Blog
テキストの多様性を測る評価指標
こんにちは。リサーチサイエンティストの村上(@ichiroex)です。
現在、AI Lab NLPチームで広告文生成の研究に取り組んでいます。
はじめに
近年、GPT-3やT5などの事前学習された大規模言語モデルの登場により、言語生成技術は飛躍的な進歩を遂げています。最近では、Hugging Face社のTransformersを活用して、様々な研究者・団体から事前学習済みモデルが公開されるようになり、我々の研究やプロダクト開発においても言語生成技術がより身近になっています。
生成モデルの研究開発では、生成したテキストを様々な観点で評価することが一般的です [1]。例えば広告文生成では、評価指標の1つとして、商品やサービスの魅力をより豊かな言い回しで伝えるために、生成テキストの多様性が重要視されています。
具体的には以下のように、同じ広告訴求(商品数の豊富さ、送料無料)でも言い回しが異なればユーザーに与える印象もそれぞれ変わるため、生成モデルがどのくらい多様なテキストを生成できるかを事前に評価することは大切です。
・No.1の品揃え/送料はタダ!
・日本一の豊富な商品数/送料0円
・取扱商品数No.1の実績/送料無料
しかし、多くの言語生成に関する研究において、既存の生成モデルでは同一テキストや限られた語彙、フレーズが生成されやすいといった課題が指摘されています。そのため、現在の言語生成の研究では、生成テキストのN-gram一致率に基づく評価指標を用いて多様性を測ることが一般的です。
そこで今回の記事では、生成テキストの多様性を測る評価指標として広く用いられているdistinct-N、Self-BLEU、Pairwise-BLEUを紹介します。
distinct-N
distinct-N [2]は、モデルが生成した全テキストのN-gramにおけるユニークなトークン数と総トークンの比であり、以下の式により計算されます。
$$distinct–N=\frac{number\ of\ distinct\ N–grams\ in\ generated\ text}{total\ number\ of\ generated\ N–grams}$$
ここで、distinct-Nの“N”は、N-gramの“N”を表しており、uni-gram、bi-gramを用いる場合はそれぞれdistinct-1、distinct-2などと表記します。
上記の式の通り、distinct-Nはスコアが高いほど、モデルが生成した全テキストにおいて異なるN-gramが多く含まれていることを表すため、多様なテキストを生成できているかを評価することができます。
distinct-Nは元々、Liら [2] が提案した対話システムの発話の多様性を測るために実験で使用されていた指標ですが、対話システムに限らず様々な言語生成タスクで用いられています。
Self-BLEU
Self-BLEU [3] は、機械翻訳タスクで広く用いられるBLEU [4]を活用した評価指標です。BLEUは生成テキストと参照テキスト(正解テキスト)のN-gramの一致率に基づく評価指標であり、2つのテキスト間の類似度を測ることができます。
Self-BLEUでは生成テキスト集合の中で1つを生成テキスト、それ以外を参照テキストとしてBLEUを算出します。
具体的には図1のように、生成テキスト集合のうち、hyp1を生成テキスト、それ以外のテキスト(hyp2, hyp3等)を参照テキストとしてそれぞれBLEUを算出します。hyp1について全てのペアでBLEUを算出した後は、hyp2を生成テキスト、それ以外(hyp1, hyp3等)を参照テキストとして、同様にBLEUを算出します。
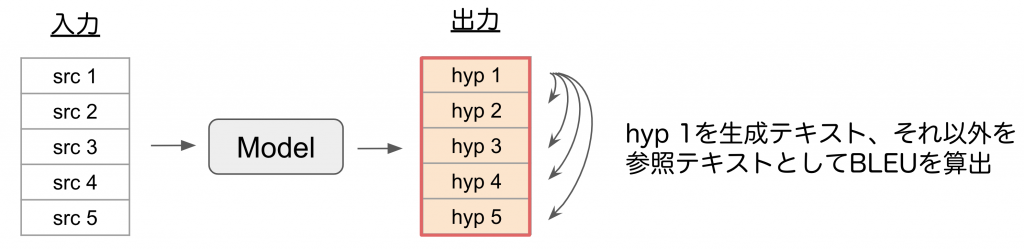
図1: Self-BLEUの算出例
このように、生成テキスト集合の全てのペアに対してBLEUを算出し、全てを平均したスコアがSelf-BLEUです。
BLEUは、スコアが高いほど2つのテキストの類似度が高いことを表します。つまり、多様性を測る観点においては、Self-BLEUのスコアが低いほどモデルは全体的に異なるテキストを生成できていることを表すため、多様性が高いといえます。
また、Sunら [5]の言い換え生成(Paraphrase generation)に関する研究では、入力テキストに対して出力テキストでどの程度言い換えできているかを測るために入出力ペアのBLEUを算出する評価指標を用いており、この指標もSelf-BLEUと呼ばれています。Sunらが用いているSelf-BLEU[5]は、今回紹介したSelf-BLEU[3]と異なるため注意が必要です。
Pairwise-BLEU
Pairwise-BLEU [6] は、Self-BLEUと同様にBLEUを活用した評価指標です。Pairwise-BLEUでは、各入力に対してモデルが複数テキストを生成する状況を前提としており、生成された複数テキストにおける多様性を測ることができます。
具体例として下図のように、各入力(e.g, src 1)に対してBeam search decoding等で複数テキスト(e.g., hyp 1a, hyp 1b, hyp 1c, hyp 1d)を生成するモデルを考えます。
Pairwise-BLEUでは、1つの入力テキスト(src 1)に対して生成された複数テキストのうち、hyp 1aを生成テキスト、それ以外(hyp 1b, hyp 1c, hyp 1d)を参照テキストとして、各ペアでBLEUを算出します。
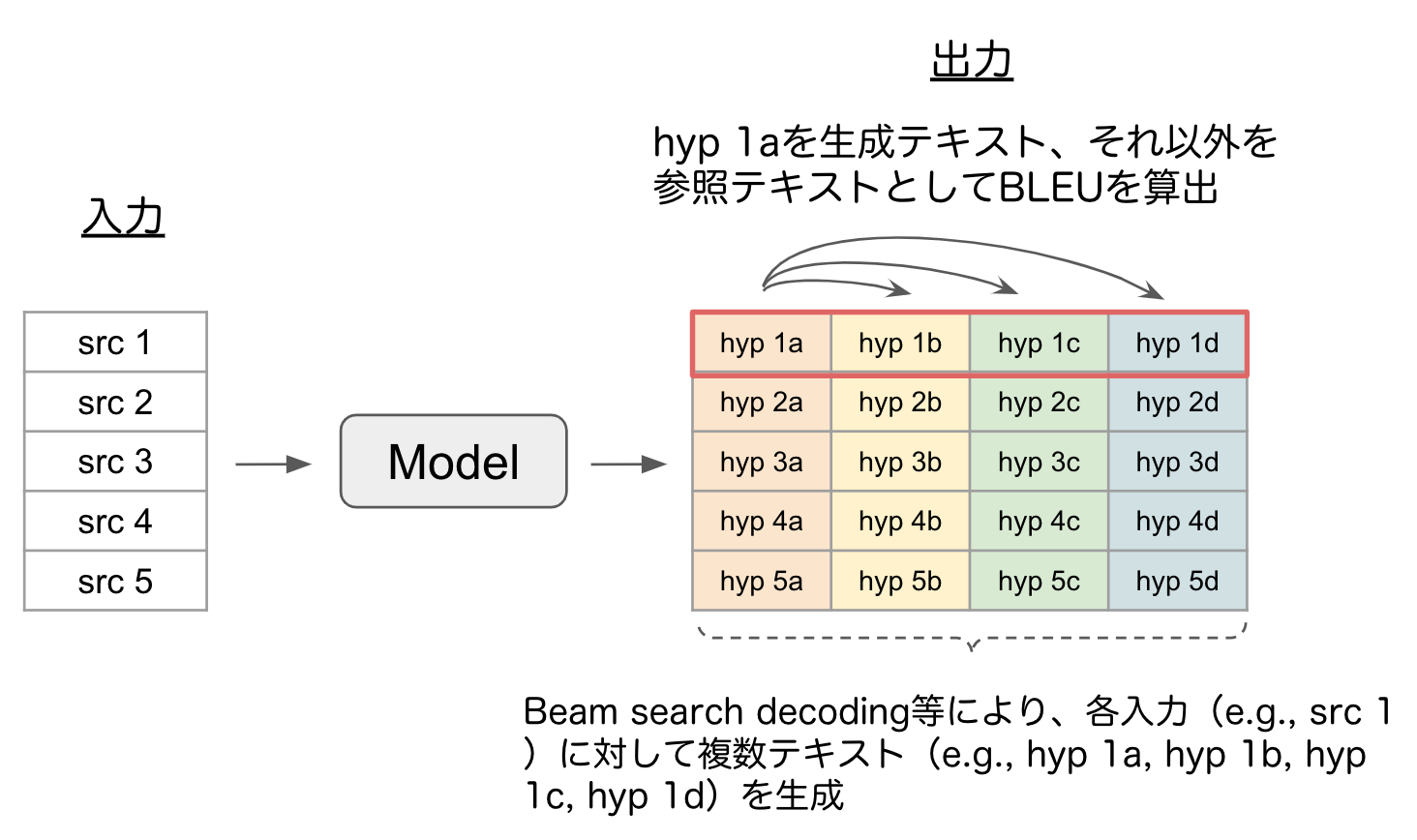
図2: Pairwise-BLEUの算出例
上記の手順を繰り返し、全てのペアのBLEUを平均したスコアがPairwise-BLEUです。Pairwise-BLEUではスコアが低いほどモデルが1つの入力テキストに対して異なる複数パターンのテキストを生成できていることを表すため、多様性が高いといえます。
おわりに
本記事では、テキストの多様性を測る評価指標であるdistinct-N、Self-BLEU、Pairwise-BLEUを紹介しました。今回紹介した3つの評価指標は、いずれもN-gramに基づいた手法であり、生成テキストにおいて異なるN-gramが多いほど多様性が高いというアイデアに基づいています。
しかし、生成テキストの言語表現が多様になったとしても、本来伝えたかった「内容」まで大きく変わってしまうと本末転倒です。そのため、BERTScore [7]などの意味の類似度を測る指標や人手評価などを用いて総合的に生成テキストを評価することが大切です。
参考文献
[1] Celikyilmaz, Asli, Elizabeth Clark, and Jianfeng Gao. “Evaluation of text generation: A survey.” arXiv preprint arXiv:2006.14799 (2020).
[2] Li J, Galley M, Brockett C, Gao J, Dolan B “A Diversity Promoting Objective Function for Neural Conversation Models” Proceedings of NAACL-HLT 2016, pp. 110-119, 2016.
[3] Zhu, Yaoming, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu. “Texygen: A benchmarking platform for text generation models.” In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 1097-1100. 2018.
[4] Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. “Bleu: a method for automatic evaluation of machine translation.” In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pp. 311-318. 2002.
[5] Sun, Hong, and Ming Zhou. “Joint learning of a dual SMT system for paraphrase generation.” In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 38-42. 2012.
[6] Shen, Tianxiao, Myle Ott, Michael Auli, and Marc’Aurelio Ranzato. “Mixture models for diverse machine translation: Tricks of the trade.” In International conference on machine learning, pp. 5719-5728. PMLR, 2019.
[7] Zhang, Tianyi, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. “Bertscore: Evaluating text generation with bert.” arXiv preprint arXiv:1904.09675 (2019).
Author