Blog
【採択論文紹介】Noise2Noise学習を用いた実環境により適応性の高い音声強調モデルの学習法(ICASSP2024)
AI Lab Audioチームの李です。我々のチームでは広告クリエイティブの制作支援やデジタルマーケティングに応用可能な研究開発に取り込んでおり、その中でも我々は実環境により適応性の高い音声強調手法の技術開発に取り込んでいます。この記事ではICASSP2024に採択された、Noise2Noise学習を用いた音声強調モデルの学習法に関する論文について紹介します。
Remixed2Remixed: Domain adaptation for speech enhancement by Noise2Noise learning with Remixing
Li Li and Shogo Seki
Keywords: 音声強調モデル / Noise2Noise学習 / ICASSP2024
はじめに
音声強調は雑音や干渉音が混ざった音声の品質を向上させる基本技術であり、騒音環境でのコミュニケーションのサポートや音声認識システムの頑健性向上といった応用が期待されています。従来から、雑音が混じったノイジー音声と対応するクリーン音声のペアを学習データとして利用する教師あり学習に基づく手法が数多く提案されています。現在では、学習時とは異なる騒音環境でも頑健に動作するよう実環境での応用を想定した手法についても検討が進んでいます。本研究では、合成されたペア音声と実環境のノイジー音声を学習データとして併用する既存手法を改良して、より高性能な音声強調モデルを実現しました。
提案手法:Remixed2Remixed (Re2Re)
提案手法では、RemixIT[1]とよばれる既存手法を基に、異なる学習基準を導入しました。いずれの手法でも、同一のネットワークアーキテクチャをもつ音声強調モデルを二つ準備して一方を教師モデル、他方を生徒モデルとして順番に学習する自己蒸留とよばれる枠組みが利用されています。この枠組みでは、従来の教師あり学習に基づく手法と同様に合成されたペア音声を用いて、教師モデルをはじめに学習し(図1左)、そのあとパラメータや実環境のノイジー音声に対する推定信号を使って、生徒モデルを学習します。
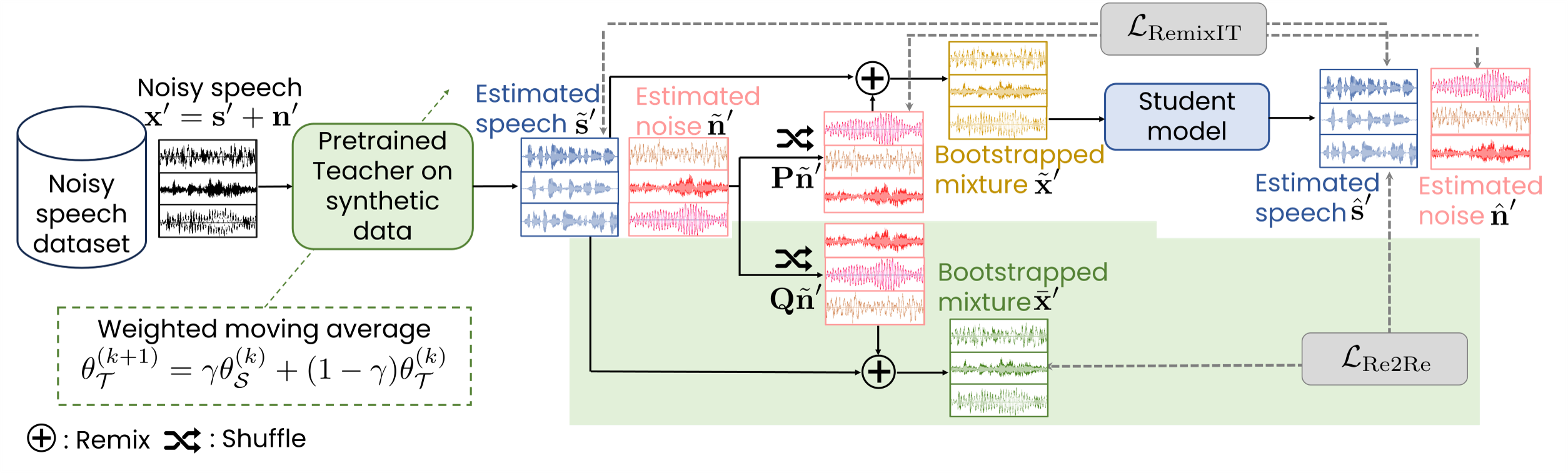
従来法RemixITと提案法Re2Reの流れ.緑色はRe2ReとRemixITの差分を示す.
RemixITは、推定された音声に対する雑音の組み合わせを入れ替え・再混合して得られるペア音声を用いて教師あり学習により生徒モデルを学習します(図1右上)。このとき、生徒モデルは教師モデルが推定した音声を目標に学習されることになりますが、RemixITでは実際には得られない正解のクリーン音声を推定するよう学習できることが数理的に示されています。ただし、これは一定の条件の下に限定され、条件を満たすには膨大な計算リソースが必要となることから、多くの場合実現が困難です。結果としてRemixITでは、教師モデルが十分に良い性能を持っていない場合、生徒モデルの性能も教師モデルから大きく影響を受けてしまいます。
我々が提案したRe2Reでは、RemixITで行われていた入れ替え・再混合プロセスを別途実施して二パターンのノイジー音声を用意し、画像分野で提案されたNoise2Noise学習[2]とよばれるアプローチにより生徒モデルを学習します(図1右下)。生徒モデルは、あらたに追加されたノイジー音声を目標に学習されますが、Noise2Noise学習は特定の条件の下で教師あり学習と等価になるため、RemixITと同様に生徒モデルは真のクリーン音声を推定するよう学習されます。このとき、Noise2Noise学習で満たされるべき条件はRemixITと比べて容易に実現できるため、より適切な条件で学習が可能となります。Noise2Noise学習の数学的証明については、[3, 4]で詳しく解説されています。
実験結果

2種類の実録音学習データセットにおける既存手法(RemixIT)と提案手法(Re2Re)の性能比較(SI-SDR [dB])。それぞれの数値は教師モデル計10モデルの平均と標準偏差を表し、太字と下線はそれぞれ平均が最高性能であることと標準偏差が既存手法以下であるを示す。
技術評価国際イベント(CHiME-7 Task2)[5] のデータセットを用いた対照実験を行ったところ、表1に示すように提案手法が既存手法に比べて高い強調性能を達成することを確認しました。また、既存手法で課題となっていた教師モデルに対する依存性についても、提案手法では緩和されることがわかりました。さらに、CHiME-7 Task2に参加したトップ5のシステムと比較すると、提案手法は2位のシステムと同等の性能を達成しました。
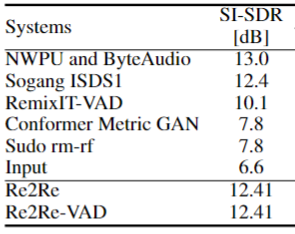
CHiME-7 Task2の上位5システムとの性能比較。
おわりに
本研究では、Noise2Noise学習を用いて、実環境に適応性の高い音声強調モデルの学習法を開発しました.今後はこの提案手法を基盤として、実環境に対応した頑健な音声強調システムの開発や、既存の音声データのクリーニングの精度向上に取り組んでいく予定です。弊社では毎年、博士課程の学生を対象としたリサーチインターンシップの募集を行っています。今年も間もなく募集を開始します。このような研究にご興味をお持ちの方は、ぜひ私たちにお声がけください。
参考文献
[1] E. Tzinis, Y. Adi, V. K. Ithapu, B. Xu, P. Smaragdis, and A. Kumar, A, “Remixit: Continual self-training of speech enhancement models via bootstrapped remixing,” IEEE JSTSP, vol. 16, no. 6, pp. 1329-1341, 2022.
[2] J. Lehtinen, J. Munkberg, J. Hasselgren, S. Laine, T. Karras, M. Aittala, and T. Aila, “Noise2Noise: Learning Image Restoration without Clean Data,” in Proc. ICML, pp. 2965-2974, 2018.
[3] https://qiita.com/zerowarurei/items/b86bdc1175dfd0aa0811
[4] https://qiita.com/U-Not/items/939b80bb20bbf74acbe3
[5] S. Leglaive, L. Borne, E. Tzinis, M. Sadeghi, M. Fraticelli, S. Wisdom, M. Pariente, D. Pressnitzer, and J. R. Hershey, “The CHiME-7 UDASE task: Unsupervised domain adaptation for conversational speech enhancement,” in Proc. CHiME-7, 2023.
Author