Blog
CVPR 2020 参加報告
はじめに
AI Lab の下田です。6月に開かれたコンピュータビジョンの国際会議,CVPR2020 に参加してきました.本年度のCVPRは例年の会議とは異なり,世界情勢の影響からVirtual開催でした.オフィスからの参加でしたが,簡単に報告させていただきます.

CVPR2020
CVPRはICCV/ECCVとともにComputer Vision分野におけるトップカンファレンスの一つです.CVPRは毎年アメリカで開催される会議なのですが今年はVirtual開催となっています.会議の開催期間は例年から変更なく6月14日から6月19日の5日間でした.ここ数年CVPRの参加人数は指数関数的に増えていたのですが,Virtual開催の影響からか今年の参加人数は減少しています.
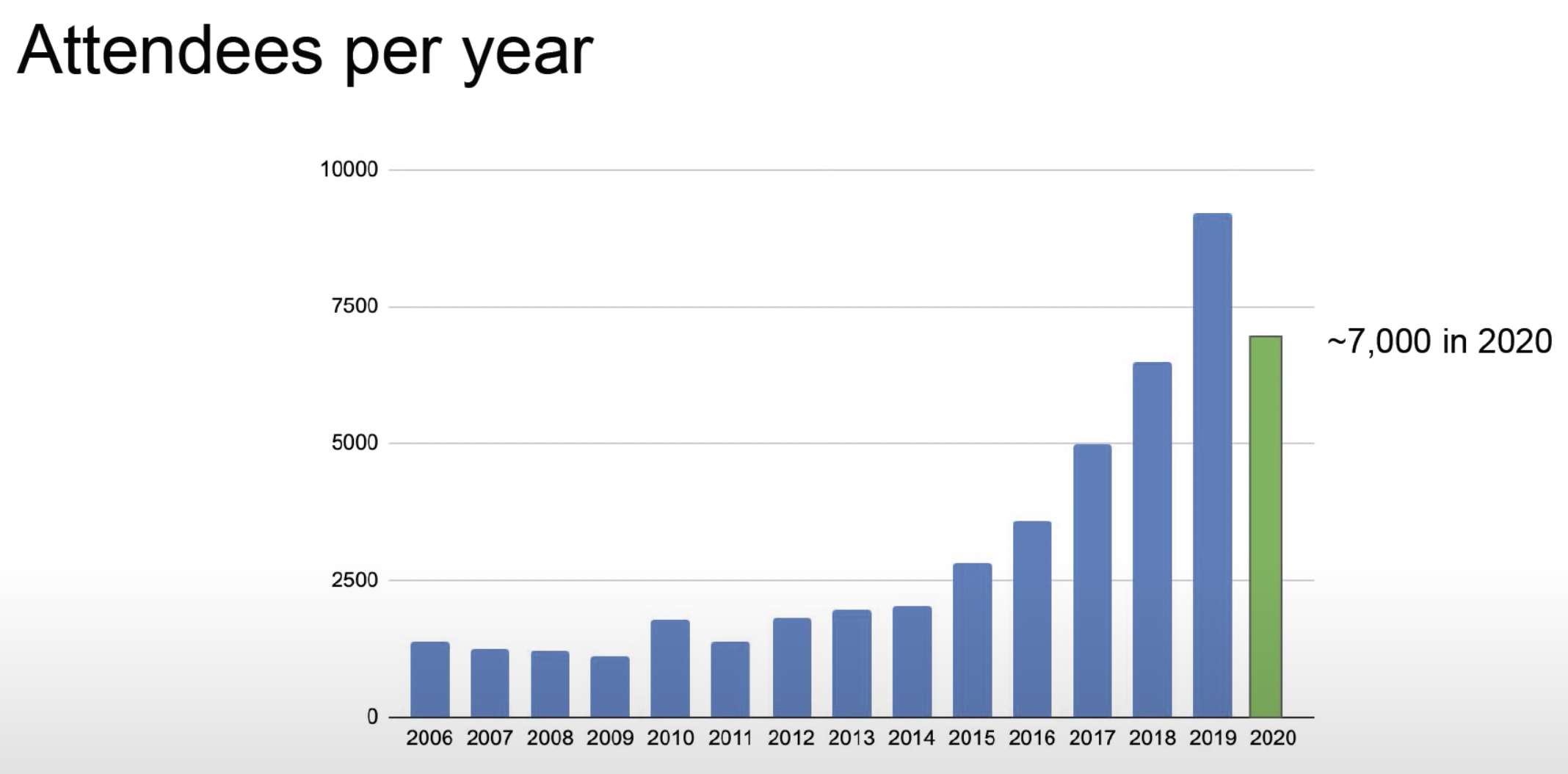
CVPRのVirtual開催の形式ですが,基本的には下の画像のような論文リストの中からページを移り,ウェブサイトに配置してある動画を各自で眺め,特定の時間帯にZOOMを利用して著者の方と話をするという形でした.個人的には、ZOOMに参加して著者の方と話をするというのは通常のポスターセッションと比較して話しかける敷居が高いように感じました.また,例年のポスターセッションでは目に留まったポスターの話を聞きに行くことがしばしばありましたが,今年のVirtual開催では気になる研究のタイトル一覧から動画を探すので確認する論文に偏りが出てしまったかなという印象があります.一方で,例年のオーラルセッションは平行して複数の発表が行われるので全ての発表を聞くのは難しかったのに対して,今年は動画の視聴という形式だったので見たい発表が重なり困るという問題は起こりませんでした.Virutual開催ならではのメリットデメリットそれぞれ確認できたと思うのですが,個人的にはVirtualで参加するより現地で発表を聞けたほうが得るものは多いのではないかなと感じました.とはいえ,刺激的な研究発表を多く聞く良い機会になり,Virutual開催でも参加して得るものは多くありました.今後もこのような世界情勢が続く可能性がありますが,次第に改善していくかもしれないので期待したいです.

本会議論文紹介
CVPRでは多様な研究が発表されていましたが,ここでは生成系と分析系とテキストを扱った研究を私の偏見でカテゴリに分けて紹介いたします.
生成系
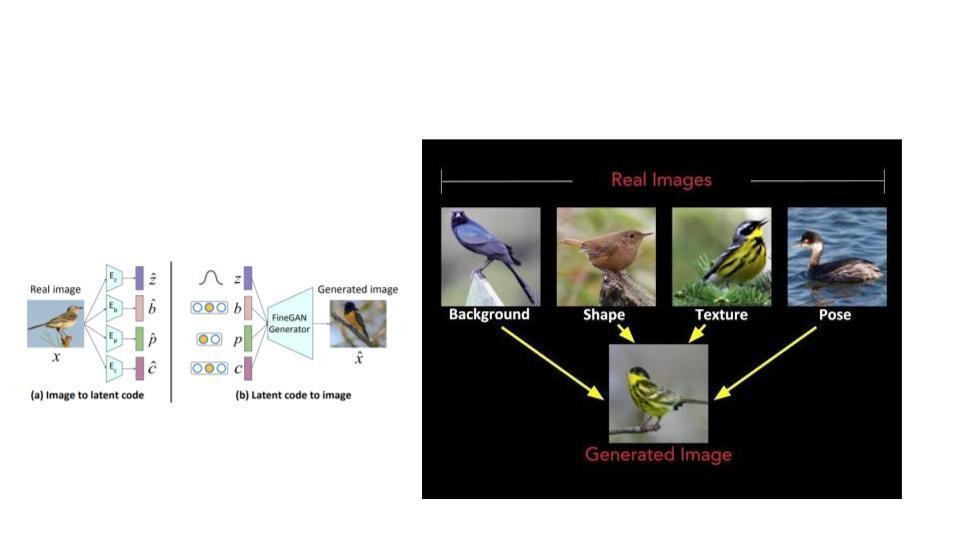
MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation
こちらは特徴量の分離(Disentangle) + 画像生成の研究です.この研究では鳥の画像について4つの属性情報を指定し生成モデルに渡し、属性の情報が反映された画像を生成する手法を提案しています.動画とデモサイトがVisualで面白いのでぜひご確認ください.今年はこのような画像生成を行う際にConditionalな情報を与えて生成結果をコントロールするという研究が多くありました.この論文はその中でも4つの属性が指定可能であることと,生成された画像のクオリティが高く興味深かったです.ただ,デモサイトを触った印象として,属性情報の指定方法が画像になっているのは少し不便に感じました.今後は画像以外の情報で属性を指定可能な手法が出てくるのかなと期待しています.
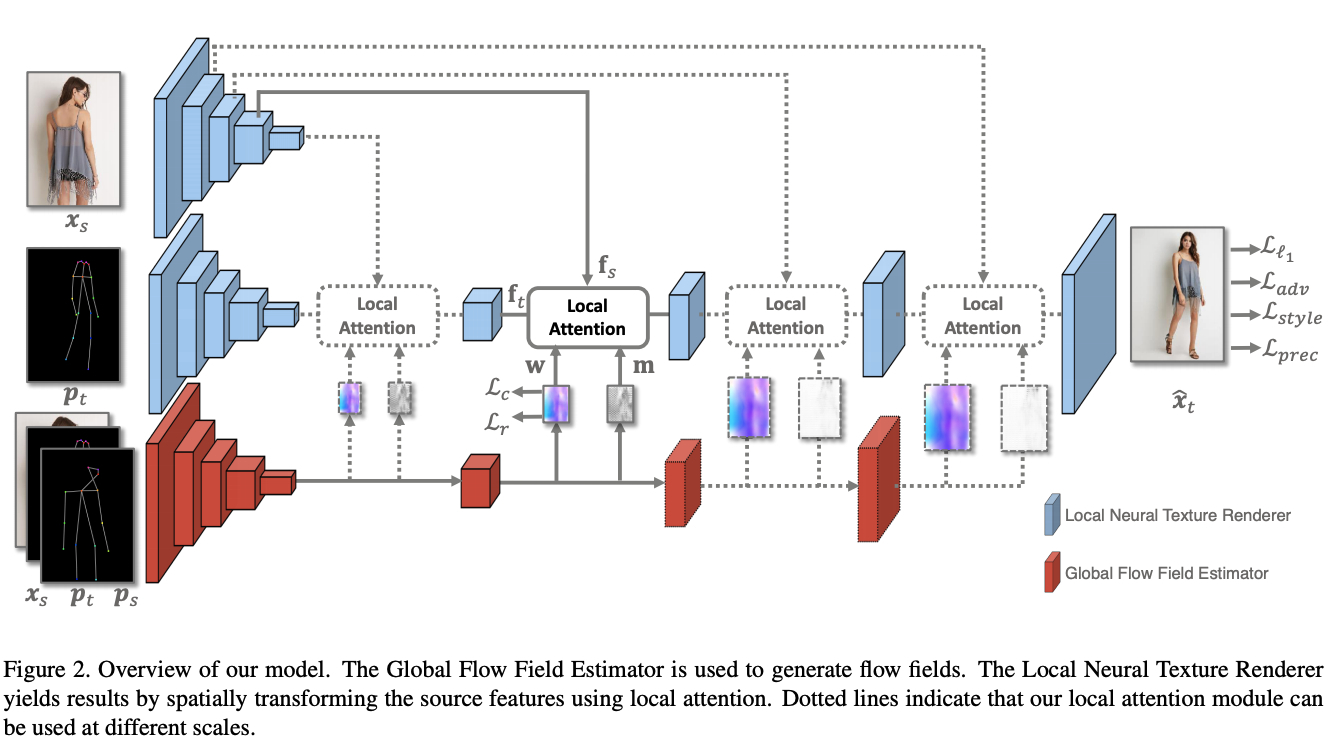
Deep Image Spatial Transformation for Person Image Generation
この論文はPoseとOptical flowから動きを含む人の動画を生成しています.こちらもクオリティがすごいのでぜひ動画をみてください.実応用可能なレベルにかなり近づいているように見えます.
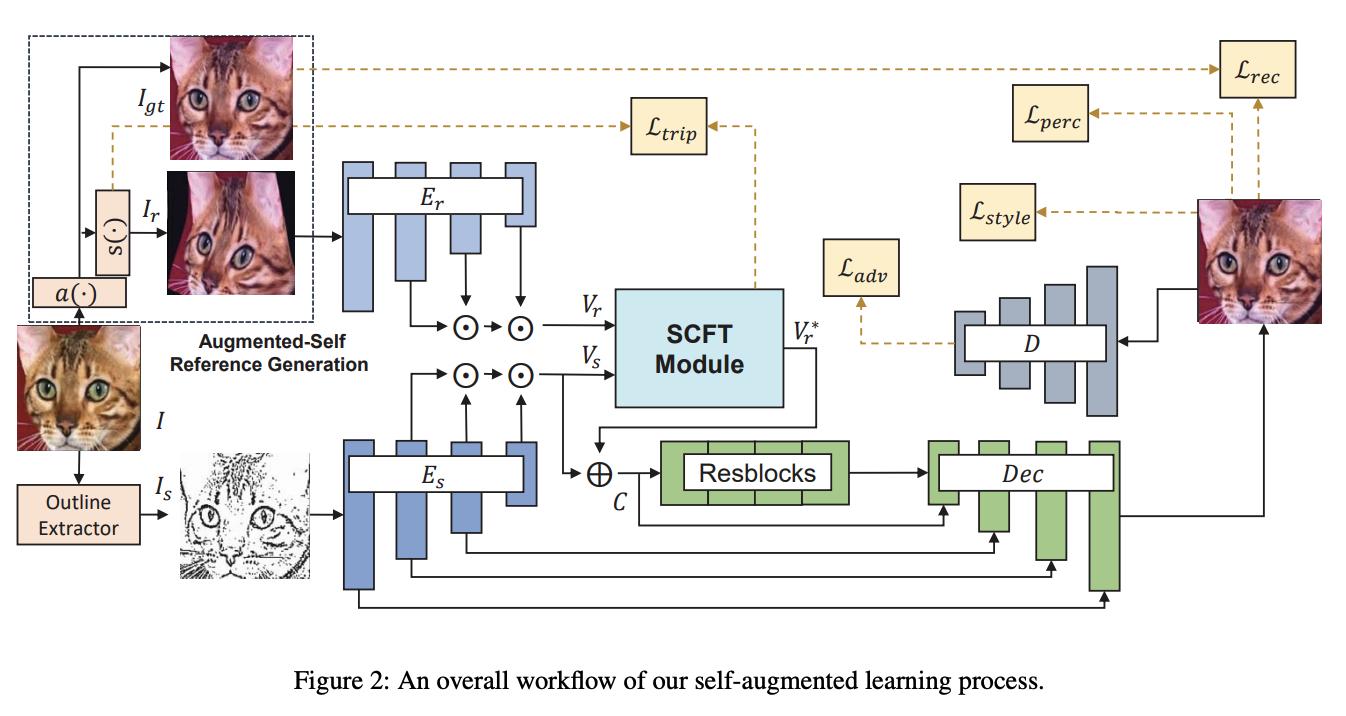
Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence
こちらの論文は参照画像の色情報を対象画像に転写するという色情報についてのStyle transferの手法を提案しています.この論文では画像間のCorrespondenceをSelf-supervised learningで学習することで既存手法と比較してかなり高いクオリティを達成しています.下に画像を表示していますが,綺麗に詳細な色の情報を転送できています.CorrespondenceをSelf-supervised learningで学習する論文[pdf]が去年発表されていたのですが,これを生成系に活かした研究が一年後に発表されていて研究スピードの速さを感じました.さらに,こちらの研究は脱色された画像を使い情報をわざと落とすことで,Correspondenceの性能向上を達成しているようにも見えます.このCorrespondenceの学習方法はシンプルだったので実装してみたのですが,スケールの近い物体間では結構うまくいきました.ブラッシュアップすればさらに良くなる気もします.複数のタスクを組み合わせて一つの目的を達成するという研究が生成系でも流行していく可能性を感じました.


[pdf]
分析系
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
こちらの論文はこれまでの回帰によるDetection手法の二つを比較し,違いを検証しています.回帰によるDetectionの手法としては各ピクセルに設定しているAnchorの座標情報と物体の矩形の座標情報の誤差を推定するアプローチと,ピクセルから矩形への距離の座標情報を推論するアプローチの二パターンがありました.矩形の距離の座標情報を推論するアプローチが後発なのですが,どちらが良いのかはこれまで明らかになっていませんでした.この論文ではこれらがどちらも本質的には同じものを推論しており,教師情報の与え方が異なるだけで,推論精度は変わらないはずであるとのことでした。著者らはこれを実際に実験結果から示しています.実装の手間としてはAnchorベースのアプローチの方が大変なので,矩形についての距離を推論する手法が良いのかもしれません.
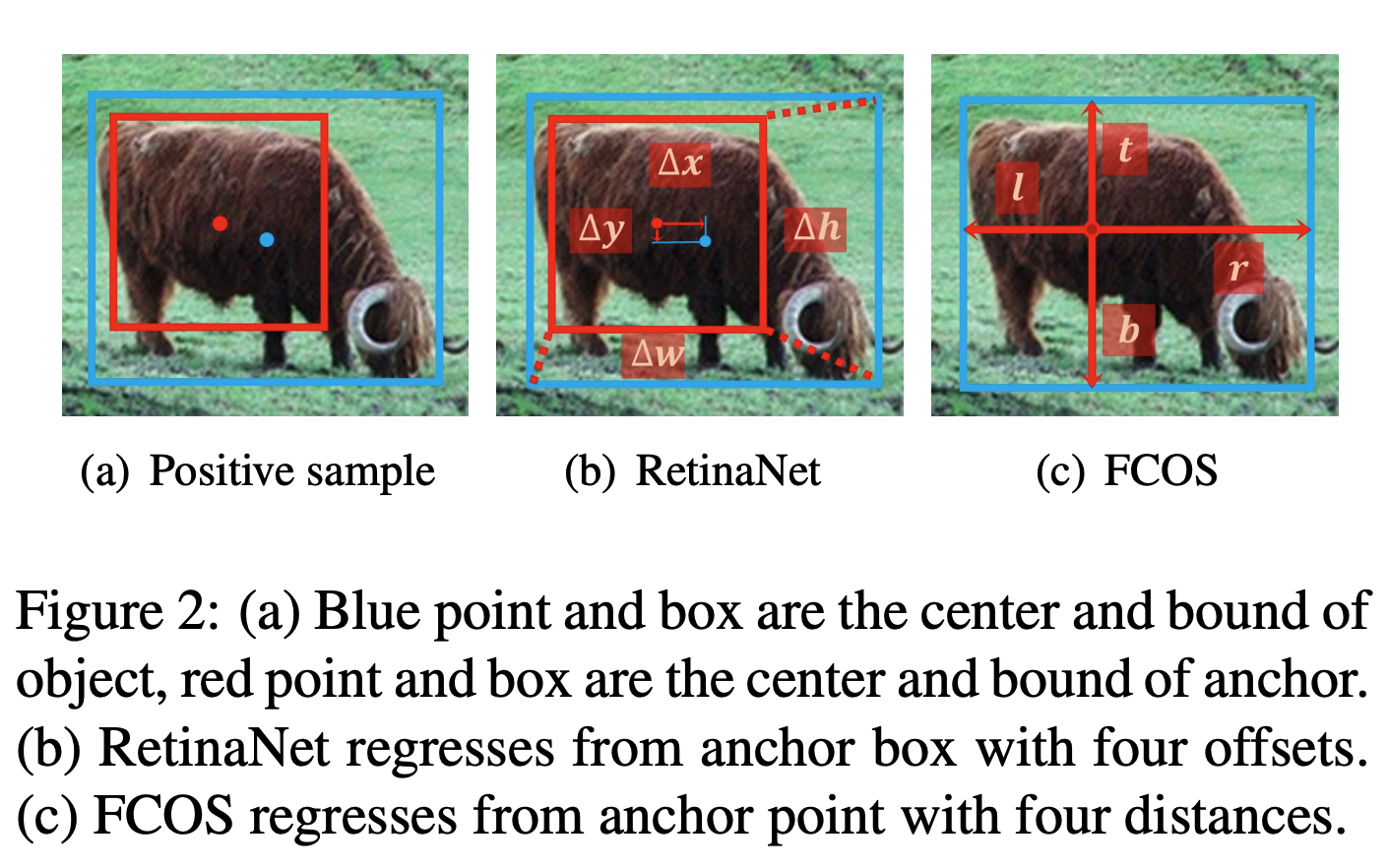
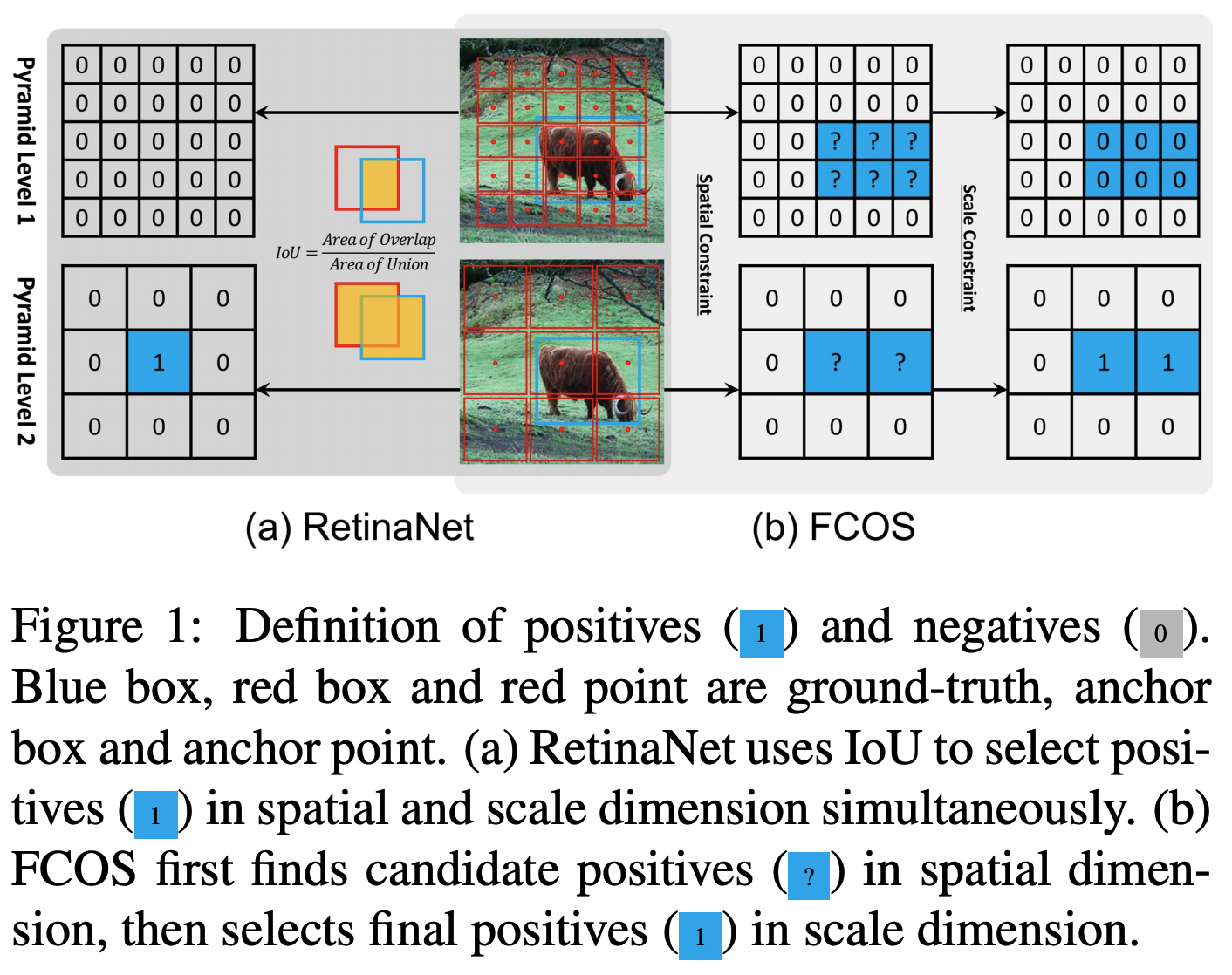
[pdf]
What Makes Training Multi-modal Classification Networks Hard?
こちらはMulti-modalデータを使った学習についての論文です.この研究では複数の種類が異なるデータを入力に使った時に,情報量が増えているのになぜか精度が下がってしまうという現象について原因を明らかにし,対策方法を示しています.具体的には,動画と音の情報を入力としたモデルより,動画のみを入力としたモデルの推論精度の方が高くなってしまうというものです.
結論としては,原因は音の情報を使った推論がすぐに過学習してしまうからだというものでした.片方の情報が過学習してしまうと,そちらの情報を使って推論しがちになってしまい、汎化性能が下がってしまうとのことです.論文では,さらに,Multi-modalデータの過学習を防ぐ手法を提案し,推論精度の低下を防ぎ精度向上を達成しています.複数の異なるタイプの情報を組み合わせた結果に対して,もっと精度が良くなって欲しいようにも感じる上昇幅ですが,そもそも動画で推論できず,音を使って推論可能な対象がほとんどないのかもしれません.論文では動画と音情報を扱っていますが,他のMulti-modalデータにも同じことが言えそうです.Multi-modalデータは広告関連の研究においても扱う機会が多いので気をつける必要がありそうです.
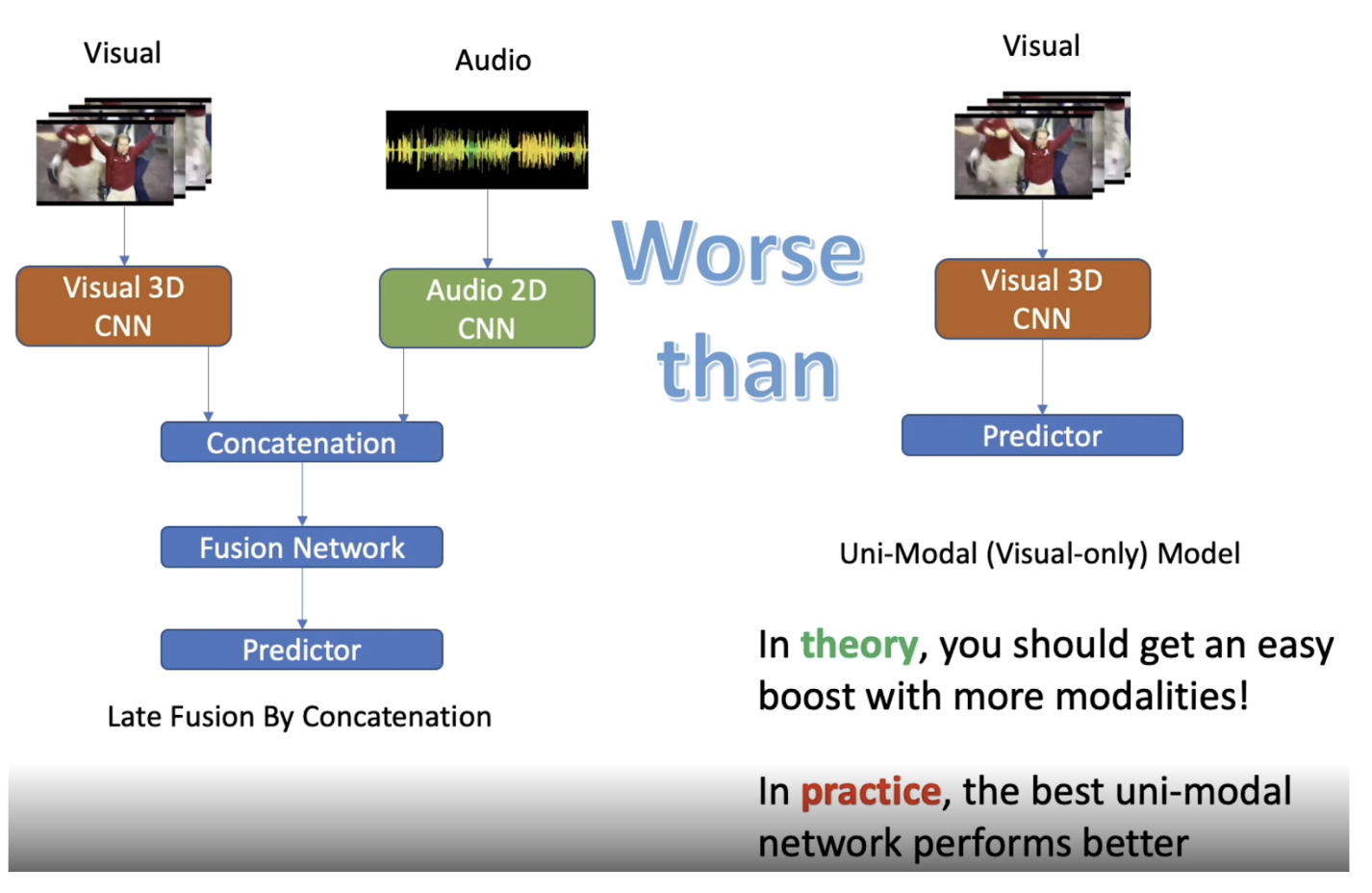
[pdf]
テキスト系
UnrealText: Synthesizing Realistic Scene Text Images From the Unreal World
この研究ではテキスト画像を自動生成するアプローチとしてゲームで有名なUnreal engine4を使っています.自動運転の学習データをゲームエンジンで生成する試みはいくつかありましたが,この論文ではテキストの画像をゲームエンジンで生成するというのが新規性です.特徴として光源データなどを自在に操作できることが挙げられています.

[pdf]
Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection
こちらはOCRについての最新の研究です.サンプル画像はかなりインパクトのある結果を示しています.グラフを活用した推論を行うことでかなり堅牢になっているようです.

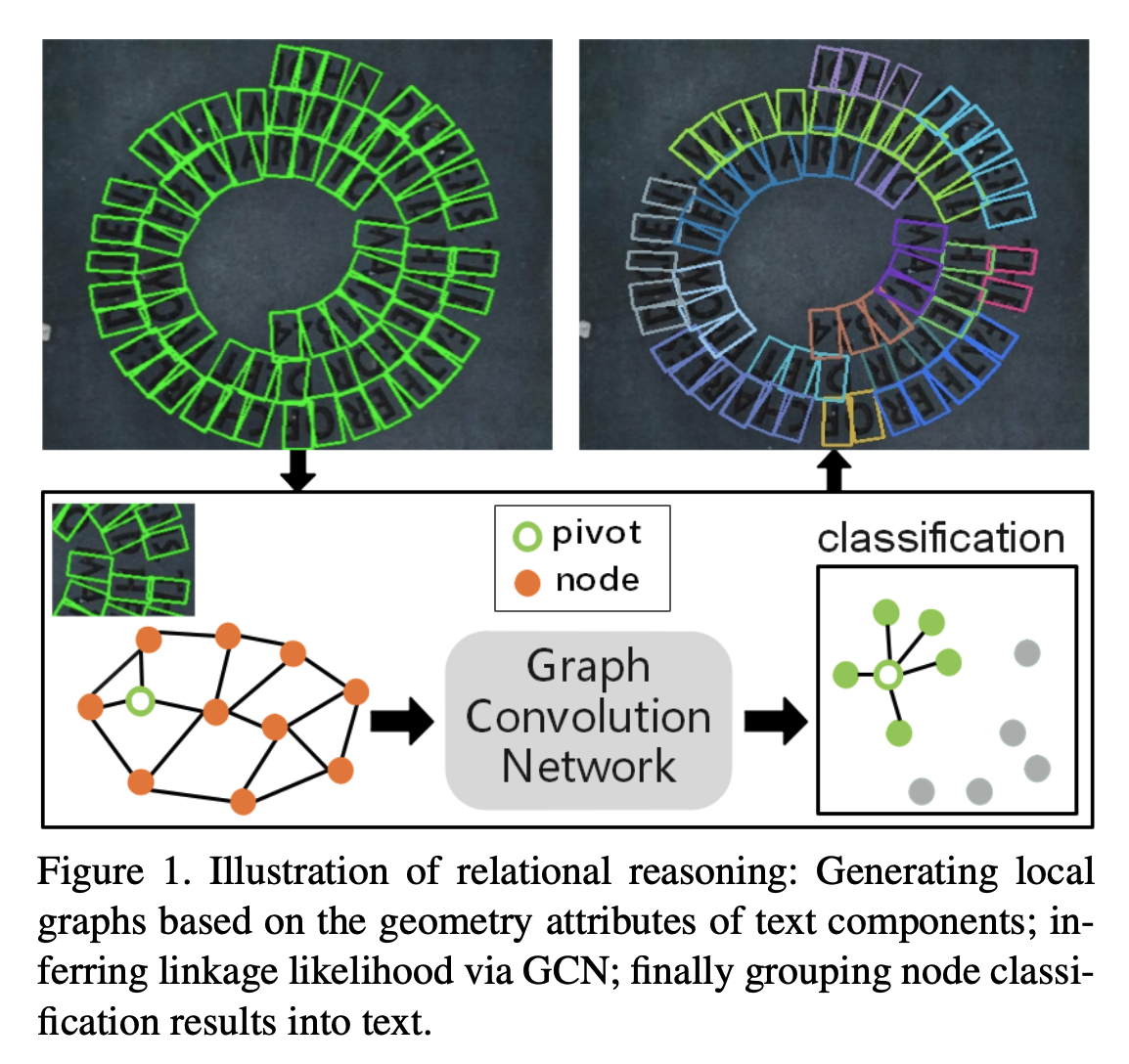
[pdf]
STEFANN: Scene Text Editor Using Font Adaptive Neural Network:2nd Time
こちらの研究はシーン画像のテキストを編集する手法を提案しています.この研究はデモ用のアプリを作りこんでいるのでぜひ動画をご覧ください.アプローチとしては既存のタスクを組み合わせたものになっています.具体的には,Segmentation,Inpainting,Style transferの合わせ技です.既存手法の組み合わせであったとしても面白い結果であればCVPRにも通せるチャンスがあり,やはりVisualのインパクトは大切であると認識しました.

SwapText: Image Based Texts Transfer in Scenes
こちらの研究もシーン画像のテキストを編集する手法を提案しています.目的はSTEFANNと同じなのですが,手法は明らかにこちらの方が賢いやり方になっています.具体的にはSegmentationが不要で,Inpainting,Style transferのみからテキストの編集が可能です.同じ結果が得られるのであればどちらでも良いように感じますが,実際に実装して使うならこちらの方が良さそうだなとも思います.今回はConcurrent workなので問題ないですが,このような手法を後発で提案する際には,どうやって有意性を主張するのが良いかというのは難しい問題になりそうです.

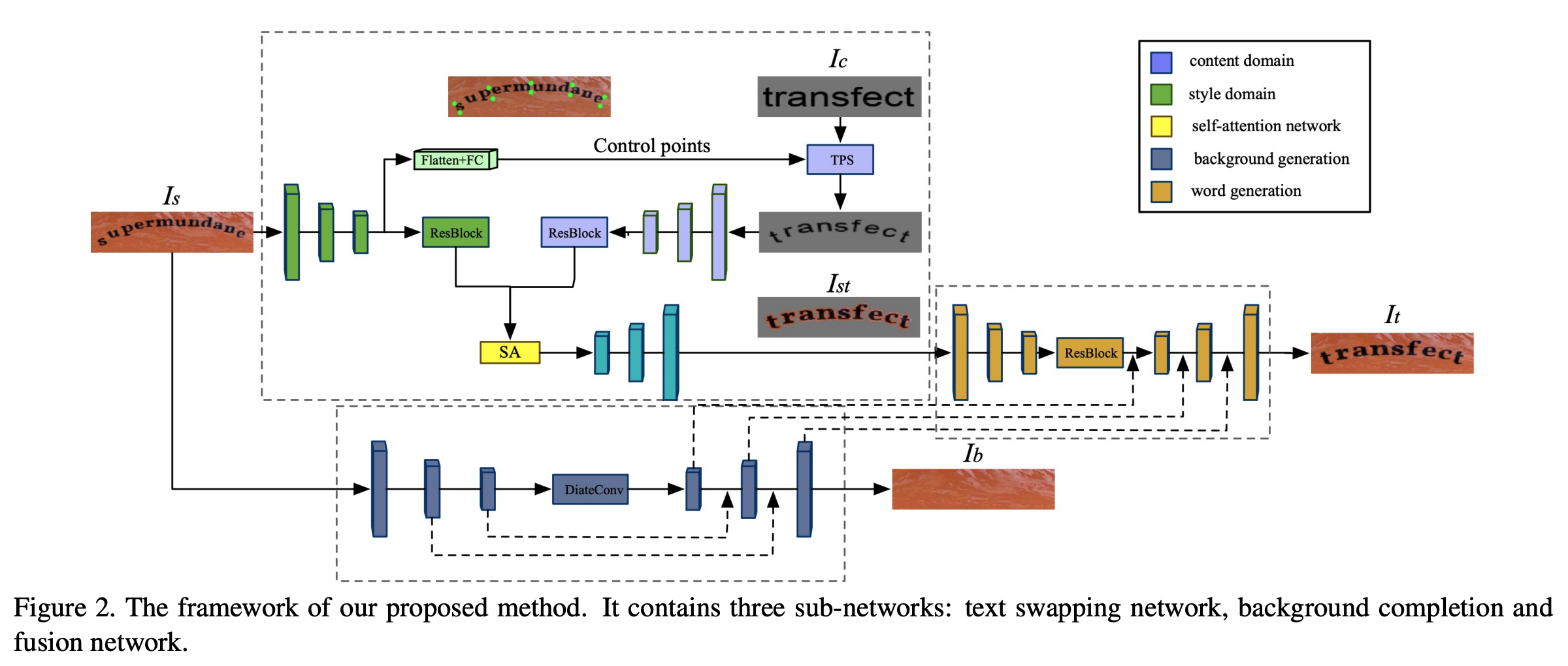
[pdf]
おわりに
近年のComputer visionの研究はめまぐるしい変遷を続けているように感じます.本記事では紹介しておりませんが,本会議では3D Visionについての研究がかなり勢いをもっていたように感じました.生成系もこれまでのトレンドとは変わってControllableなものが増えていっている印象です.最新の研究情勢を知る上でCVPR参加はとても有意義なものでした.
Author