Blog
【採択論文紹介】データの欠損にロバストなマルチモーダル感情認識 (WACV2026)
AI Lab Interactive Agentグループの三好です。Interactive AgentグループはHuman-Agent Interaction、Human-Computer Interactionを中心に研究・開発を行っています。今回は、Computer Vision分野の主要な国際会議であるWACV2026(IEEE/CVF Winter Conference on Applications of Computer Vision)に採択された論文について紹介します。
Authors:Ryo Miyoshi, Mayu Otani, Yuki Okafuji
はじめに
HRI(Human-Robot Interaction)では、ロボットが人と同じ空間で関わるため、相手の感情やストレス状態を把握し、声かけや動作の強度・タイミングを調整することが重要です。ユーザの感情を適切に捉えられないと、不適切な応答や過度な介入につながり、ユーザ体験や信頼に影響し得ます。こうした背景から、複数の手がかりを統合して人の状態を推定できる感情認識、とりわけマルチモーダルなアプローチが注目されています。一方で、ロボットを実際にフィールドに持っていくと、必ずしも理想的な条件でセンシングできるとは限りません。人の動きや遮蔽で映像が欠けたり、環境雑音で音声が取りづらかったり、通信やデバイス都合で一部の信号が落ちたりと、結果としてデータ欠損が生じやすくなります。そのため、欠損を前提にしても安定して動く感情認識が求められます。マルチモーダル感情認識(MER)は、テキスト・音声・映像といった複数モダリティを組み合わせて人の感情状態を推定するタスクです。単一モダリティよりも多面的な手がかりを活用できる一方で、現実には次のような理由で入力が欠損することが少なくありません。
-
センサー故障や通信エラーで 音声が途切れる/映像が欠ける
-
プライバシー要件で 特定モダリティが利用できない
-
収録環境の制約で 品質が悪い(実質的な欠損)
しかし、多くの既存研究は学習時も推論時も全てのモダリティが揃うことを仮定しており、欠損が起きると性能が大きく落ちやすい、という課題があります。そのような課題に対して、ロバスト性を向上させる手法も提案されていますが、学習時には欠損のないデータを必要としています。一方で、実世界で収集されるデータに欠損を含めないことは困難であるため、そのようなデータでもロバストに動作する必要があります。
既存手法の課題
欠損に頑健にするために、従来は主に次の方向性が採られてきました。
-
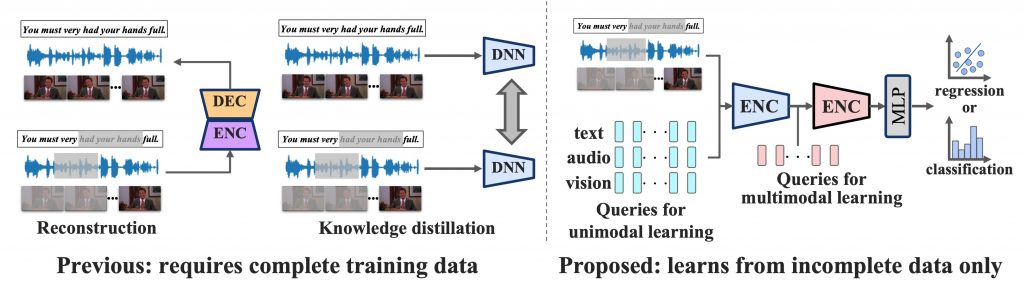
Reconstruction:観測できたモダリティから欠損モダリティを生成・補完し、完全入力に近づける方法。ただし、感情推定に不要な情報まで生成してしまったり、復元タスクがボトルネックになる可能性があります。
-
Knowledge Distillation:完全モダリティで学習した Teacher を用意し、不完全入力の Student を Teacher に近づける方法。ただし、Teacher 学習のために完全データが必要になりやすく、現場では用意できないケースがあります。
本研究では、「完全モダリティに依存せず、不完全入力だけで頑健な表現学習ができる」ことを狙った手法を提案します。
提案手法
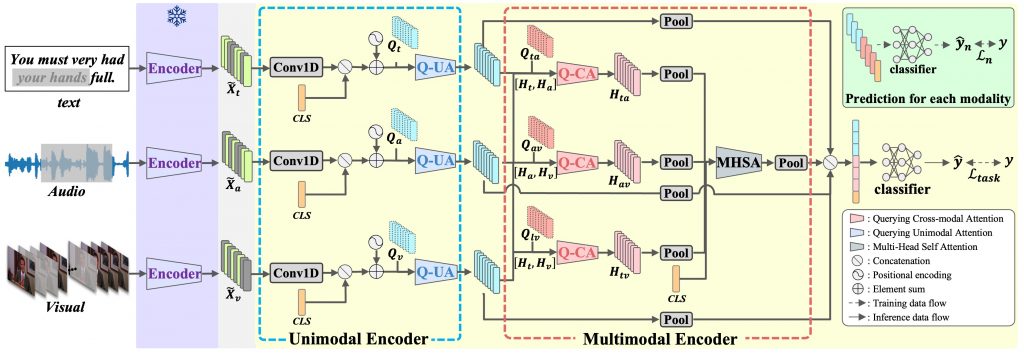
本研究では、欠損(不完全)なモダリティ入力だけで学習できる頑健なMERフレームワーク Dual-Query Fusion(DQF)を提案します。DQFは復元(reconstruction)や蒸留(distillation)に頼らず、学習可能なクエリを用いて「特徴抽出」と「モダリティ融合」を安定化します。
(1) 事前学習エンコーダで特徴抽出:テキスト/音声/映像の埋め込みを取得(エンコーダは固定)。
(2) Q-UA(単一モダリティの頑健化):各モダリティに対してクエリを自己注意で更新し、入力特徴に注入してTransformerで表現を抽出。欠損やノイズがあっても重要な手がかりを拾いやすくします。
(3) Q-CA(モダリティ融合の安定化):モダリティ対(ta/tv/av)ごとに共有クエリを介した注意で融合し、強いモダリティへの過度な依存を抑えながら補完情報を統合します。
(4) 多粒度の学習:単一・2モダリティ・3モダリティの各粒度で予測損失を入れ、欠損パターンが変わっても性能が崩れにくいように学習します。
実験
実験条件
本実験では、CMU-MOSEIというセンチメントに関するデータセット、MELDという7感情の分類タスクに関するデータセットの2つの公開データセットを用いて評価しました。これらのデータセットには欠損が含まれていないため、各モダリティの系列に対してランダムにマスクし、欠損フレームをゼロベクトルに置換します。欠損率は 0〜1 の範囲で変化させ、幅広い欠損状況を評価します。また、実験では欠損のない入力に対する評価、欠損のある入力に対する評価を実施しました。
実験結果
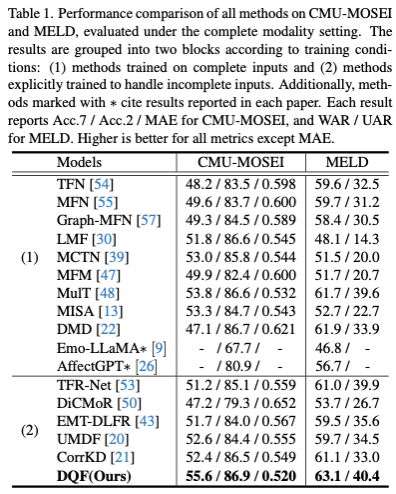
欠損のない入力および欠損のある入力のいずれの評価において、提案手法は比較手法を上回る性能を達成しました。特に欠損なし条件では、DQFは欠損入力のみで学習しているにもかかわらず、完全モダリティを前提に学習する代表的手法(MulT / MISA / DMD など)を含む complete-modality系ベースラインを上回る結果となりました(表1)。
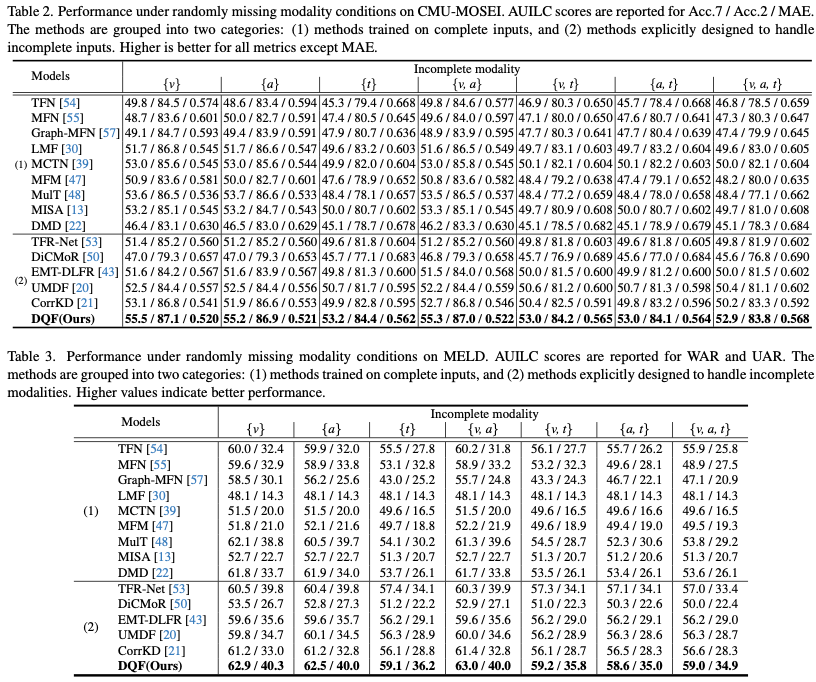
また欠損あり条件でも、復元系・蒸留系といった従来のロバスト手法を一貫して上回り、特に3モダリティ全てに欠損が入る最難条件でも改善が確認されています(表2・表3)。
おわりに
論文中でも述べている通り、現時点の評価は主にシミュレーション欠損と2つのベンチマークに基づいています。今後は、実運用に近い欠損データでの検証や感情認識以外のより広いアフェクティブ(affective)タスクへの展開などを進めていきたいと考えています。
また、我々のチームでは一緒に Human-Robot Interaction / Human-Computer Interaction の研究・開発を行っていただける研究者・エンジニア・博士インターン生を募集しています。本ブログを見てご興味を持っていただけた方はぜひ一度カジュアルにお話させてください。よろしくお願いします。
Author