Blog
SIGGRAPH2021 参加報告
AI Lab Graphics & Audioチームの武富です。8月9日から8月13日に開催されたコンピュータグラフィックス分野のトップ会議であるSIGGRAPH2021に参加してきました。SIGGRAPH2021は昨年と同様にオンラインの開催となりました。開催形式は、参加者は開催1週間前からプレゼンテーションの動画へのアクセスが可能となり事前に視聴し、本会議期間中はQ&Aがライブで行われるという方式でした。各セッションでは、座長の方が各発表の短い動画を再生した後にDiscord上で参加者から質問を受け付けるという形をとっていました。各発表のQ&Aが終了した後、発表者と座長でのパネルディスカッションがセッションの残りの時間を使って行われていました。多くの座長の方々は事前に各論文を読み込まれているようで、様々な質問をし各論文の利点や欠点、残された課題などを著者の方から聞き出されていて大変勉強になりました。SIGGRAPHはいわゆる研究論文であるTechnical Paperのセッション以外にもCourse、Electronic Theaterなど様々なセッションがあるのですが、この記事では武富が参加したCG in JapanというセッションとTechnical Paperで発表されていたアバター関連の研究を中心に簡単に紹介しようと思います。
CG in Japan
ACM SIGGRAPH VILLAGEというイベントの中でCG in Japanというセッションが開催されました。CG in Japanセッションでは、「日本のCG業界のいま」を紹介するという主旨で、東海大学の久保尋之先生、Mercariの山村亮介氏、筑波大学の落合陽一先生、武富がそれぞれの研究室や組織で取り組んでいるCG関連の技術について紹介を行いました。久保先生はプロジェクターカメラシステムを使った人体内部の計測、撮影領域のマスキング、インタフェースなどの取り組みを紹介されました。山村氏はpoimoと呼ばれる軽く持ち運びが便利な移動体の研究や柔らかな素材で構成されるセンサについての紹介を行われました。落合先生は御朱印を自動生成する取り組みについて紹介されました。また、武富はサイバーエージェントにおけるインターネット広告分野でのグラフィックス技術の利用というテーマで極予測AI人間、極予測LED、デジタルツインレーベルの事例を交えながらAILabの研究開発について紹介を行いました。質疑ではLED Displayを用いた撮影に関する質問が多く、このような撮影方法に対する関心の高さが伺えました。
研究紹介1: Portrait Editingに関する研究
Total Relighting: Learning to Relight Portraits for Background Replacement
Googleの研究グループの発表で著者の中にはライトステージを使った研究で有名なPaul Debevec氏(最近Netflixへ移籍)が含まれています。この研究でも、やはりライトステージを使って取得したデータセットを利用しています。
この研究では人物写真の背景を別の背景に入れ替えることを目的としており、背景入れ替えの際に背景画像のライティングを人物領域へも反映した上で合成するということを行っています。提案されている手法は、Mattingのためのalpha matteを生成するMatting Moduleと人物のリライティングを行うRelighting Moduleで構成されています。
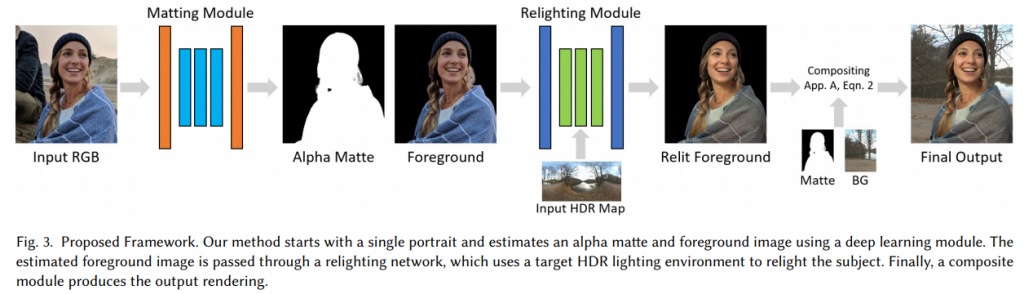
Matting Moduleに関しては、1つのエンコーダとtrimap、前景、alpha matteをそれぞれ生成するための3つのデコーダで構成されています。この構成に関しては、従来研究と同様ですが、ライトステージで取得したデータセットを用いることで人物写真に特化したネットワークになっています。Relighting ModuelではGeometry Moduleを用いて人物領域の法線を推定しています。その後、法線情報と入力画像からAlbedo Networkを用いてAlbedo画像を取得します。また、入れ替え対象となる背景のHDR MapについてはDiffuse convolutionとSpecular convolutionに分解され、Diffuse light mapとSpecular light mapの生成のために用いられます。この方法についてはリアルタイムのゲームエンジンなどで広く用いられているライティングの方法です。上記で得られたAlbedo画像、Diffuse light map、Specular light map、そして入力画像を用いてShading Netでリライティングされた人物画像を生成します。最終的に、生成されたリライティング画像と新たな背景画像をalpha matteを用いて合成することで高品質な背景画像の入れ替え結果を得ています。

PhotoApp: Photorealistic Appearance Editing of Head Portraits
マックスプランク研究所の研究で2Dの顔画像の顔の向きの変更、リライティングを可能にする手法です。この研究でも学習にライトステージを使って取得したデータセットを使っています。1枚の顔画像に対して、このような顔向きの変更とリライティングを同時に実現する手法はこれまでに実現されていなかったとのことです。
ライトステージで取得したデータセットを用いたリライティング手法ではライティングの変更は可能だが顔向きの変更は困難であるという問題があります。また、StyleGANを用いて顔向きの変更の変更を行う研究がありますが、こちらはリライティングが困難であるという問題があります。この研究では、これらの問題に対して、それぞれのアプローチを相補的に組み合わせることで顔向きの変更とリライティングの両方を実現しています。
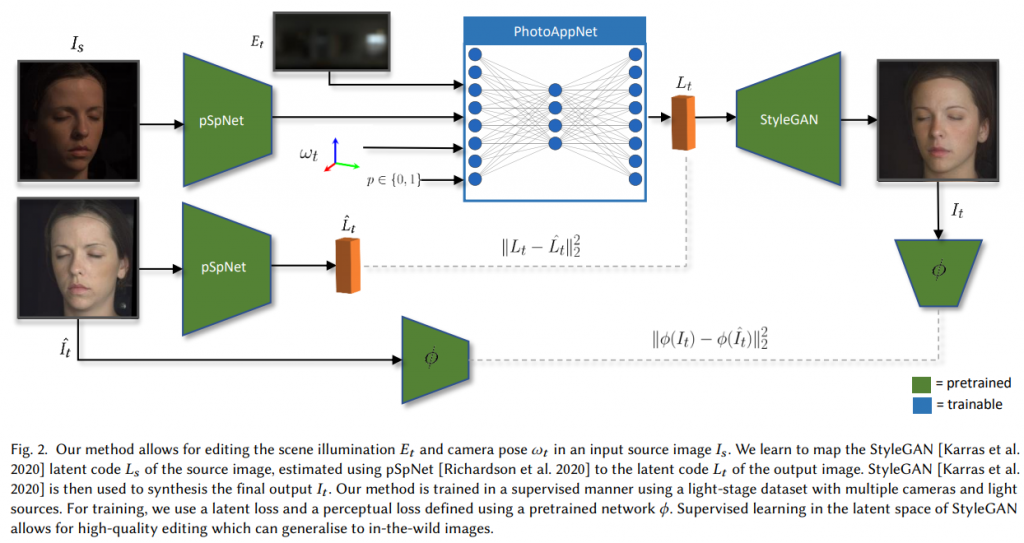
この研究ではpSpNetをベースにフレームワークが構築されています。入力画像はpSpNetを用いてエンコードされます。その後、取得されたLatent vectorと新たなライティング情報、顔向きの情報からStyleGANのデコーダへ入力するための新たなLatent vectorをPhotoAppNetを用いて取得します。学習にはライトステージで取得したデータを用いているため、対応する光源環境、顔向きに対するGround truthの画像があるため、生成された画像とGround truthの画像間でlossを取ることができるようになっています。また、Ground truthの画像をpSpNetのデコーダに入力して得られるLatent vectorをガイドとしてPhotoAppNetの出力を学習しています。このように、StyleGANベースの顔画像生成に対して、ライトステージのデータをうまく活用することで顔向きの変更とリライティングの両方を実現することが可能なネットワークを構築しています。
研究紹介2: Face Animationに関する研究
Real-time 3D Neural Facial Animation From Binocular Video
Facebook Researchの研究で、ステレオカメラ映像を使ってリアルタイムにアバターをアニメーションさせる手法です。発表動画では、以下のように著者と著者のアバターが左上に表示されており、リアルタイムで著者の表情がアバターの方へ反映されている様子が確認できるようになっていました。

この研究で用いられているアバターは多視点カメラを用いて均一な照明環境下で撮影されたデータをもとにDeep Appearance Modelを用いて作成されています。そのため、実環境では照明環境が異なり、生成されるアバターの表情の精度が低下してしまうという問題があります。そこで、この研究では、照明環境の差を補償するためにGain mapとBias mapを新たに導入することでトレーニング時とテスト時の照明環境の違いに対する頑健性を向上させています。
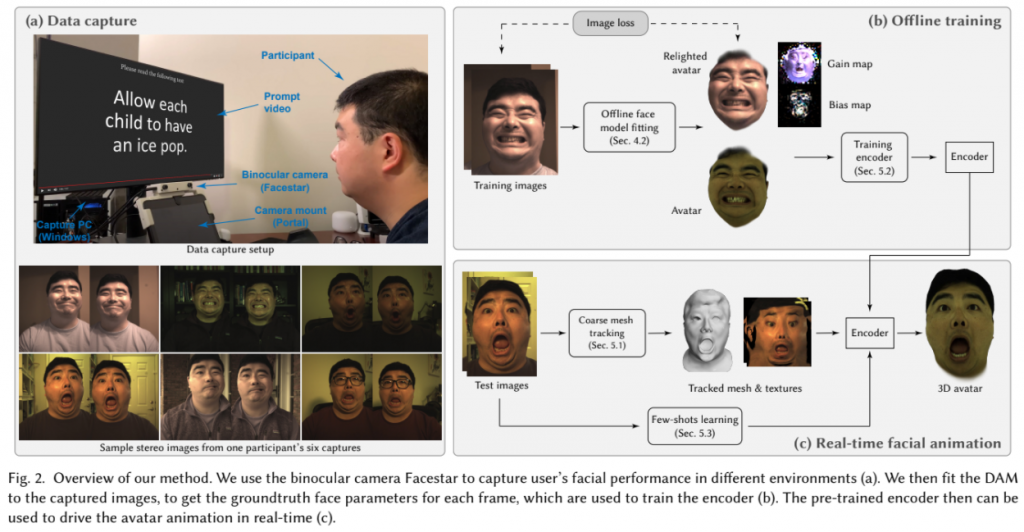
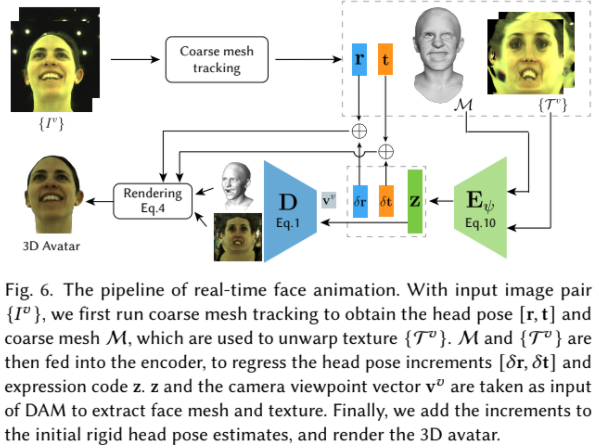
また、リアルタイムでのアニメーションを実現するために、この研究ではPCAに基づく顔モデルを利用した顔形状のトラッキングを行っています。これによって得られた形状、顔向き、テクスチャを初期値として最終的な顔形状とテクスチャを生成するようになっています。
Learning an Animatable Detailed 3D Face Model From In-the-wild Images
マックスプランク研究所の研究で、1枚の画像からアニメーション可能な3次元モデルを構築する手法(DECA)です。これまでに提案されている手法と異なり、この手法では顔のしわなどの詳細な形状を含めた形状復元およびアニメーションが可能になっています。これにより、個人の特徴的なしわなどの形状を再現した表情の転写が可能になります。
DECAのフレームワークは以下のようになっており、Albedoテクスチャを生成するネットワーク、大まかな顔形状を表現することができるFLAMEモデルのパラメータを推定するネットワーク、しわなどの詳細形状を表現するためのDisplacement mapを生成するためのネットワークで構成されています。DECAでは、AlbedoテクスチャとFLAMEモデルのジオメトリを使ってレンダリングした結果と入力画像間のLoss(下図青線部分)と詳細な形状情報を含めてレンダリングした結果と入力画像間のLoss(下図赤線部分)を利用することで学習を行います。
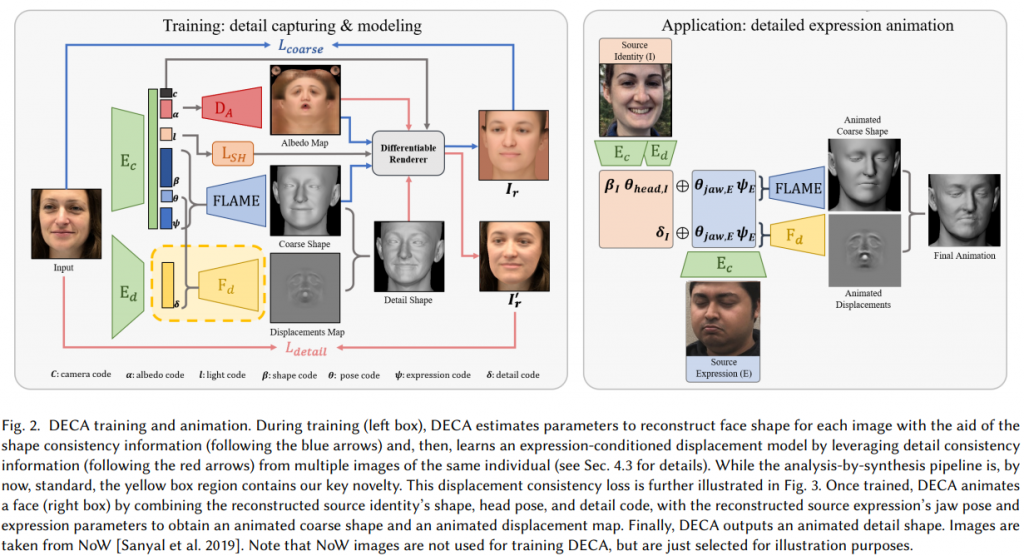
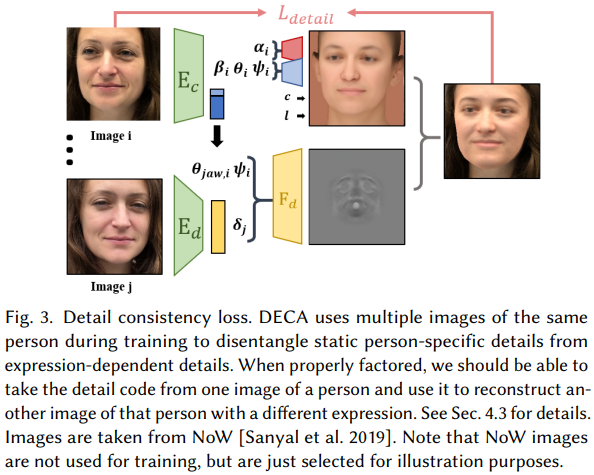
ここで、各個人の特徴的な詳細形状情報と表情による変化を分離するために、以下のようなConsistency lossを採用しています。このLossを用いることで、同一人物の異なる表情の画像を入力した場合において、エンコーダーから同一の詳細形状を表す特徴量が得られるように学習することができるようにしています。
DECAについては、コードおよび学習済みのモデルが公開されています。
Code:https://github.com/YadiraF/DECA
Deep Relightable Appearance Models for Animatable Faces
Facebook Researchの研究で、彼らが取り組んでいるCodec Avatar研究シリーズになります。これまでのCodec Avatarではアバターをリライティングすることができなかった問題をこの研究では解決しています。これまでに、動的な人物のリライティング研究や静的な人物のリライティングおよび視点に依存したライティングの実現の研究は行われていますが、この研究ではさらにアニメーションを可能にしています。
この手法ではExpression Code、Viewpoint、Lightingの情報から対応する形状情報およびテクスチャをVariational auto-encoderを用いて生成しています。利用されているモデルでは、形状情報はExpression Codeのみから生成され、テクスチャはExpression Code、Viewpoint、Lightingの情報を用いて生成されるようになっていることが分かります。
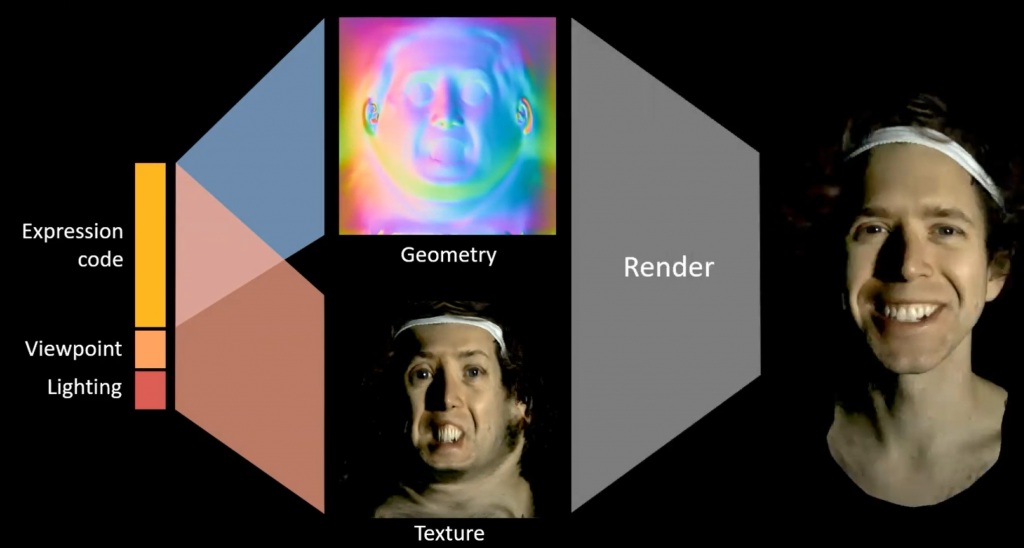
また、この研究でもライトステージを使って学習用のデータを取得しているのですが、OLAT (One-Light-at-A-Time)による計測は時間がかかるため動的な人物のライティング情報の取得には適さないという問題があります。そこで、この研究ではライティングを時分割多重することによって90 fpsでのライトステージを使ったデータ取得を可能としてます。
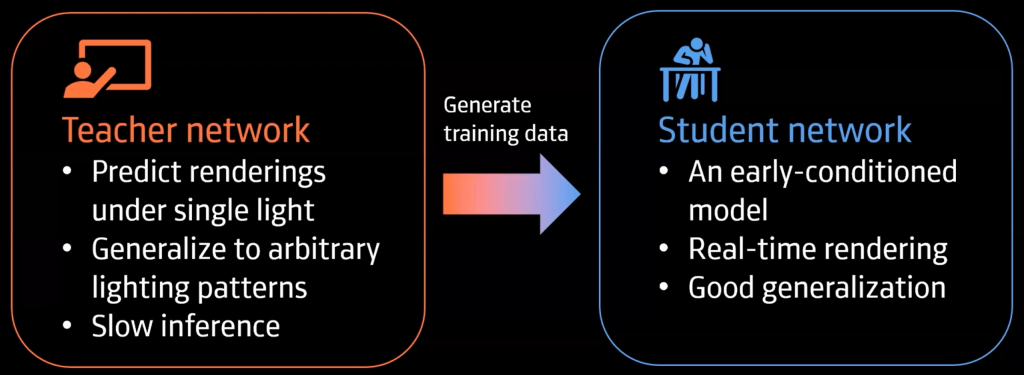
ネットワークについてですが、Condition情報をネットワークの初期に導入する方法(Early-conditioned)はリアルタイムな処理を行うのには向いているのですが、オーバーフィッティングしやすいという課題があり、ネットワークの最後にCondition情報を導入する場合(Late-conditioned)は汎化しやすいという利点がある一方で処理時間がかかりリアルタイム処理には適さないとう問題があります。この問題に対して、この研究ではTeacher/Student Frameworkを利用し、Teacher Networkを用いて学習データを大量に生成しStudent Networkを学習することを行っています。これにより、リアルタイムかつ汎化性能の高いネットワークの構築を実現しています。
研究紹介3: Neural Renderingに関する研究
ACORN: Adaptive Coordinate Networks for Neural Scene Representation
スタンフォード大学のグループの研究で、座標を入力としてOccupancy field、Signed distance fieldなどの信号を出力するNeural Implicit Representaionを大規模なシーンでも利用できるようにするための研究です。この研究では、特徴量から信号を出力するExplicitな表現の計算効率の良さとメモリ効率の良いImplicitな表現のハイブリッドな表現を提案しています。
ACORNは、Global coordinate encoderとLocal coordinate encoderで構成されており、Global coordinate encoderではGlobal座標を入力とし特徴量を出力するようになっており、Local coordinate encoderでは局所座標と特徴量を入力とし信号を出力するようになっています。
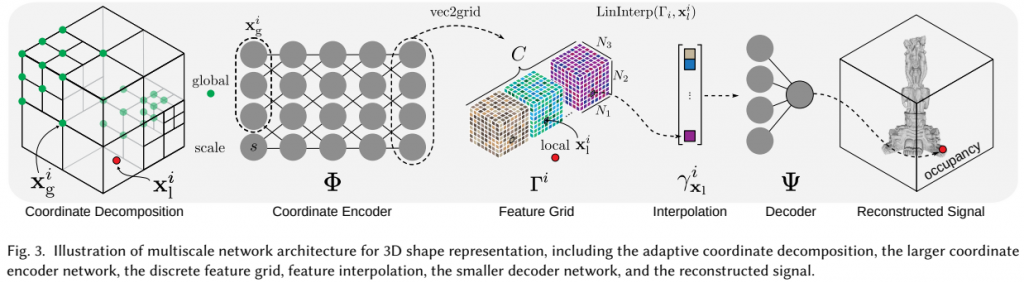
ACORNでは、Training時の誤差に応じて誤差が大きくより詳細な分析が必要な場所は動的により細かく空間を分割するようになっています。分割には2次元の場合はQuadtreeを用い、3次元の場合はOctreeを用いています。座標情報とスケール情報はCoordinate Encoderに入力され、Coordinate Encoderの出力ベクトルからFeature Gridが生成されます。その後、このFeature Gridを補間することで特徴量を生成、Decoderを用いて信号を復元するという構成になっています。ACORNを用いることで、以下のようなGigapixel画像に対するフィッティングタスクにおいても詳細な情報を復元できていることが確認できます。

ACORNについては、以下にコードが公開されています。
Code: https://github.com/computational-imaging/ACORN
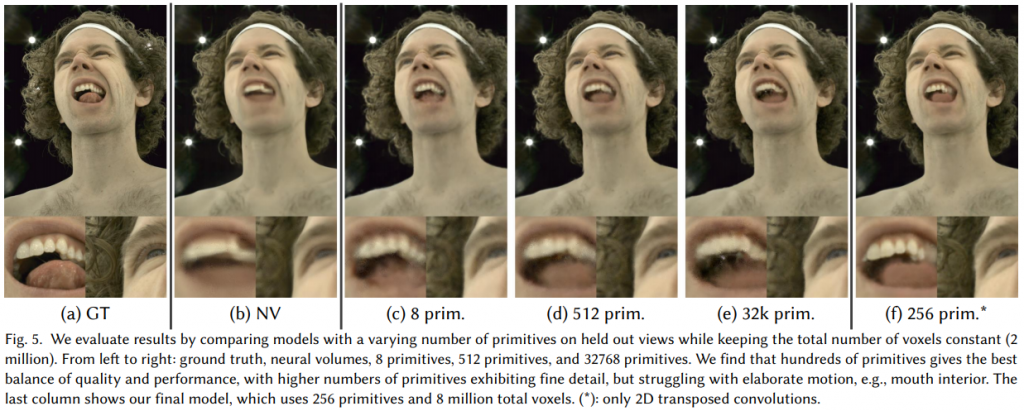
Mixture of Volumetric Primitives for Efficient Neural Rendering
Facebook Researchの研究で、Deep Relightable Appearance Models for Animatable Facesなどと同様にCodec Avatar関連の研究になっています。これまでのCodec Avatarで利用されていたメッシュ表現をベースとしたDeep Appearance Modelでは髪の毛などの複雑な形状を高品質に再現することが難しいという問題があります。一方で、Volumetricな表現は髪の毛などの複雑な形状に対しても高品質に再現することができるという利点があります。ただし、Volumetricな表現はメモリを多く必要とするため解像度を上げることが難しいという問題があります。そこで、この研究ではメッシュ表現とVolumetric表現のハイブリッドな手法を提案しています。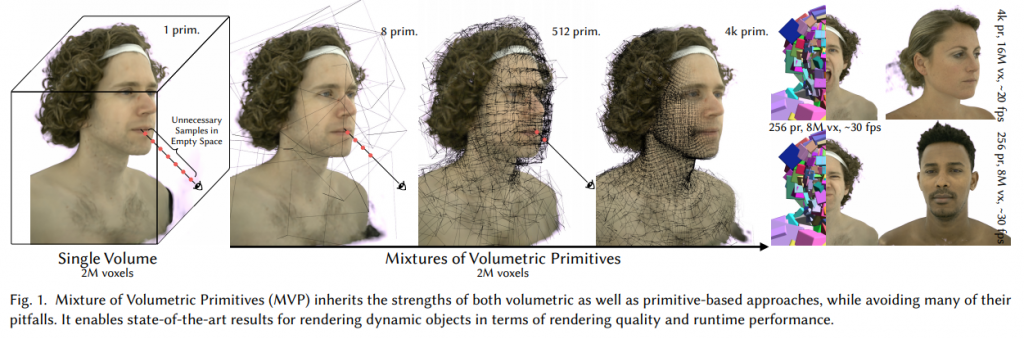
基本的なアイデアとして、各メッシュに対してUVのテクスチャマップを対応付けるのではなく、小さなVolumeを割り当てるというアプローチをとっています。これによりメッシュ表現、Volumetric表現の両社の利点を生かし高品質な映像の生成を可能としています。
まとめ
本記事では、アバター関連の研究を中心にいくつかの研究を紹介しました。この分野では、Facebook、Google、マックスプランク研究所が多くの発表をしており、多くの研究でライトステージや高性能な多視点カメラシステムがデータ取得に用いられておりある程度の資金力が研究を実施するために必要な印象でした。中でも、Facebook Researchについては既に数百人分のライトステージデータを取得済みとのことで、データの質、量ともにこの分野で現在トップなのではないかと思います。また、今回の記事では取り上げることができませんでしたが、この他にも様々な研究発表がありました。特に、Differentiable Renderingに関しては2つのセッションがあり、注目度が高いことが伺えました。
Author