Blog
エッジAI用デバイスの種類と仕様、処理速度を比較してみた

AI Labの尾崎です。
主に人間とロボットとのインタラクションに関する技術開発を担当しております。
さて、ロボットといえば、コミュニケーションロボットや自動運転車など、自律的に動いてもらって人の労働を助けるものが多いと思います。人の労働を助けるほど、ロボットに人並みに自律的で賢く動いてもらうためには、たとえば、ロボットに視覚を与える必要が出てきます。このときに役立つのがロボットビジョンを始めとした人工知能 (AI) です。特にロボットのAIのようなインターネットの末端 (エッジ) にいるAIをエッジAIと呼びます[1,22]。
最近では深層学習と呼ばれる技術が生まれ、このエッジAIの分野も革新的に進歩しました。深層学習のおかげでロボットは、目の前の歩行者を画像から認識したり、部屋のものを認識できるようになったりしました。しかし、この深層学習で作られたモデルを使うには莫大な量の計算をしなければならない問題があります。また、その計算をすると、計算に使う電力が大きくなる問題があります。ロボットという物理的に限られたスペースでは、この2つの問題を解決するのはとても難しいのです。そのため、この2つの問題を解決するために、ロボットなどを対象としたエッジAI専用のデバイスが開発されるようになってきました。
本記事では、エッジAIに役立つデバイスについて、その種類とそれぞれの仕様、実際の画像検出結果を分析してお伝えします。
市販のエッジAI用デバイスの種類を比較
エッジAI用デバイスはたくさんあります。その中でも特にみなさんが使いやすい市販されているものを今回紹介したいと思います。まず、エッジAI用デバイスを体系的に理解するために、デバイスの種類と特徴を写真付きで簡単に説明します。
シングルボードコンピュータ(SBC)の特徴
SBCはコストや処理速度、消費電力に優れているという特徴があります。汎用IO(GPIO)が備わっていることが多く、電子工作などで機能を拡張することができます。ここでは例としてJetson Nano Developer Kitの写真を図1に示します。ただし、拡張性が高く、専用のデバイスであるため、開発や取り扱いに専門知識が必要という弱点があります。
 図1 Jetson Nano Developer Kitの写真
図1 Jetson Nano Developer Kitの写真
ミニPCの特徴
ミニPCは開発や取り扱いがとても簡単である特徴があります。実は多くのミニPCはディスプレイとキーボード、バッテリがないノートパソコンと同じような構成になっているためです。このため、パソコンを取り扱うようにミニPCを取り扱えます。また、パソコン周辺機器がそのまま使えるため、拡張性が高い傾向にあります。ここでは例としてNUCの写真を図2に示します。ただし、コストや消費電力が高かったり、GPIOを備えていなかったりする弱点があります。

図2 NUCの写真
コプロセッサの特徴
コプロセッサは他のデバイスの処理速度を底上げできるという特徴があります。コストや処理速度、消費電力にも優れます。ここでは例として、Edge TPU USB Acceleratorの写真を図3に示します。ただし、このデバイス単体ではシステムを構築することができないという弱点があります。SBCやミニPCなどと組み合わせましょう。

図3 Edge TPU USB Acceleratorの写真
スマートフォンの特徴
スマートフォンは多くのユーザが持っているデバイスという特徴があります。また、センサも充実しており、カメラや慣性センサなどデフォルトで備わっていることが多いです。最初からインターネットと接続されていることが多く、エッジAIと対をなすクラウドAIとの相性が良いです。ポータブルで耐衝撃性に優れ、いいとこづくめです。読者の皆様は外見を知っていると思うので、写真は割愛します。ただし、目的に対して余計な機能が多い分コストが高かったり、電子工作するのは比較的苦手で拡張性が低かったりする弱点はあります。
市販のエッジAI用デバイスを仕様を比較
さて、SBCをはじめとしてエッジAIに使える様々な種類のデバイスがでてきました。それぞれの種類について具体的な製品名をあげるときりがないので、たくさんあるエッジAI用デバイスの中から、著者がピックアップしたものを表1と表2にまとめます。
表1 市販のエッジAI用デバイスの仕様一覧 (FP32:単精度浮動小数点数演算, FP16:半精度浮動小数点数演算、 INT8: 8ビット整数演算)
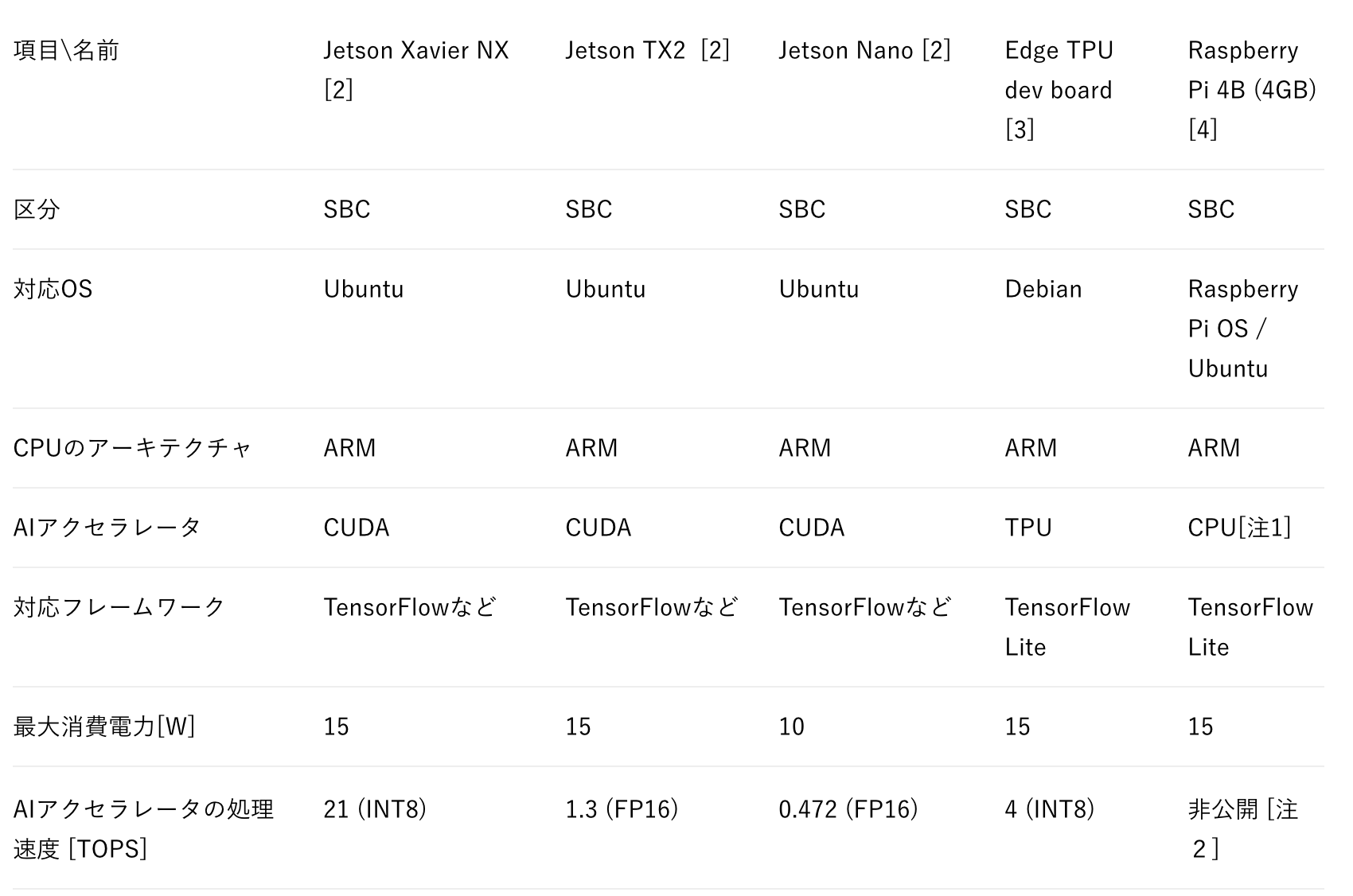
注1:Raspberry Pi 4にもGPUがありますが、アセンブリレベルで処理を書かない限りは、CPUのほうが処理が速いので、このようにしました。
注2:ベンチマークなどで測定はできますが、ここでは公開されている仕様ということで明記しません
※AIアクセラレータとはAIに対する処理速度を特にあげることができる処理装置のことです。
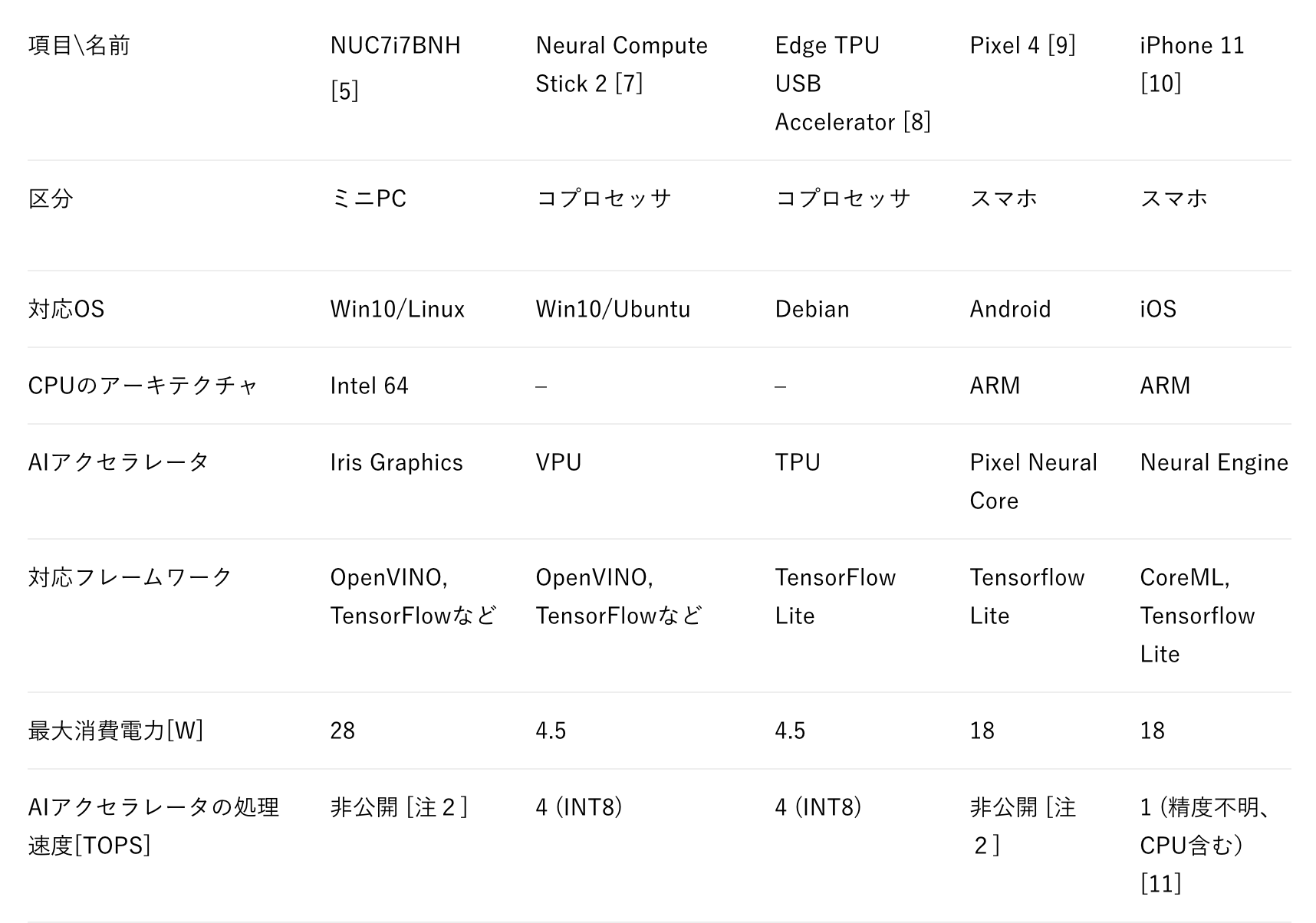
表2 市販のエッジAI用デバイスの仕様一覧(SBC以外)
エッジAI用デバイスによる画像認識テスト
さて、エッジAI用デバイスがたくさんでてきましたが、AIに対してどのような特性があるのかよくわかりません。そこで、実際に画像認識をさせて、エッジAI用デバイスの処理速度を比較してみましょう。
実験方法
今回はエッジAI用デバイスの数が多すぎるため、一部のデバイスを比較対象とします。デバイスに与える処理は骨格検出 (Human Pose Estimation) とします。この処理を100回繰り返して、その平均画像検出時間[sec]を求め、その逆数である平均処理速度[fps]を比べます。また、骨格検出の様子がわかるように可視化した図も合わせて表示します。骨格検出などの組み合わせを一覧にした実験条件を表3に示します。比較に使う画像は肖像権の都合上自分のプロフィール画像を使います。対象の画像を図4に示します。
 図4 実験時に入力として使う画像
図4 実験時に入力として使う画像
表3 デバイスなどの組み合わせによる実験条件

実験結果
Edge TPU USB Acceleratorで骨格検出した結果を可視化したものを図5に示します。なお、ほかのデバイスでも結果はほぼ同じなので可視化は割愛します。また、それぞれの条件における平均処理速度を図6に示します。
 図5 Edge TPU USB Acceleratorで骨格検出を行った結果
図5 Edge TPU USB Acceleratorで骨格検出を行った結果
(緑の点が目などの特徴点の位置であることを示している)

図6 各エッジAI用デバイスで骨格検出を行った際の平均処理速度
考察
Edge TPUは速いですね。処理速度と消費電力の兼ね合いに優れています。一方、Edge TPUに比べて、Jetson Nanoは平均処理速度が遅い上、消費電力も高いのは、なぜでしょうか。これには2つの理由があります。
1つはグラフィックス専用のプロセッサであるGPUを使っているとはいえ、Jetson Nano向けに調整されていない汎用的なWeb技術(Tensorflow.js)を使って実装しているためです。Jetson Nanoを活かすにはメーカーが提供している技術(TensorRT)を使うとよいそうです[16]。
もう1つはEdge TPUに使われているディープニューラルネットワーク (以下、DNN) が量子化されているためです。一般的にDNNは実数を扱うため、浮動小数点演算を行う必要が出てきます。このため、今回のJetson Nanoは浮動小数点演算でDNNを演算しています。しかし、この実数を量子化して整数で演算してしまえばいいのでは?という発想がハードウェア側からDNN初期から綿々と続けられてきました[17, 18]。それというのも実数を取り扱う浮動小数点演算の電子回路は論理的にとても煩雑な一方で、整数演算の電子回路は極めてシンプルであるためです。そこで、Edge TPUではDNNを浮動小数点演算ではなく、整数演算で処理しています。つまり、電子回路が論理的にシンプルであるため、Edge TPUは処理速度と消費電力の兼ね合いに優れていると考えられるのです。今回のJetson NanoではGPUが整数演算処理に対応していない[19]ので、この恩恵に預かれません。しかし、最新のJetson Xavier NXでは整数演算に特化しているため、Edge TPUと同じような効果が得られるかもしれません。
また、同じNUCで同じCPUでも、CPUとCPU内部のGPU(iGPU)で平均処理速度がおよそ3倍差になっていることがわかります。グラフィックボード(GPU)のほうが目立つため、iGPUは見落とされがちです。しかし、iGPUも処理速度が出ることがわかります。
余談ですが、今回の推定方法は人数が増えてもほとんど平均処理速度は変わりません。これは、OpenPoseのようなボトムアップ・アプローチを使っているためです。この性質はおおよそ処理時間を一定にすることが望まれるエッジAIには好まれる特性です。また、各検出方法のネットワーク構造は MobileNetV1ベースであることから、手法間に大幅な違いはありません。
エッジAI用デバイスの今後の展望予想
今後は微細化などの限界から演算装置そのものが速くなることは見込み薄いです。このため、用途を限定したコプロセッサを設計していくことになるのでしょう。たとえば、演算装置の電子回路を整数演算の畳み込みに特化していくと考えられます。他にもまだ動画認識の定番アルゴリズムができてくれば、それ専用のコプロセッサができるのだと思われます。
また、データの入出力を高速化することにより処理速度を上げていくと期待しています。AIではデータの入出力が処理速度の障害になることがたくさんあります。そこで、CPUとGPUの帯域幅を広げたり、GPUのメモリの量を増やしたりしてデータの入出力を高速化していくと思われます。さらに、極端な例だと、データ入出力を高速化させるためにセンサの素子に処理用の素子をくっつけた製品が出てきています[20]。
まとめ
今回はエッジAI用デバイスの仕様や画像検出速度を比較し、今後の展望について述べました。結論から言うと、たとえ似たようなデバイスで同じようなアルゴリズムであったとしても、ソフトウェアやハードウェアの実装によって画像検出速度がかなり変わることがわかりました。コミュニケーションロボットなどの、エッジAIによるシステムを構築する際に本記事の内容がお役に立てば幸いです。
なお、余談ですが、世界最速のスーパーコンピュータである富岳は約416,000 [TOPS] (FP64) で、消費電力は28,500,000[W] [21] です。
やばいですね。
参考文献
[1] 小林啓倫, “なぜクラウドではダメなのか? いま「エッジAI」が注目されるワケ”, https://www.itmedia.co.jp/news/articles/2003/19/news050.html
[2] “Jetsonの各開発キットを比較!選び方も合わせて紹介!”, https://www.macnica.co.jp/business/semiconductor/articles/nvidia/133162/
[3] “Dev Board datasheet”, https://coral.ai/docs/dev-board/datasheet/
[4] “Raspberry Pi 4”, https://www.raspberrypi.org/products/raspberry-pi-4-model-b/
[5] “インテル® NUC キット NUC7i7BNH”, https://ark.intel.com/content/www/jp/ja/ark/products/95065/intel-nuc-kit-nuc7i7bnh.html
[7] “Intel® Neural Compute Stick 2”, https://ark.intel.com/content/www/us/en/ark/products/140109/intel-neural-compute-stick-2.html
[8] “USB Accelerator datasheet”, https://coral.ai/docs/accelerator/datasheet/
[9] “Pixel スマートフォンのハードウェア技術仕様”, https://support.google.com/pixelphone/answer/7158570?hl=ja
[10] “iPhone 11”, https://www.apple.com/jp/iphone-11/specs/
[11] Andrei Frumusanu, “Apple Announces New iPhone 11, iPhone 11 Pro, & iPhone 11 Pro Max”, https://www.anandtech.com/show/14859/apple-announces-new-iphone-11-iphone-11-pro-iphone-11-pro-max
[12] “@tensorflow-models/posenet”, https://www.npmjs.com/package/@tensorflow-models/posenet/v/1.0.3
[13] “node-red-contrib-tf-model”, https://github.com/yhwang/node-red-contrib-tf-model#note
[14] “Coral PoseNet”, https://github.com/google-coral/project-posenet
[15] “human-pose-estimation-0001”, https://docs.openvinotoolkit.org/latest/ _models_intel_human_pose_estimation_0001_description_human_pose_estimation_0001.html
[16] https://twitter.com/terryky1220/status/1271410014498861056?s=20
[17] Itay Hubara et al., “Binarized Neural Networks”, NIPS 2016
[18] Benoit Jacob et al., “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference”, CVPR 2018
[19] “Why jetson nano not support int8”, https://forums.developer.nvidia.com/t/why-jetson-nano-not-support-int8/84060
[20] “Sony to Release World’s First Intelligent Vision Sensors with AI Processing Functionality”, https://www.sony.net/SonyInfo/News/Press/202005/20-037E/
[21] “日本の「富岳」が世界最速スパコンに–世界ランキング「TOP500」”, https://japan.cnet.com/article/35155694/
[22] M.G. Sarwar Murshed et al., “Machine Learning at the Network Edge: A Survey”, arXiv
Author