Blog
身振り動作の特徴を転移する学習手法
AI Lab Graphics チームの栗山※です.この記事では,コンピュータ・アニメーションにおける深層学習の活用例として,仮想空間において化身となるアバターの運動や身振りを生成する際に,個性的な動きの特徴を学習して標準的な動きに転移させる手法の変遷と,先月に国際会議で発表した論文の内容を紹介します.
※ クロス・アポイント制度による兼業(豊橋技術科学大学,情報・知能工学系所属)
イメージからモーションへ
動作の数値表現は,人体の各関節の位置や回転角で表される姿勢状態ベクトルの時系列で構成される2次元データとなるので,画像に対する深層学習の手法が適用しやすいデータ構造です.ただし,画像の場合は3次元の色空間をチャネルとする画素値に対する2次元の畳み込み層で特徴を抽出しますが,動作の場合は,3次元位置や回転角†をチャネルとする,時間軸に沿った1次元の畳み込み層で特徴抽出する点が異なります.動作データでは行動の予測手法と同様に,自己回帰モデルを用いて事前の姿勢系列の値を参照して次の動作を予測する機構が多く用いられてきましたが,コンピュータ・アニメーションの分野においては,予測に適した再帰型のモデル(RNN等)は,あまり用いられません.
† 深層学習で用いられる回転角は3次元から8次元までの様々な表現が存在し,その代表例としては指数マップ(3D),四元数(4D),および3D回転座標系の2軸表現(6D)が挙げられます.我々の手法では,関節の位置は用いずに指数マップの回転角のみで構成されるコンパクトな表現を用いました.
画像スタイル転移手法の適用
身体動作の特徴を転移する最初の手法[1]は,画像の分野で開発されたスタイル転移(Style Transfer)の初期の代表的な手法[2]と同様の損失関数を用いて開発されました.この手法によって様々な歩行・走行スタイルの転移の可能性が示されましたが,新たなスタイル毎に再学習が必要であり,身振り動作などの周期性の無い動きに関しては表現力に限界がありました.その後,敵対的な学習を導入した動画からのスタイル転移手法[3]や,人体の階層構造に基づくグラフ・ニューラルネットワークを用いた人体部位毎のスタイル転移手法[4]などが提案されましたが,様々な個性を有する身振りの特徴を学習するには,適切にラベル付けされた大量のデータが必要になると予想されます.しかし,モーション・キャプチャのデータを高精度に計測する作業や,分類の難しい動作の特徴部分を切り出してラベルを付与する作業には,熟練と多くの労力が必要とされます.ゆえに,身振り動作のスタイル転移においては,ラベルのない未知の特徴データを再学習を経ずに活用できること,すなわち深層学習の用語で「教師無しゼロショット学習」と呼ばれる学習機構が,実用性の面からは重要となります.
小領域の入れ替え戦略とビジョン・トランスフォーマの統合
画像処理の分野では,この教師無しゼロショット学習によるスタイル転移として,画像をパッチと呼ばれる小矩形領域に分割し,風景撮影した画像のパッチと絵画などのスタイル画像のパッチをその内容(構造的な特徴)が類似する様に入れ替える(スワップする)手法[5]が提案されています.筆者の研究グループでは,この手法を身振り動作のスタイル転移に応用する手法[6](論文へのリンクはこちらです)を提案しました.
図1に示す様に,歩行の場合はスタイルを様々に変化させた動きの潜在変数の時間変化には強い相関関係が認められます.一方で図2に示す様に,我々が使用した個性的な身振り動作の潜在変数の波形に関しては,内容(赤線)とスタイル(青線)の間には一定の関係性が視認できません.この様な状態では,画像のスタイル転移で用いられている白色化やコサイン距離による類似度の計算では,有効な対応関係が得られませんでした.
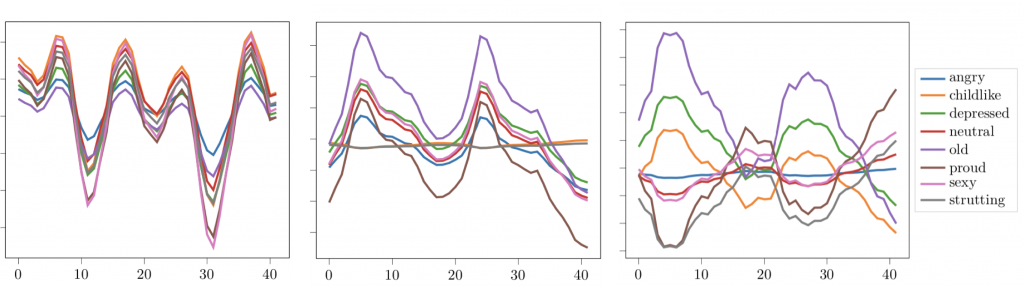
図1.様々なスタイルの歩行動作の潜在変数の時間推移(文献[3]の Figure.2 の転載).各々の波形は,その平均値と分散値の調整により互いに変換可能であり,適応的インスタンス正規化(AdaIN; Adaptive Instance Normalization)を用いた変調に適しています.
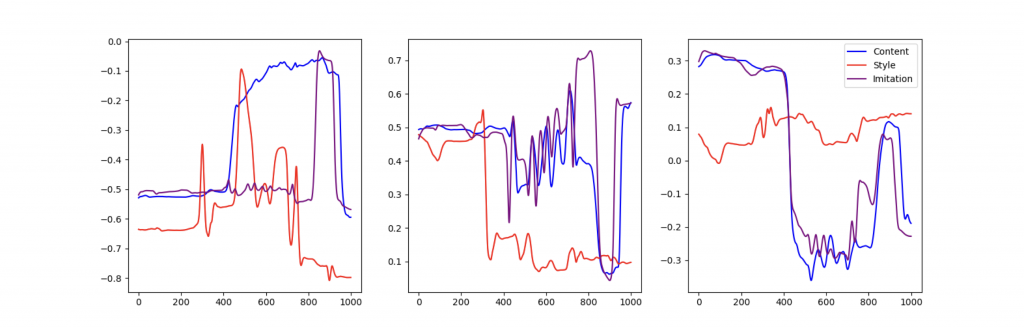
図2.身振り動作の潜在変数の時間推移.通常の身振り動作を青線で,その内容の正確な伝達を意識しながら誇張した身振りを紫線で,および意識しないで同様に誇張した身振りを赤線で示しています.ここでは,紫線の身振りは,青線の身振りに対する赤線のスタイルの転移結果の模倣に相当します.転移結果を模倣した波形(紫線)においても,元の身振り(青線)との関連性が欠如している箇所が散見されます.
そこで我々の研究では身振り動作の発話内容との相関性に着目し,自然言語処理で開発されたトランスフォーマを画像のスタイル転移に適用した手法[7]を,動作のスタイル転移に応用しました(弊社のプレスリリースにおいて動画付きで紹介していますので,転移結果の具体例はそちらをご覧ください).これにより,画像パッチに相当する,動作データを時分割して得られる身振りのトークンの対応関係が,複雑な波形の類似度ではなく動作の文脈としての類似度に基づいて計算されるので,柔軟かつ頑健なスタイルの転移が可能となりました.この研究の貢献は,動作内容とスタイルのトークンをスワップする際の重みの学習に,ビジョン・トランスフォーマ(ViT)を介した外観と構造の損失関数[7]を導入した点にあります.
適用分野と今後の展望
身振り動作(ジェスチャ)を生成する技術は,様々なサービス展開が期待されているメタバースにおける化身を介したコミュニケーションの高度化に重要な役割を担うでしょう.実際に近年では,発話の音声信号やテキスト情報から顔の表情や身振り動作を自動生成する深層学習の技術が盛んに提案されています.我々が開発したスタイル転移をこれらの自動生成と統合することにより,単に意味を伝えるだけではなく,感性的な情報も巧みに伝達できる豊かなコミュニケーション環境の実現が期待されます.
転移される身振りに内容としてのバリエーションを十分に確保するには,スタイル特徴を有するデータの充実化が必須となりますが,実時間での対話的な身振りの生成を考慮すると,データの増加に対する計算負荷のスケーラビリティーを確保する必要があります.そのために,注意機構の計算を効率化するためのトークンの表現・構成の最適化などが今後の課題です.
[1] D. Holden, I. Habibie, I. Kusajima and T. Komura, “Fast Neural Style Transfer for Motion Data,” in IEEE Computer Graphics and Applications, vol. 37, no. 4, pp. 42-49, 2017, DOI: 10.1109/MCG.2017.3271464.
[2] L. A. Gatys, A. S. Ecker and M. Bethge, “Image Style Transfer Using Convolutional Neural Networks,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2414-2423, DOI: 10.1109/CVPR.2016.265.
[3] K. Aberman, Y. Weng, D. Lischinski, D. Cohen-Or, and B. Chen, “Unpaired motion style transfer from video to animation,” ACM Trans. Graph. 39, 4, Article 64, 2020, DOI:10.1145/3386569.3392469.
[4] D.-K. Jang, S. Park, and S.-H. Lee, “Motion Puzzle: Arbitrary Motion Style Transfer by Body Part,” ACM Trans. Graph. 41, 3, Article 33, 2022, DOI:10.1145/3516429.
[5] L. Sheng, Z. Lin, J. Shao, and X. Wang, “Avatar-Net: Multi-scale Zero-shot Style Transfer by Feature Decoration,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[6] S. Kuriyama, T. Mukai, T. Taketomi, and T. Mukasa, “Context-based Style Transfer of Tokenized Gestures,” Computer Graphics Forum (Symposium on Computer Animation), 2022, DOI:10.1111/cgf.14645.
[7] N. Tumanyan, O. Bar-Tal, S. Bagon, and G. Dekel, “Splicing vit features for semantic appearance transfer,” In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
Author