Blog
マルチメディアと推薦システム
こんにちは。AI Lab Media Fundamentalsチームの汪です。
この記事では、マルチメディアコンテンツを利用した推薦システムに関する研究を紹介します。
はじめに
現在、様々なウェブサービスに、画像、映像、テキスト、音声など豊富なマルチメディアコンテンツが蓄積されています。例えば、YouTube、ソーシャルメディア、オンライン広告などがあります。膨大なマルチメディアコンテンツから、ユーザが有用、あるいは興味がある情報を取得できるようにすることには高い需要があります。推薦とは、ユーザにとって重要な情報を積極的に提供することです。そこで、マルチメディアコンテンツに適用する推薦手段の確立が期待されています。
また、ニューラルネットワークに基づいた機械学習技術の進化によって、マルチメディア処理や推薦システムの研究分野も大きく発展しています。それぞれの分野の技術を結合したマルチメディアコンテンツにおける推薦システムも注目されています。本記事は、個人の理解によって、マルチメディアコンテンツの入力(表1の一列目)と、推薦システムとの結合方式(表1の二列目)の観点から、いくつか典型的な関連研究をまとめてみます(表1)。
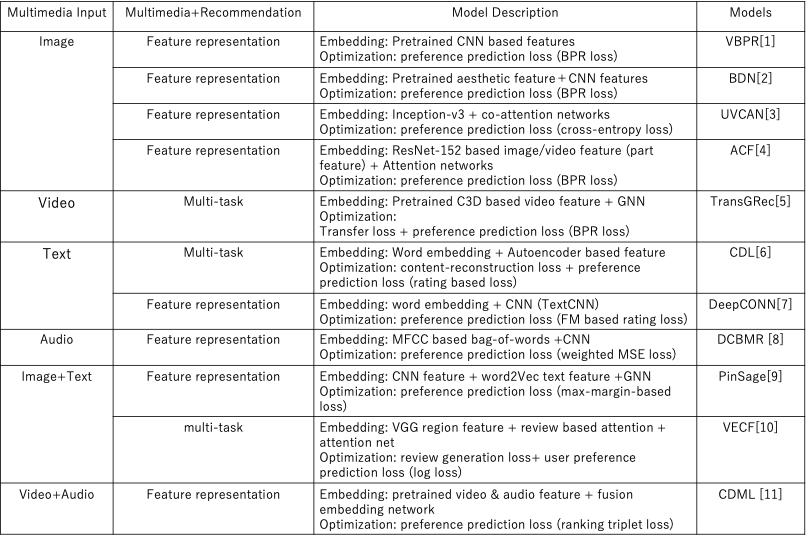
表1. 一部のマルチメディアコンテンツにおける推薦アルゴリズムのまとめ
マルチメディア入力
よく利用されるマルチメディア入力は、画像、映像、テキスト、音声と、それらの複数メディアの結合です。従来の一般推薦アルゴリズムは、ユーザとアイテムのID、メタ情報などを利用することが多いです。例えば、目的は映画を推薦することでも(Movielens datasetなど)、基本は映画のIDをアイテムの入力情報として利用します。映画のタイトルなど、テキスト情報を利用する研究もありますが、視覚的な情報の利用は少ないです。しかし、視覚的な情報を含むマルチメディア情報は、マルチメディアコンテンツに関わる様々なタスクで重要な役割を持ち、マルチメディア処理分野で様々な表現技術も研究されています。そこで、本記事は、マルチメディアコンテンツをただの推薦対象アイテムではなく、入力データとして利用するいくつかの研究事例を紹介します。
まず表1の順番通りにマルチメディアコンテンツの使用について紹介します。以下で使用するモデルの略称は表1の四列目に載せています。表1の三列目に、各モデルの特徴表現と最適化手法について簡単な説明を記載しています。
視覚情報(画像・映像)はマルチメディア推薦において特に注目されています。VBPR[1]は服などの商品推薦を目標とし、商品画像の視覚特徴が重要と考え、画像のDeep CNN特徴を推薦システムに応用した最初の論文です。使用したデータは服を中心としたAmazon.comとTradesy.comからの購買データです。BDN[2]も服を推薦することを対象にしています。ファッションコンテンツの特徴を十分に表現するため、物体認識タスクによって学習したCNNのセマンティック特徴以外に、商品画像の審美度情報も考慮して商品アイテムの視覚特徴を豊富に表現しています。使用したデータは同じくAmazon.comの服購買履歴とDPChallenge.comから収集した審美度を含むAVAデータセットです。UVCAN[3]はソーシャルメディアにおけるmicro-videoを推薦対象としますが、一秒ずつInception-v3 を用いてframe-levelの画像特徴を抽出し、これらの統合情報を映像視覚特徴として表現します。使用したデータはmicro-videoソーシャルメディアアプリToffeeから収集したものになります。 ACF[4]は、ウェブサービスにおける画像・映像コンテンツの推薦を対象とし、一般的なitem-levelの推薦だけではなく、アイテムの異なる部分(画像の領域、 映像のセグメント)や異なる時期のアイテムに対してユーザの好みが異なることを考慮したattentive推薦フレームワークを提案しました。画像特徴はResNet-152を用いて抽出し、画像パーツ特徴はResNet-152のres5c layer の特徴マップ(7*7*2048: 49 regions)で表現します。映像特徴は、同じくframe-levelの特徴を統合したものになります。使用したデータはPinterest(画像)とVine(映像)から収集した公開データセットになります。
映像特徴を入力とした推薦システムも研究されています。TransGRec[5]はユーザの好みを考慮した映像ハイライト抽出タスクを、映像セグメントの推薦問題に変換し、映像セグメントの時系列特徴を入力としてパーソナライズされた映像推薦システムを提案しました。使用したデータは、ユーザが手動で映像から好みの部分を選択してGIFsを構成する映像ハイライトウェブサイトGifs.comから取得した公開データセットです。
テキスト情報については、従来の推薦システムの多くの研究で使用されています。ここでは、2つの例を紹介します。CDL[6]は、タイトル、アブストラクト、タグなどのテキスト情報を、Bag of wordsを用いてword embeddingし、autoencoderに基づいてアイテム情報を表現しながら推薦を行う手法です。データはCiteULikeとNetflixから収集したものになります。DeepCONN[7]は、ユーザがアイテムに対して書いたレビューテキスト情報を利用し、Bag of wordsを用いたword embeddingをCNNを通したTextCNNというアルゴリズムで、ユーザとアイテムの両方を表現する特徴を生成します。使用したデータはレストランのレビューデータを含むYelpデータセットと、Amazonの商品 レビュー データセット、ビールのレビューを記載するサイトratebeer.comから収集したデータセットになります。
音声情報についての研究として、DCBMR[8]は、Million Song Datasetを使用して音楽を推薦することを目標とし、mel-frequency cepstral coefficients (MFCCs)などの音声特徴をbag of wordsで特徴表現してからCNNを通してユーザ嗜好を予測しています。
それぞれのメディア情報に関する研究だけではなく、複数メディアを統合利用する研究もあります。PinSage[9]は、Pinterestのような大規模ウェブサイトの推薦アルゴリズムを提案しています。PinSageは提案したGraph Convolutional Network (GCN)を用いて、ユーザとアイテムのインタラクション情報と、それぞれの特徴表現を結合します。GCNに入力したPinアイテムの情報には、VGG-16 で表現した画像特徴とWord2Vecに基づいたテキスト特徴(タイトル、説明文)のマルチモーダル特徴があります。VECF[10]は、Amazonのファッション商品推薦において、領域を考慮した画像情報と対応するレビュー情報を結合して、解釈性を持つ推薦システムを提案しました。CDML[11]は、映像推薦システムのアイテム特徴を、frame-levelな画像特徴を統合した映像特徴とVGGに基づいて抽出した音声特徴をfusion networkで結合して表現します。データはYouTube-8Mデータセットを使用しています。
マルチメディアコンテンツと推薦アルゴリズムの結合方式
本記事は、推薦システムにおけるマルチメディアコンテンツ利用方法について、大きく2つのカテゴリに分類します。
- Feature representation: 従来のIDやmetadataに基づくfree embeddingに加え、マルチメディアコンテンツをアイテムやユーザの表現に利用し、より豊富な特徴を表現可能とします。推薦のための目的関数の最適化については、従来と同じように、user preference prediction タスクのためのloss関数のみを使用して学習されます。
- Multi-task: マルチメディアコンテンツを、user preference predictionタスクのための特徴表現だけでなく、同時に他のタスクも並行的に達成するために利用して学習します。複数タスクを合わせて目標の推薦を行います。
前者の説明として、feature-based recommendationとcollaborative filtering (CF)-based recommendationを図1に例示します。また図2に、CF-based recommendationの一例として二つのカテゴリを比較してmulti-taskについて示します。両方とも、アイテムのみにマルチメディアコンテンツがあるという仮定をしていますが、ユーザにも同様にマルチメディアコンテンツを追加可能です。
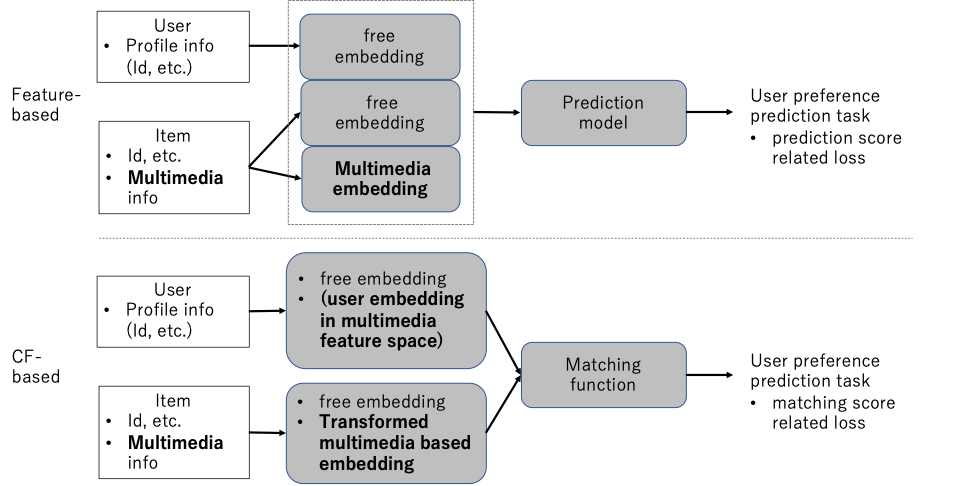
図1. Feature representation結合方式におけるfeature-basedとCF-basedの例の概念図
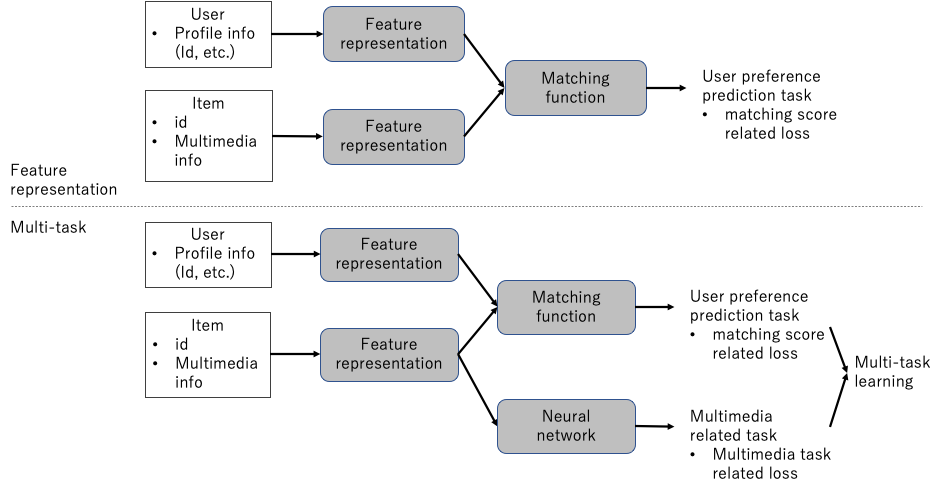
図2. Multi-taskおよびFeature representation結合方式の比較の例の概念図
表1の二列目に各研究の結合方式をまとめ、三列目に、対応するマルチメディアコンテンツの特徴表現と、目標タスクと関数を示しています。
以下、いくつかの具体例に基づいて説明します。
まず、Feature representation方式の、feature-based 推薦方法の例であるUVCAN[3](図3)について、図1上部のfeature-basedを参照しながら説明します。全体的なフレームワークはfeature embedding、 feature fusion、 predictionという3つのプロセスに分けられます。Embeddingでは、free embedding(ユーザとアイテムのIDなど)とmultimedia embedding (item) の両方を行い、(co-attentionを経由して)ユーザ特徴ベクトルとアイテム特徴ベクトルを生成します。生成した2つのベクトルを結合し(本論文ではconcat)、最終的なユーザ嗜好スコアを予測して、Ground Truthのスコアと比較することでモデルを最適化します (user preference prediction loss)。
![図3. UVCAN[3]: Feature representation方式、feature-based frameworkの例](https://cyberagent.ai/wp-content/uploads//2022/03/figure_3-1.png)
図3. UVCAN[3]: Feature representation方式、feature-based frameworkの例
次に、同じくFeature representation方式であり、CF-based推薦方法の例として、VBPR[1](図4)について図1下部のCF-basedを参照しながら説明します。CF-based方法は、ユーザとアイテムそれぞれを特徴表現にしてマッチング関数に入力し、user preference predictionを行います。ユーザとアイテムの特徴表現の次元数は同一かつ大きすぎない必要があるため、学習済み画像特徴をCF空間に変換して結合します(F+D)。user factorもCF空間のfree embeddingと変換した画像特徴に対応するembeddingの二つの部分で構成します。
![図4. VBPR[1]: Feature representation方式、CF-based frameworkの例](https://cyberagent.ai/wp-content/uploads//2022/03/figure_4-1.png)
図4. VBPR[1]: Feature representation方式、CF-based frameworkの例
Multi-task方式としては、TransGRec[5]、 CDL[6]、 VECF[10]などの例があります。
その中の、TransGRec[5](図5)は、マルチメディアコンテンツ(video feature)をuser preference prediction taskに適用するだけではなく、最終的なアイテム表現(after GNN modelling)と比較するtransfer lossによってtransfer networkを学習し、C3D映像特徴から最終的なアイテム表現に変換・生成するタスクも並行で行います。これにより、item cold start問題にある程度対応可能となります。
![図5. TransGRec[5]: Multi-task方式の例](https://cyberagent.ai/wp-content/uploads//2022/03/figure_5-1.png)
図5. TransGRec[5]: Multi-task方式の例
また、VECF[10](図6)では、商品画像特徴(region-based)をpreference prediction taskに適用するだけではなく、商品のレビュー情報と商品画像に部分的に対応性があることを利用し、レビューを生成するタスクを同時に行うことで、解釈性を持つ推薦システムを提案しました。
![図6. VECF[10]: Multi-task方式の例](https://cyberagent.ai/wp-content/uploads//2022/03/figure_6-1.png)
図6. VECF[10]: Multi-task方式の例
おわりに
本記事は、引用した論文(サーベイ論文[12]を含め)を勉強したものと著者の個人的な感想によってまとめたものになります。紹介したマルチメディアコンテンツの特徴表現方法と結合方式には、すべての最新のマルチメディア処理技術と推薦技術を含んではいないことがありますが、類似する問題設定とデータ構造に対して、最新の技術を上述のフレームワークに適用できる可能性があると思います。また、ソーシャルメディアのような大規模かつ疎なマルチメディアデータ構造に対し、モデルの効率性や、適切かつ汎用的な評価尺度、cold start problemなどの様々な挑戦が残っており、クロスモーダル学習、自己教師あり学習などの技術との融合も期待できると思います。
データセット/コード
- VBPR:
- Amazon dataset: Image-based recommendations on styles and substitutes (https://lijiancheng0614.github.io/2016/12/09/2016_12_09_image_based_recommendations/)
- BDN:
- ACF:
- Pinterest(Image): Learning image and user features for recommendation in social networks.(https://sites.google.com/site/xueatalphabeta/academic-projects);
- Vine(micro-video): Shorter-is-be.er: Venue category estimation from micro-video.( https://data.world/socialmediadata/creativity-in-vine-microvideos)
- TransGRec : video highlight(Gifs.com):
- DeepCONN:(レビュー dataset)
- DCBMR: (music)
- Million Song Dataset : http://millionsongdataset.com/
- VECF: (fashion: image, text)
- CDML:
- YouTube-8M: https://research.google.com/youtube8m/
Reference:
[1] R. He and J. McAuley, “VBPR: visual bayesian personalized ranking from implicit feedback,” in AAAI, 2016, pp. 144–150.
[2] W. Yu, H. Zhang, X. He, X. Chen, L. Xiong, and Z. Qin, “Aesthetic-based clothing recommendation,” in WWW, 2018, pp.649–658.
[3] S. Liu, Z. Chen, H. Liu, and X. Hu, “User-video co-attention network for personalized micro-video recommendation,” in WWW, 2019, pp. 3020–3026.
[4] J. Chen, H. Zhang, X. He, L. Nie, W. Liu, and T.-S. Chua, “Attentive collaborative filtering: Multimedia recommendation with item- and component-level attention,” in SIGIR, 2017, pp.335–344.
[5] L. Wu, Y. Yang, L. Chen, D. Lian, R. Hong, and M. Wang, “Learning to transfer graph embeddings for inductive graph based recommendation,” in SIGIR, 2020, pp. 1211–1220.
[6] H. Wang, N. Wang, and D.-Y. Yeung, “Collaborative deep learning for recommender systems,” in SIGKDD, 2015, pp. 1235–1244.
[7] L. Zheng, V. Noroozi, and P. S. Yu, “Joint deep modeling of users and items using レビューs for recommendation,” in WSDM, 2017, pp. 425–434.
[8] A. v. d. Oord, S. Dieleman, and B. Schrauwen, “Deep content based music recommendation,” in NeurIPS, 2013, pp. 2643–2651.
[9] R. Ying, R. He, K. Chen, P. Eksombatchai, W. L. Hamilton, and J. Leskovec, “Graph convolutional neural networks for web-scale recommender systems,” in SIGKDD, 2018, pp. 974–983.
[10] X. Chen, H. Chen, H. Xu, Y. Zhang, Y. Cao, Z. Qin, and H. Zha, “Personalized fashion recommendation with visual explanations based on multimodal attention network: Towards visually explainable recommendation,” in SIGIR, 2019, pp. 765–774.
[11] J. Lee, S. Abu-El-Haija, B. Varadarajan, and A. Natsev, “Collaborative deep metric learning for video understanding,” in SIGKDD, 2018, pp. 481–490.
[12] L. Wu, X. He, X. Wang, K. Zhang and M. Wang, “A Survey on Accuracy-oriented Neural Recommendation: From Collaborative Filtering to Information-rich Recommendation Framework General recommendation”, IEEE Transactions on Knowledge and Data Engineering, 2022.
Author