Blog
KDD2018参加報告
こんにちは,AI Labの谷口です.
今回は2018年8月19日から23日までロンドンで行われたKDD2018に参加してきたので,その参加報告をしたいと思います.
目次
- KDD
- KDD2018
- Overview
- Research Track
- Applied Data Science Track
- AdKDD & TargetAd
- 気になった発表紹介
- まとめ
KDD
KDDはKnowledge Discovery and Data Miningの略で,名前の通り,データマイニングに関するトップカンファレンスの一つです.
KDD2018

2018年度はロンドンで開催.参加者は98カ国から3400名となり,過去最大のKDDになりました.
去年と比べて日本から参加されている人が圧倒的に増えた印象でした.(体感5倍程増えている気がします)
Overview
ここでは各Trackの投稿に関する情報やBest Paperについて紹介します.
Research Track
投稿数は983件でOralの通過は107件(107/983=10.9%),Posterについては74件(74/983=7.5%)という査読率でした.
Best Paperは「Daniel Zügner,Amir Akbarnejad,Stephan Günnemann,”Adversarial Attacks on Neural Networks for Graph Data”」,Best Student Paperは「Hongyuan Zhu,Qi Liu,Nicholas Jing Yuan,Chuan Qin,Jiawei Li,Kun Zhang,Guang Zhou,Furu Wei,Yuanchun Xu,Enhong Chen”XiaoIce Band: A Melody and Arrangement Generation Framework for Pop Music”」でした.
投稿された論文の分野別の内訳は次の図のようになっています.
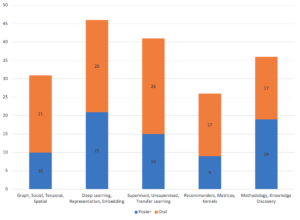
Applied Data Science Track
投稿数は496件でOralの通過は40件(40/496=8%),Posterについては72件(72/496=14.5%)という査読率でした.
Best Paperは「Mihajlo Grbovic,Haibin Cheng,”Real-Time Personaization using Embeddings for Search Ranking at Airbnb”」,Best Student Paperは「Jacob Abernethy,Alex Chojnacki,Arya Farahi,Eric Schwartz,Jared Webb,”ActiveRemediation: The Search for Lead Pipes in Flint, Michigan”」でした.
投稿された論文の分野別の内訳は次の図のようになっています.
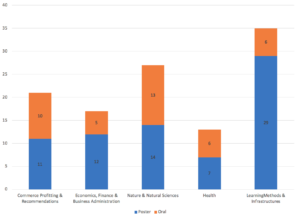
TEST OF TIME AWARD
他にも様々なAwardがあるのですが,ここではTest of time awardについて紹介しておきます.これはSIG系で行われているAwardの一つで,過去の論文に対して表彰するという少しユニークなものです.詳しくはこちらをご覧ください.
今回のTest of time awardは「Yehuda Koren,”Factorization meets the neighborhood: a multifaceted collaborative filtering model”」でした.
AdKDD & TargetAd

KDDで開催されるワークショップでは「AdKDD & TargetAd」という名前の広告をメインにしたワークショップが開催されています.広告に関する内容が発表されている他の学会としては他にもWSDMやWWWが挙げられますが,AdKDDではデータマイニングや機械学習に関する内容だけでなく,特にEconomics関連の色が強く出ているのが特徴です.その裏付けとして,前回はkeynoteの半分が計量経済学お呼び因果推論に関連する内容で占められており、今回はメカニズムデザイン関連の研究者による公演が行われました.
Best Paperは「Yoel Zeldes,Stavros Theodorakis,Efrat Solodnik,Aviv Rotman,Gil Chamiel ,Dan Friedman,”Deep density networks and uncertainty in recommender systems”」,Best Student Paperは「Alfonso Lobos,Paul Grigas,Zheng Wen,Kuang-Chih Lee,”Optimal Bidding, Allocation and Budget Spending for a Demand Side Platform Under Many Auction Types”」でした.
気になった発表紹介
A Large Scale Benchmark for Uplift Modeling
AdKDD内でCriteoから発表されたUplift Modelingに関する論文です.
ターゲティング広告の表示をTreatmentとした,広告主サイトの来訪とコンバージョンのラベル付きのデータセットを公開しました.彼らはこれまでにもKaggleやそれ以外の場所で多くのデータセットを公開しているので,アドテク業界の研究に大きな貢献をしていると言えます.
Real-time Personalization using Embeddings for Search Ranking at Airbnb
ADSのBest Paperを受賞した論文でAirbnbからの発表です.ClickされたListingに関するListing typeとClickしたUserのUser typeのSequenceデータを基にSkip-gramでEmbeddingを学習します.ListingとUserのtypeはヒューリスティックなルールによって決めています.実際に学習されたEmbeddingをSearch Rankingに用いることで精度向上が確認されました.発表とは関係ないのですが,今回のKDDでのAirbnbの発表は,Best Paperに関わらずかなりの数の人が聴講しに来ていたのでその注目度が伺えました.
I Know You’ll Be Back: Interpretable New User Clustering and Churn Prediction on a Mobile Social App
タイトルから非常に何をやっているかがわかりやすい論文ですが,名前の通り,Churnの予測モデルを提案している論文です.アプリ内のactivityのデータからクラスタリングを行い、ユーザを分類することでchurn rateを推定する方法とseq2seqやLSTMなどをベースにしたchurn予測モデルの二つの手法が紹介されています.
Online Parameter Selection for Web-based Ranking Problems
LinkedInのFeedのRankingに関する研究です.あるUtilityを最大化するパラメータをオンラインに学習するために,Gaussian Processを利用したThompson Samplingを行う手法を提案しています.実験ではオフラインのシミュレーションに加えて,実際にA/Bテストを実施した結果が紹介されています.
OpenTag: Open Attribute Value Extraction from Product Profiles

図のような商品詳細から商品を表すタグを取得するという研究です.問題としてはsequence tagging taskとして取り扱い,RNN(Recurrent Neural Network)とCRF(Conditional Random Field)を使った方法を提案しています.また,モデルのinterpretability(解釈性)やActive Learningにも挑戦しています.この研究もそうですが,KDDではラベル付けのコストが高いという課題感から生まれている研究が多いように感じました.
(図は論文中から取得したものです)
Customized Regression Model for Airbnb Dynamic Pricing
私は使ったことがないのですが,Airbnbのサービス内でホストが価格を設定する際に,Tipsの表示やSmart Pricingという機能使うことで価格を最適化することが可能になるらしいです.本論文ではその機能で利用されているモデル3つの内の最適価格の回帰モデルについて紹介されています.モデルについては単純なGBDTを利用しています.またオフラインでの評価指標も提案されており,実験ではオフラインの検証に加えて,実際のサービスで1年以上稼働させた結果が紹介されている.
Software 2.0 and Snorkel

これはADSの招待講演の一つですが,Snorkelというソフトウェアが面白かったので簡単に紹介します.簡単に言えば学習データに対してラベルをプログラマティックに付けるためのシステムです.思想としては完全に正解のラベルをつけるよりもドメイン知識などを利用したラベリング関数を定義して,weaklyなラベルをつけることが目的なのかなと思います.ヒューリスティックにラベルを付ける以上,機械学習を行う場合とどちらの方が精度が高くなるのかという議論などもあると思いますが個人的には注目です.
まとめ
KDD2018の参加報告を簡単ですがまとめてみました.
過去最大級となったロンドンでのKDDですが,企業の人間としてはApplied Data Scienceの発表はどれも非常に参考になりました.特に感じたのがどの発表を聞いていても「A/Bテスト」「Online Test」という単語がしきりに出ていたことです.当たり前のように聞こえますが,研究開発部門が作ったものをプロダクトで実際に利用するというのは実際には乗り越える壁が多いので,我々も見習わなければいけないと思います.
我々のような事業会社で研究をしているリサーチャーはアルゴリズムの研究開発ももちろんですが,実際に自分達のサービスに活用してどれくらいの効果があったかを発表することにも非常に価値があると思うので,来年以降はぜひ発表できるように頑張っていきたいと思います!
Author