Blog
SIGGRAPH Asia 2021参加報告
AI Labの武富です。2021年12月14日から2021年12月17日にかけて、コンピュータグラフィックス分野の国際会議であるSIGGRAPH Asia 2021が開催されました。昨年はオンライン開催でしたが、今年はオンサイトとオンラインのハイブリッド開催となりました。SIGGRAPH Asia 2021でサイバーエージェントはゴールドスポンサーを務めました。この記事では、会議全体の概要、スポンサー展示の様子、Technical Paperの中で面白いなと思った研究(独断と偏見による)を簡単に紹介しようと思います。

オンサイト会場の様子
SIGGRAPH Asia 2021全体概要
SIGGRAPH Asia 2021は冒頭でも書いた通り、オンサイトとオンラインのハイブリッド開催となりました。ハイブリッド開催はSIGGRAPHの歴史で初とのことです。オンサイトの会場は東京国際フォーラムで、ここは2018年のSIGGRAPH Asiaが開催された会場と同じです。会場内にはKeynote Talk、Technical Papers、Real-Time Live聴講のための部屋や企業展示、Emerging Technologiesなどの展示スペースが用意されていました。
Technical Papersのセッションでは、Zoomを用いて採択論文に関する紹介動画が流れた後、Zoomのチャット機能を用いて質問を受け付ける形で質疑応答が行われました。私が聴講したセッションに関しては、オンラインの参加者は多くても100名程度だったように思います。オンサイト会場も30-40名程度だったように思います。オンデマンドで発表動画が観れるようになっていると、多くの参加者は時差の問題もあるのでそれぞれが都合の良い時間帯に視聴するようになるんでしょうか。また、夏に開催されたSIGGRAPH 2021では各セッションの著者同士が議論する時間がありましたが、SIGGRAPH Asia 2021ではその時間はありませんでした。研究領域が近いトップレベルの研究者同士が色々と議論していることを聞くことはあまりないので、個人的に著者間でのパネルディスカッションは復活して欲しいなぁと思っています。
Emerging Technologiesの展示スペースでは、様々なデモ展示が行われていました。中でも高速に物体を追跡しながらプロジェクションマッピングを行う技術の展示が完成度が高く興味深かったです。というのも、これに関連する研究についてはいくつか論文を読んだことはあったのですが、実物を見るのは始めてで、実際に500fpsでプロジェクションが行われていると遅延をほとんど感じないということを実感でき感動しました。論文を出して満足するのではなく、実際に動くものを作って見せることでより説得力のある研究成果にすることが出来るのだと思いました。
上記のセッション以外にも様々なセッションがオンライン、ハイブリッドで開催されていましたが、特に良かったのは、各日に発表された内容について、座長を担当された日本の先生方が発表論文を解説する「Digging into the Technical Papers」のセッションです。これについては、配信無し、録画や撮影不可という条件で開催され、各発表に関して本音で印象などを語られていたのが新鮮でした。また、論文紹介をされた先生方のパネルディスカッションでは、「SIGGRAPHに論文を通すためには?」のようなお題で議論がなされており、とても参考になりました。ざっくりとまとめると、考え続けること、手を動かすこと、といった基本的なことを発表された先生方は当たり前のように行っているということだったかと思います。
スポンサー展示
冒頭にも書いた通り、SIGGRAPH Asia 2021でサイバーエージェントはゴールドスポンサーを務めました。スポンサー展示では、出張型3DCGスキャンカー「THE AVATAR TRUCK」を展示ブース内に持ち込み設備見学および予約制の撮影体験を実施しました。持ち込んだAVATAR TRUCKは会場内では一際目立っており、「あのトラックはなんだ?」と思って来た方が多くいらっしゃり集客効果抜群でした。また、用意した撮影体験の予約枠は全て埋まり、3日間で約30名ほどの方にスキャンの体験をして頂くことができました。体験して頂いた方の中には、国内の著名なコンピュータグラフィックスの先生方もいらっしゃり、スキャン技術に関する注目度の高さが伺えました。

展示ブースの様子
また、展示ブースでは、各日1‐2回、サイバーエージェントにおけるコンピュータグラフィックス技術の広告制作への応用に関する研究開発について紹介を行いました。コロナ禍で海外からの入国制限措置もとられている状況で来場者はかなり少ないんじゃないかと不安でしたが、各回10名ほどの方に集まって頂くことができ、誰も来ずに寂しい思いをするということが無く安心しました。ただ、久しぶりの対面での研究紹介だったこと、毎回知り合いの研究者が目の前に座っていること、でかなり緊張しました。。。

研究紹介の様子
研究発表ピックアップ
EyelashNet: A Dataset and A Baseline Method for Eyelash Matting
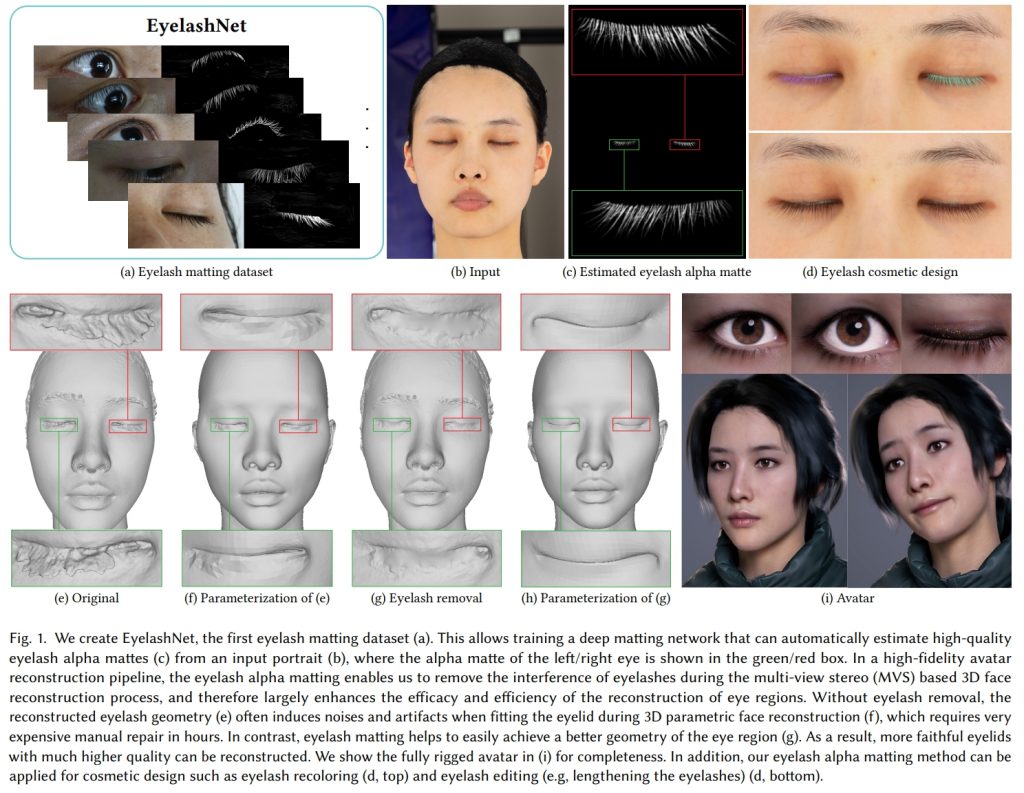
図は元論文より引用
論文タイトルの通り、まつげを検出するための方法の提案です。まつげなどはスキャンをした際にうまく復元することが難しくノイズになってしまうという問題があります。これは、我々のAVATAR TRUCKを使ったスキャンシステムでも同様の問題が生じており、この研究は我々のスキャンシステムの品質を向上させていく上でも重要な研究だと思いました。研究のアイデアはシンプルで、まつげに紫外線を当てた際に発行する物質を塗布しておき、通常の照明、紫外線照明の2種類の照明を当てて得られる画像の差分からまつげ領域を検出するというものです。この研究では、この撮影方法で取得したデータセットを用いて、まつげ領域のAlpha Matteを生成するネットワークについても提案しています。
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
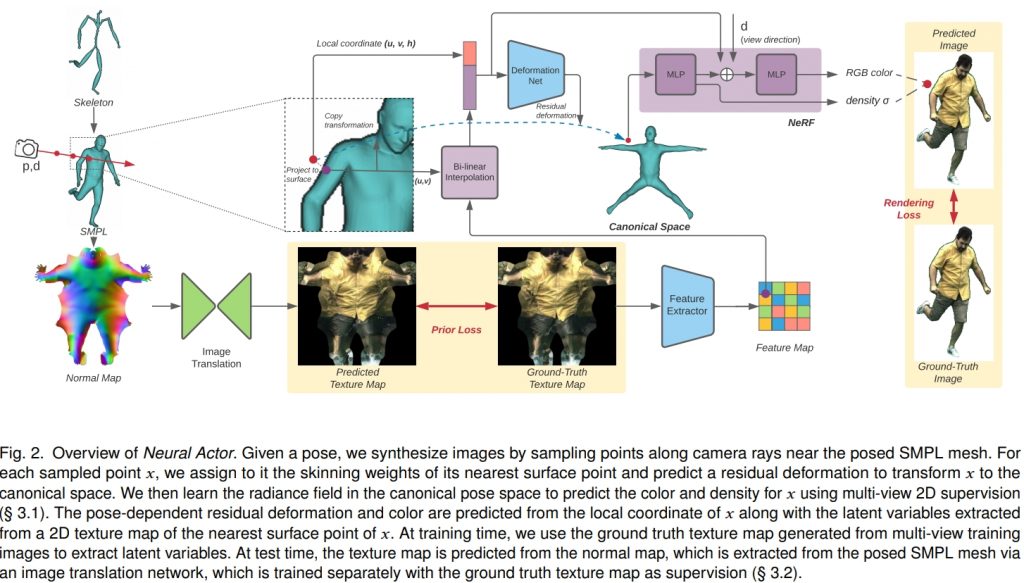
図は元論文より引用
この研究では、多視点撮影した動画像から、アニメーション可能なフォトリアルなアバターを作成する方法を提案しています。人物の動きをCanonical spaceにマッピングするために人体のテンプレートモデルであるSMPLモデルを用いています。その上でNeural Radiance Fields (NeRF)を推定することで任意の視点の映像を生成しています。ただし、人体姿勢から形状・見た目へのマッピングは1対1対応でないため精細な映像を生成することが難しいという問題があります。この問題を解決するために、この研究では、中間表現として2Dのテクスチャマップを潜在変数として用いています。これにより、フォトリアルな映像の生成を達成しています。
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
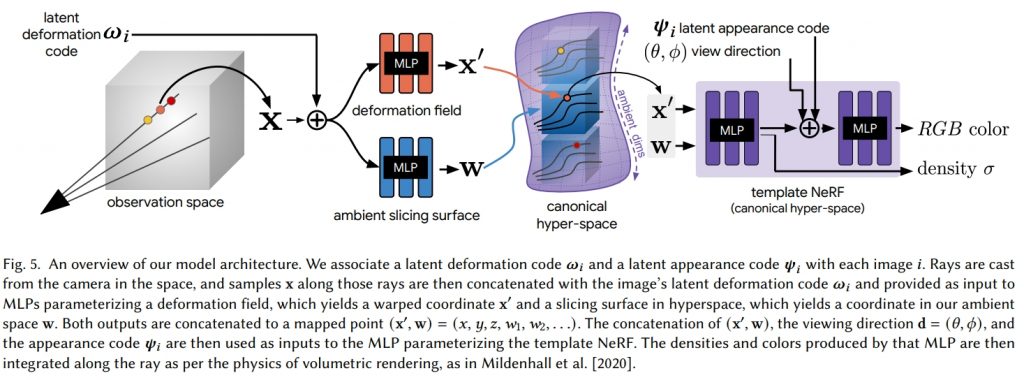
図は元論文より引用
この研究では、動的なシーンに対するNeRF表現の提案を行っています。これまでにもNerfiesのように動的なシーンに対するNeRF表現は提案されているのですが、トポロジーが大きく変化するような場合(口を開くなど)にはうまくCanonical spaceへの変換ができないという問題がありました。そこで、このHyperNeRFでは、レベルセット法の考えを取り入れ、あらたにambient dimensionと呼ぶ新たな次元を追加した高次元空間でNeRF表現を学習しています。結果動画の中では、従来は困難であったクッキーが2つに割れるようなトポロジーが大きく変化するシーンに対しても高品質な新視点画像生成を実現できていることを確認できます。
おわりに
この2年間でオンライン開催の学会にはいくつか参加しましたが、移動の時間が無いため参加のし易さはあるもののなかなか他の参加者とコミュニケーションをとるのは難しいなと感じていました。今回、久しぶりにオンサイトで学会に参加して、知り合いの先生方などと他愛もない話をしたり、研究の話をしたり、近況について情報交換したりすることがあり、オンサイト参加ならではのメリットを再認識しました。また、デモ発表については、やはり画面越しに見るのに比べて圧倒的に実物を見た方がそれぞれの技術の良さが分かるように思います。COVID-19が早く収束し学会のオンサイト開催が復活することを願います。その際には、Technical Paperの発表者として登壇できるように、インパクトの高い研究課題にAI Labのメンバと取り組んで行こうと思います。
Author