Blog
映像要約評価再考
AILabの大谷です。主に画像/映像+自然言語に関係する研究をしています。映像の編集結果を評価する方法についての私の論文がCVPR’19採択されたので、今回はその内容を一部紹介します。論文と実装はProject Pageで公開しています。
映像要約
映像の自動編集は、コンピュータビジョンでは映像要約(video summarization)と呼ばれています。長時間撮影されたホームビデオ、監視カメラの映像など長い映像の視聴は大変です。映像要約は重要な箇所を自動で抽出して、短時間で内容を把握できるようにします。これまで研究コミュニティでは様々な方法が検討されてきました。例えば、人の注意を引くような色や動きのある箇所を抽出する、視覚的に似たような映像を除去していくなど、なんとかして動画の中から重要なシーンだけを残す方法が提案されています。
映像要約の評価
映像要約手法で作成された映像を評価する方法は主に2つあります。1つはアンケート調査です。人間による評価はある意味理想的な方法ですが、再現性を担保することが難しく、手法の比較が困難です。もう一方は共通のデータセットと自動評価ツールを使った評価です。中でも代表的なものが、SumMe1とTVSum2データセットです。これらのデータセットは複数の映像と人間によるお手本を提供しています。新しく開発した映像要約手法を評価するときは、このデータセットの映像を使った要約映像を作成し、出力映像とお手本のオーバーラップの大きさ(F値)で評価します。SumMeは人間が作った編集済みお手本映像を提供していますが、TVSumは人間が2秒ごとにラベル付けした重要度のみを提供しています。TVSumはスタンダードな映像要約ツールも提供しており、評価の際には出力映像の長さやショット分割のタイミングなどを設定し、重要度スコアに基づいたお手本映像を作成します。
今回はこれらのデータセットを使って算出されるスコアの妥当性を調査した結果をまとめます。「評価指標」の評価というとややこしい話ですが、実験は単純です。正解映像として提供されているお手本要約映像のスコアと適当に作ったランダムな要約映像のスコアを比較します。お手本要約映像は人間によるアノテーションを使っているため、可能な要約結果の中でも良いものだと考えられます。それに対して、ランダムな要約映像は内容を見ずに編集しているようなものなので、めちゃくちゃな要約映像になっているはずです。お手本要約映像のスコアはこの評価指標における一種の上限、ランダムな要約映像のスコアはベースラインと考えることができます。まっとうな評価指標であればこれらのスコアの間にはある程度の差が生じるはずです。またショット分割のタイミングを決める手法を複数試し、ショット分割による影響も調査しました。
要約映像評価の問題
TVSumでは評価値がショット分割で決まる
今回の実験の結果、TVSumを使った評価はほとんど機能していないことがわかりました。
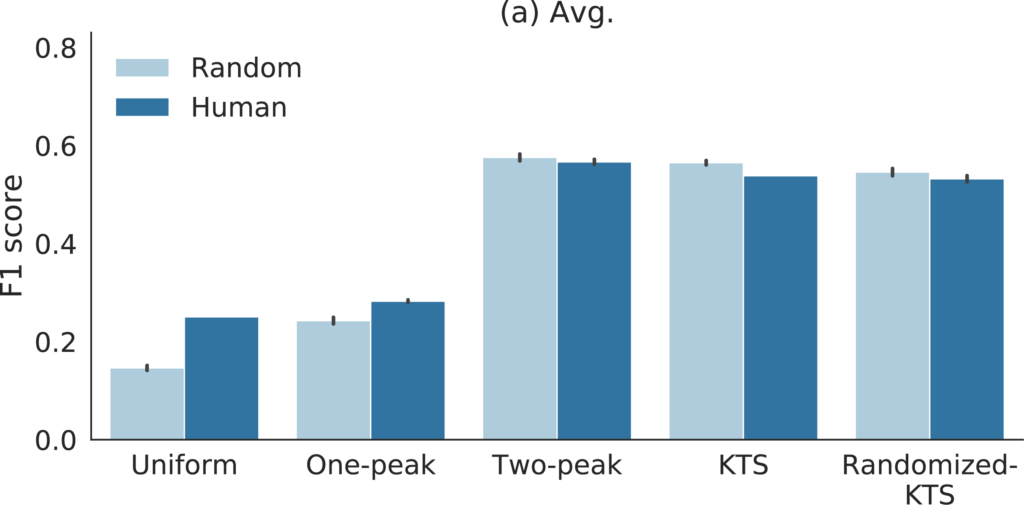
重要度をランダムにして作った映像とお手本映像の比較
濃い青がお手本要約映像(Human)のスコア、薄い青がランダムな入力をもとに作成した要約映像(Random)のスコアです。Uniform, One-peak, Two-peak, KTS, Randomized-KTSはショット分割の手法を表しています。なんと3つの設定で適当に作った映像がお手本を上回るスコアを出しました。それぞれの設定で100回の評価(黒いバーは95% confidence interval)をしているのでまぐれ当たりではないでしょう。
このようにTVSumでは多くの設定でランダムな要約映像がお手本要約映像と同等、あるいはそれ以上と評価されることが確認できました。これはTVSumを使った評価に深刻な問題があるということを示しています。
詳しい話は割愛しますが、実はTVSumを使った評価ではショット分割の手法でスコアがほぼ決定されます。これはTVSumがお手本映像を作成するときに使っているスタンダードな映像要約方法に原因があり、要約映像作成の過程でショットの長さ以外の要素はほぼ無視されるようになっているためです。つまりこのスタンダードな映像要約方法を使っている限り、ショット分割方法が同じなら重要度推定などを工夫しても最終的な出力は概ね同じ映像になります。
ちなみにKTSはよく使われているショット分割手法です。最近の論文を見てみると、KTSを使ったランダムな要約映像のスコアと提案手法のスコアがだいたい一致していることがわかります。ここ最近の研究では、深層学習や強化学習で重要度を推定する手法が盛り上がりを見せていましたが、これらのアプローチの有効性について議論を見直す必要が出てきました。
SumMeではベースラインがショット分割で変わる
SumMeは人手で編集したお手本映像を提供しているので上記のような問題は起こりません。しかし評価指標の使い方についてはいくつか課題が明らかになりました。
SumMeは各映像に15-18本のお手本映像を用意しています。このお手本映像との類似度について2つの考え方があります。一つはお手本映像それぞれと類似度を計算してその平均を評価値とする考え方。もう一つは平均値の代わりに最大を取る考え方です。これはある映像に対して複数の良い要約映像が存在するはずなので、そのうちの一つと一致していれば十分という主張に基づいています。これら異なる評価値は比べられるものではないので混同しないよう注意が必要ですが、論文ではどちらを使ったか明確に書かれていないことがあります。当然最大値を取るほうが評価値が高くなるので、複数の手法を比較している場合は評価値の算出方法が揃っているかチェックすることが重要です。
またSumMeでも上記と同様、ランダムな処理を挟んだ要約映像を評価してみるとショット分割による影響が確認できます。ショット分割によりスコアのベースラインが変化するので、ある手法でどれだけ要約が改良されたのかを知るためには設定を揃えたランダム映像との比較が重要になります。
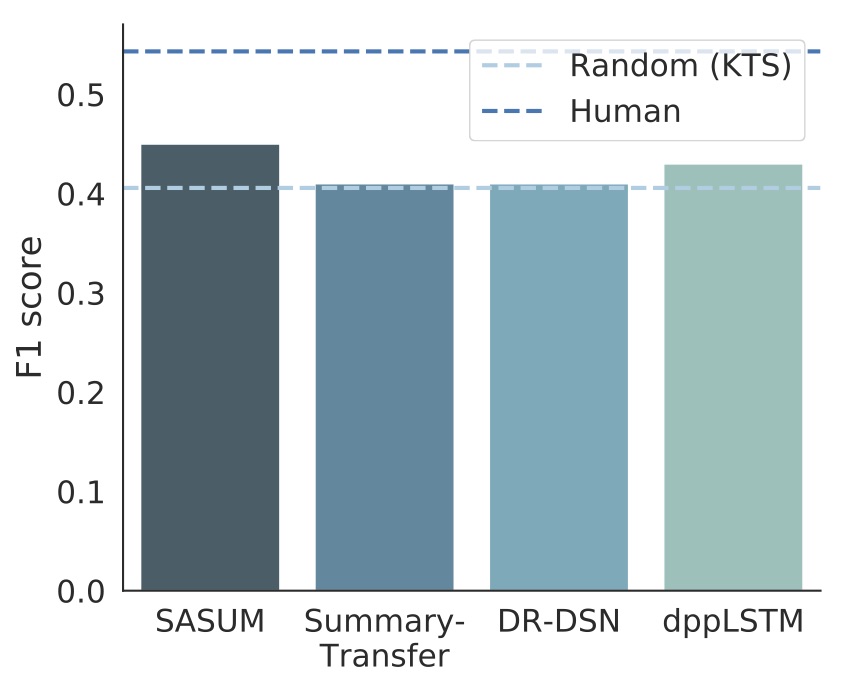
最近の映像要約論文で報告されているSumMeにおけるスコア。薄い青の破線は設定を揃えたランダムな要約映像のスコア。
今回の結果から少なくともTVSumは映像要約ベンチマークとして機能していないといえるでしょう。またSumMeの評価指標の使われ方にもなかなかに混乱があるようです。詳しい話は論文に書いているので映像要約の研究をこれからする人はぜひ一度チェックしてみてください。フィードバックも歓迎です。
おわりに
最近は大規模なデータを使った共通のタスクに取り組み、その精度を競いあうことで研究開発が進められています。共通のタスクにおいてスコアを更新することは論文の評価における重要な要素の一つになっており、研究コミュニティでは評価指標に合わせて最適化した手法を作ることに強いモチベーションが生じています。特に機械学習全盛の今は評価指標とデータセットのデザインが分野全体の研究を方向付けているといえるでしょう。
しかしタスクが複雑になるほど評価指標の設計自体が困難になり、今回の例のようにあまり意味のない数字に基づいて議論が進められる危険性があります。同様の問題を現状内包している分野は他にもありそうです。今後このような問題に対しては、地道に評価指標とデータセットを検証していく必要があるでしょう。
- M. Gygli, H. Grabner, H. Riemenschneider, and L. van Gool, “Creating summaries from user videos,” in European Conference on Computer Vision (ECCV), 2014, pp. 505–520. ↩
- Y. Song, J. Vallmitjana, A. Stent, and A. Jaimes, “TVSum : Summarizing Web Videos Using Titles,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 5179–5187. ↩
Author