fusion with Diversity Analysis [Main track]
Shuhui Qu, Yan Kang, Janghwan Lee
Proceedings
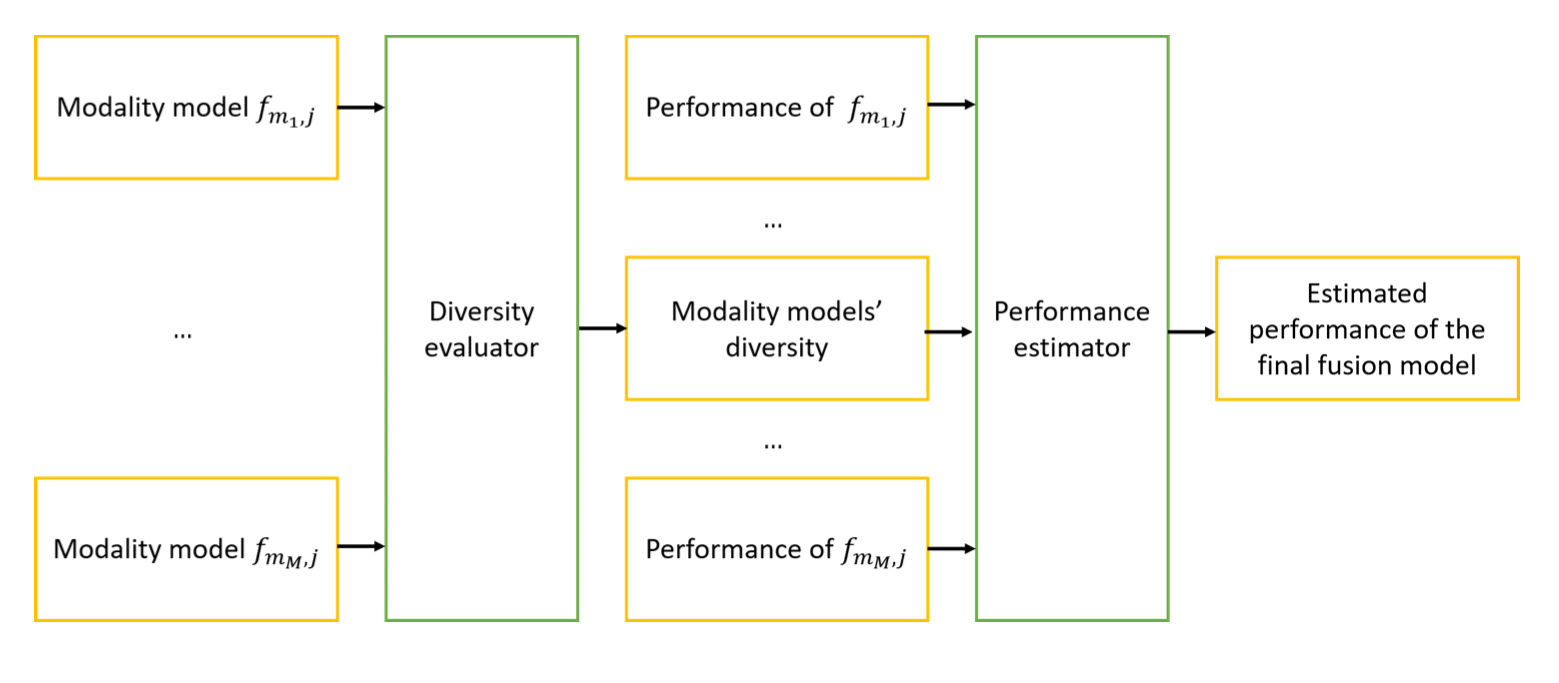 (図は元論文より引用)
(図は元論文より引用)
マルチモーダルモデルの性能分析に関する研究です。各モーダルのエンコーダ (ブランチ) 単体の性能が高くそれらの多様性が大きいほどマルチモーダルモデルの性能が高くなることを理論的に示し、実験で確認しています。さらにこの定理を元に各ブランチの選択方法を提案し、マルチモーダルモデルの性能向上を達成しています。マルチモーダルモデルは入力がリッチになる一方で多様な形式のデータを一つのモデルで扱う必要があるため学習が難しいことが知られています。場合によってはユニモーダルモデルの方が高い性能を示すという結果も報告されており、ヒューリスティックな学習方法の工夫による対処等が提案されています [Wang +, CVPR2020]。この問題に対して本研究のような理論的な側面での分析も進んでいくことを期待したいです。
おわりに
ACMMM には今回初めて参加しましたが、実応用を意識した内容が多い印象で、CVPR や NeurIPS のような (ACMMM と比較して) 基礎的な内容の研究発表も多い会議とはまた少し違った学びが多かったように思います。特に実データ特有の問題を扱った研究やアプリケーションへの実装まで行っている研究は興味深いものが多くありました。また、企業からの研究発表ではその企業の技術的ビジョンが伺えるようなものもあり参考になりました。
AI Labでも基礎的な内容から実応用を強く意識したものまで幅広い研究プロジェクトに取り組んでいます。ご興味ある方はぜひ採用ページもご覧ください。
Author