Blog
ドメイン適応とは何か?
なぜあなたの深層学習システムは本番で期待した性能を出せないのか
キーワード:ドメイン適応, 転移学習, out-of-distribution generalization, コンピュータビジョン, 機械学習
Summary:多くの機械学習システムは、学習データと運用時に使用するデータが同じ分布に従うことを前提としている。 しかし、実際のデータ分布は、トレーニング時とテスト時で異なることは往々にしてあり、そのような場合システムは開発時では見られなかった精度低下に悩まされることになる。 一つのデータセットから学習した知識を異なるドメインに属する別のデータセットに転移するために様々な手法が提案されているが、これらのドメイン間の「ギャップ」によっては、適切な generalization を実現することは困難である。 この記事では、ドメイン適応(DA)手法の概要と、その必要性、および DA のタイプや DA を適用できるさまざまなシナリオを紹介する。 DA の理念に慣れた上、読者がニーズに合わせた適切な手法(マルチモーダル DA など)を調査できるようになるための出発点として役立てていただきたい。
1. はじめに
機械学習システムは、すでに世界中で開発され、社会に導入されている。 例えば、医療診断を支援するためのシステムやスマートデバイスでの生体認証用の顔認識システム、もちろんサイバーエージェントで開発された製品も含まれる。 こうしたシステムの大部分は、蓄積された訓練データを用いて学習されており、運用時に扱うデータは訓練データと同じ確率分布に従うと想定されている。 しかし、訓練データとテストデータが同じ確率分布に従うという想定は必ずしも成立するものではなく、そのような場合にシステムは想定外のパフォーマンス低下にみまわれることになる。 この現象は、out-of-distribution(OOD)generalization [Wang 21] として知られており、現代の機械学習(ML)で取り組むべき主要な問題の一つとして、近年大きな注目を集めている。
OOD generalization 問題の原因は、実際のデータ分布を反映した十分な訓練データの収集が現実的には非常に困難であることにある。 深層学習手法は高い精度を実現できる可能性があるが、一般に大量の訓練データを要求する。このような大規模なデータセットを構築するのに、研究者はさまざまな異種ソースからデータを集める。そのため、機械学習システムは、異なる確率分布を組み合わせたデータセット(図1)で学習する。
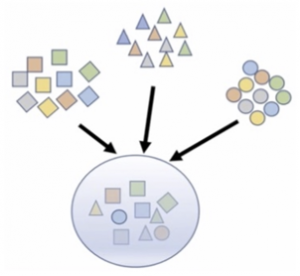
図 1 一般的なデータセットの構築([Wang 21] より引用)。
1.1 Out-of-distribution generalization
この記事で扱う技術は、広範なモダリティ(画像、オーディオ、ビデオ、テキストなど)に適用できるが、基本的には、コンピュータビジョン分野でのドメイン適応を紹介する。
一般的な(教師あり)深層学習パイプラインには、訓練セットのサンプル画像 \(S\)、そのラベル \(Y\)、学習可能なモデル、および評価用のテストセットのサンプル画像 \(T\) がある。基本的なモデルアーキテクチャは、特徴抽出器 \(f\)(例えば、畳み込みニューラルネットワーク、CNN)と分類器 \(h\)(例えば、全結合層、FC)で構成される。画像が特徴抽出器に入力されると、その特徴はベクトル形式で抽出される。 この特徴ベクトルは \(d\) 次元空間上の点で表すことができる。訓練セットの画像は、確率分布 \(D_S\) に従って特徴空間 \(X\) に分布する。モデルを学習するとき、この特徴空間は、\(X\) からのサンプルと \(Y\) からのラベルを関連付ける仮説 \(h:X\rightarrow Y\) が最適化されるように適合される。
通常の教師あり学習(ドメイン適応なし)は、\(S\) と \(T\) に属するサンプルが独立同分布(IID)である、つまり同じ確率分布(\(D=D_S=D_T\))に従うため、訓練とテストデータにおける精度が大きく変わらないと想定している。しかし、この想定は実態と乖離している場合が多い(図2)。背景が芝生の犬画像ばかりが訓練データとして与えられる場合、訓練データにおいては dog と grass の特徴が dog のラベルと強い相関を持つ。しかしこのような相関関係が、テストデータでは見られないということがあり得る。それは、実際の dog 画像はさまざまな見えや背景を持つためである。 したがって、芝生のない犬の画像は、訓練データと似たものと比べると精度が低下する。
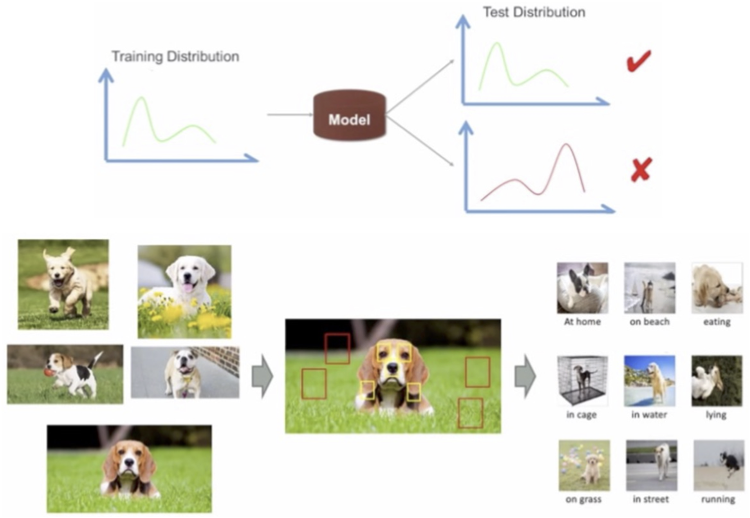
図 2 Out-of-distribution generalization([Wang 21] より引用)。
Out-of-distribution (OOD) 問題の解消には、訓練データから学習した知識を活用し、他の分布の異なるデータセットに generalization できるかということが重要となる。
1.2 転移学習
転移学習とは、ある問題設定のもと学習された知識の保存と、別の関連する問題設定への応用を指す [Pan 09](図3)。深層学習(特にCNN)の表現学習の有効性が認識されるにつれ、転移学習は大きな注目を集めた。転移学習を適用する方法はいくつかあるが、最も広く用いられている方法は、さまざまな画像を含む大規模なデータセットを使用してモデル(この場合は特徴抽出器)を事前学習させる方法である。大規模なデータセットを用いることで、汎用的な特徴表現が学習されることを期待している。
図 3 2つの機械学習モデル間での転移学習。
最近の自己教師学習(SSL)手法(例:[Chen 20, He 20])は、転移学習 [Noroozi 18] の方法として考えることができる。 目的のタスク(分類、セグメンテーションなど)でモデルを教師あり事前学習するのではなく、SSL の目的は、教師なしで学習可能な代替タスク(画像ぬり絵など)を大規模データセットで学習し、得られた知識を目的のデータとタスクに転移することである。SSL 手法により、ネットワークのパラメータを効果的に(ランダムよりもはるかに良く)初期化でき、小さなデータセットを用いた学習でも高い性能が期待できる。ただし、SSL は事前学習のデータと実際の訓練データの確率分布の差を考慮しない。さらに、SSL では、訓練とテストデータの間における見た目や視点の変化に対する汎化能力に大きな制限があることが報告されている [Purushwalkam 20]。
2. ドメイン適応
大規模な訓練データセット(例:東京の街路の画像)で教師あり学習されたディープネットワークが与えられたとする。ここで異なるデータセット(例:マドリードの街路の画像)でもシステムの性能を確保したいケースを考える。そのための方法として、それぞれのデータセットから抽出される特徴を類似させることが考えられる。 ドメイン適応(DA)は、「source」ドメインと「target」ドメインのサンプル間のドメイン「shift」を軽減するという問題に取り組む技術である。
- ドメイン shift:訓練データセットとテスト時に与えられるデータセットの間のデータ分布の変化。
- Source ドメイン:モデルの訓練に使用されるデータセット。Source データは、訓練セットを構築するために特別に用意されているため、普段はデータが豊富で適切にラベル付けされている。
- Target ドメイン:テスト時にモデルを評価するために使用されるデータセットである。 Target データは、小規模でラベル付けもされていないものとされる。
図 4 は単純な DA シナリオを示している。 Source ドメインは、イラスト風の画像 \(S\) であり、その特徴を \(X_S\) とする。 Target ドメインは、写実的な画像 \(T\) からなり、その特徴は \(X_T\) とする。理想的には、両方のドメインの同じクラスに属する画像の分布は重なっていることが望ましい、\(D_S=D_T\)。しかし、見た目の違いにより、「ドメインギャップ」が発生する(図 4 内の緑色の線)。 そこで、source 画像と target 画像の分布を合わせるために、DA は可能な限り、source 画像の特徴に近くなるように target 画像の特徴表現を学習する。
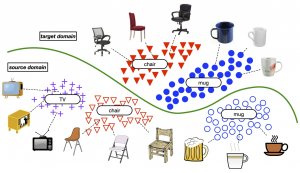
図 4 ドメイン適応のシナリオの概要([Cao 18] より引用)。
Source ドメインと target ドメインの定義は タスク依存 であることに注意されたい。つまりドメインは、システムがトレーニングされたタスクとその精度に関連している。たとえば、広告の製品の識別 というタスクにおいて、A社のバナー画像の訓練データセットとB社のバナー画像のテストデータセットが与えられたとする。製品クラスの識別に有効な特徴(例:色、テキストセマンティクス)は、メディアプラットフォーム(A社かB社)によって大きく変わることはないと考えられる。したがって、訓練データとテストデータは同じ分布に従い、source と target の分離はないとすることはある程度妥当な想定である。しかし、タスクが 売上高の予測 の場合、メディアプラットフォームによって売上高の振る舞いは大きく変わる。したがって、A社の画像(source)のみで学習されたモデルの場合、B社の画像(target)の特徴表現の分布は source のと異なるため、予測エラーが発生し、その結果、精度が低下する。(これは単なる例であり、実際のユースケースは必ずしもこのような結果になるとは限らない。)
まとめると、教師あり学習と DA の主な違いは、後者ではデータが訓練時と評価時で2つの異なる(ただし関連する)分布、\(D_S\) と \(D_T\) から生じていると想定する点にある。このような前提のもと、target ドメイン \(D_T\) でのエラー発生を抑制するために、それぞれのドメインのラベル付きとラベル無しのサンプルを活用して、分類器 h を学習することがDAの目的である。
次のセクションでは、様々な DA シナリオとその種類をまとめる。さらに、より具体的な例として、付録 A に一般的に使用される DA データセットの詳細を記載する。
2.1 ドメイン適応の種類
ドメイン適応(DA)の手法は target データ内のラベルの有無によって、下記のように分類できる:
- 教師なし DA [Ganin 15]:Source サンプルはラベルが付与されているが、target サンプルのラベルは手に入らないものとされる。評価セットにはラベル付けされていない source サンプルも含まれる場合がある。
- 半教師あり DA [Saito 19]:上記の教師なし DA シナリオに、一部ラベル付けされた小さな target サンプルのセットも含まれている。
- 教師あり DA [Motiian 17]:サンプル(source と target)が全てラベル付けされている。
この中で、教師なし DA(UDA)の設定は最も現実的な問題設定である。それは、テストの段階まで target データへのアクセスが不可能という前提だからである。ただし、target 分布の一部が source データに含まれているケースもある。 たとえば、大規模な顔認識データセットの中に少数民族の顔データがわずかしか含まれていない場合、テスト時に少数派の画像だけ精度が低下する可能性がある。こうしたケースは、半教師あり DA を適用することで、対応することができる。Target データが全てラベル付けされていても、その量がディープネットワークを訓練するのに十分でない場合には、教師あり DA が使用される。
ラベルの付け方の他にも、DA アルゴリズム自体も主に3つのアプローチに分けられる:divergence、敵対的学習、および再構築ベースである。
- Divergence ベース DA [Sun 16, Yan 17, Kang 19]:Source と target データの分布間の divergence 基準を最小化することにより、ドメイン不変の特徴表現を学習できる。 この divergence は、前述の「ドメインシフト」も指し、多くの手法は divergence 指標として、分布距離の一般的な指標である KL divergence を用いる(詳細は、付録 B に記載されている)。こうしたドメイン不変の特徴表現が存在するためには、source と target が何らかの形で関連していることが前提となる。
- 敵対的学習ベース DA [Liu 16, Tzeng 17, Pei 18]:Discriminator のモジュールが訓練パイプラインに導入され、あるサンプルが source ドメインと target ドメインのどちらに属するか識別できるように学習される。一方、source ドメイン、および target ドメインの特徴表現は dicriminator に対して敵対的に学習される。適応が進むほど、discriminator の精度が悪くなる。全体としては、敵対的ロス関数とタスクロスを用いて、target 特徴の抽出器を学習する。
- 再構築ベース DA [Ghifary 16, Yoo 16, Hoffman 18]:Image-to-image translation の理念に基づいて、再構築ベース DA は補助的な再構築タスクを学習することで、各ドメインで共有される特徴表現を構築する。例えば、target 画像から source 画像を生成する、あるいはその逆変換をする、encoder-decoder のネットワークを学習する。または source → target に画像を変換した後 target → source にもと画像を再構築したりするような学習方法が使用されている。
Target データのラベル有無や DA のアルゴリズム以外で DA を分類する軸を紹介しておく。この記事ではこれまで、共通のクラスを持つ single-source と single-target ドメインの問題設定についてのみ議論した。しかし、より現実的な設定では、複数の source/target ドメインやそれぞれの異なるクラス数が存在するケースも考えられる。表 1は、UDA をベースケースとして、さまざまな DA のシナリオやその種類をまとめる。図 5 は 表 1 に記載されている DA 種類を描写している。各色は一つのドメインを表し、各形状はそのドメインに含まれる一つのクラスを表している。
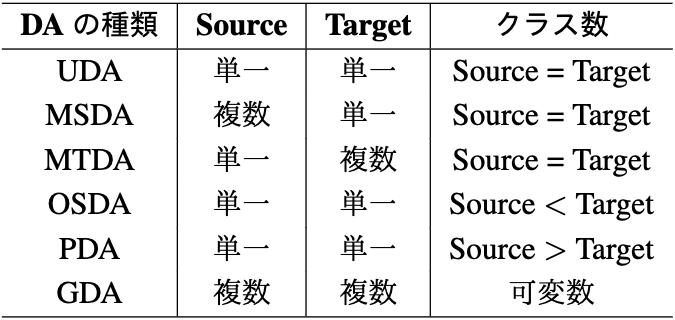
表 1 ドメインとクラスの数によるドメイン適応の種類。
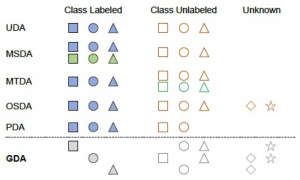
図 5 ドメインとクラスの数によるドメイン適応の種類([Mitsuzumi 21] より引用)。
教師なしドメイン適応(UDA)は、source と target それぞれが単一のドメインからなり、クラスを共有していると考える。 Source データに複数のドメインが含まれている場合、問題設定は multi-source ドメイン適応(MSDA)に当てはまる [Li 17, Peng 19](付録の図 A.3);同様に、multi-target ドメイン適応(MTDA) [Gholami 20] には、複数のtarget ドメインが含まれる。
さらに、source データと target データに含まれるサンプルのクラスが一致しないシナリオも考えられる。たとえば、ブランド A(source)の製品を識別するのに学習されたモデルを、別のブランド B(target)の製品でテストした場合、製品の種類(クラス)がわずかに異なる可能性がある。Target データが元々 source データに存在しないクラスを含むシナリオは、open-set ドメイン適応(OSDA)[Saito 18] の問題設定である。逆に、partial ドメイン適応(PDA)[Cao 18] の問題設定では、source データが target データに存在しないクラスを含むと見なす(たとえば、図 4 の “TV” クラス)。
最後に、generalized ドメイン適応(GDA)[Mitsuzumi 21] が、より一般的で制約の少ないシナリオとして最近提案された。この問題設定では、source データと target データに複数のドメインが含まれるが、ドメインのラベルは与えられない。つまり、データセットのサンプルが異なるドメインに属していると想定するが、どのドメインに属しているかは未知とする。例えば、複数の期間で得られたデータを混合して構築された異種データセットを使用するケースは GDA に対応している(図 1)。さらに、GDA 設定では、ドメインごとに必ずしも同じクラスが含まれているとは限らず、target データに未知のクラスが存在する場合もある(図 5)。
ドメイン適応の分野における研究の傾向は、制約のある単純な設定から、より困難な問題設定へ移行し、記事の最初で紹介されている OOD generalization のようなシナリオに近づいている。 この傾向は、深層学習システムを訓練およびテストをするときに異種データが引き起こす問題が解決されるまで続くと思われる。
結論と今後の課題
この記事は out-of-distribution generalization の問題を紹介し、その解決方法としてドメイン適応の概念を紹介した。ドメイン適応(DA)は、訓練(ラベル付きの source)およびテスト(ラベルなしの target)データが異なる分布に従うサンプルで構成されている場合に(ドメイン shift)、精度の低下を防ぐための手段である。
ドメインshiftに取り組むために、様々な DA 手法と問題設定が提案されており、この記事はそれぞれを簡単にまとめた。
最新の設定である generalized ドメイン適応では source と target データに含まれるドメイン数とクラスに関する制約を極力撤廃している。これは、深層学習システムを訓練するためにさまざまなデータソースから大規模なデータを収集する現実的なシナリオに当てはまる。
実は、社会にすでに導入されている多くのシステムは、データがサンプリングされるドメインの存在を無視して、雑多なデータセットで訓練されているため、精度の低下が発生している可能性が高い。DA の重要性がそこにある。
次の機会では、DA アルゴリズムとその数学的な含意のより深い分析を提供したい。 また、今後はマルチモーダルなドメイン適応手法などについてもまとめていく。
*付録*
A. ドメイン適応のデータセット
ドメイン適応の研究者は、実験のベンチマークを作成するために、画像分類やセマンティックセグメンテーションなどのタスクでさまざまなドメインからデータを収集してきた。最も代表的なデータセットは下記の通りである:
- Digits [Xu 18]:4つのドメイン(手書き、typed など)から、0 から 9 までの数字画像が含まれている(図 A.1)。DAの最も基本的なデータセットである。

図 A.1 Digits データセット([Xu 18] より引用)。
- Office [Saenko 10]:3つの異なるドメイン(雑然とした背景やきれいな背景など)で撮影されたオブジェクトの写真が含まれている(図 A.2)。Digits と同じくらい基本的だが、Office のほうが困難である。

図 A.2 Office データセット([Saenko 10] より引用)。
- PACS [Li 17]:sketch、cartoon、painting、photo の4つのスタイル(ドメイン)で描かれた7つのクラスの動物や人間の画像が含まれている(図 A.3)。

図 A.3 PACS データセット([Li 17] より引用)。
- Cityscapes-GTA5 [Hoffman 18]:2つのドメインから撮られた一人称運転のビデオが含まれている;実車のカメラ、およびゲームGTA5でレンダリングされたコンピューターグラフィックスの画像(図 A.4)。 合成画像で訓練されたセマンティックセグメンテーション手法が実際の運転のビデオにどこまで汎化できるかを研究するために使用されている。 このデータセットで評価された DA 手法の多くは、再構成ベースである。

図 A.4 Cityscapes-GTA5 データセット([Hoffman 18] より引用)。
上記のデータセットにはさまざまなドメインとクラスが含まれているので、表 1 の問題設定(例:MSDA)を再現するために使用できる。
B. KL divergence
Kullback-Leibler(KL)divergenceは2つの確率分布がどの程度異なるかを測定する:
$$D_{KL}(D_S||D_T)=\sum_{x \in X}D_S(x)log(\frac{D_S(x)}{D_T(x)})$$
\(D_S(x)\) は source 分布からのサンプルであり、\(D_T(x)\) は \(D_S(x)\) と一致させたい target 分布からのサンプルである。KL divergence は、\(0\)(分布が完全に一致する)から無限までの値がとれる。値が小さいほど、マッチングができている。KL divergence の背後にある直観は、\(D_S\) から生じるイベントの確率が大きいとき、\(D_T\) から同じイベントが生じる確率が小さくなっている場合、大きな divergence があるということである。一方、 \(D_S\) からの確率が小さく、\(D_T\) からの確率が大きい場合、その divergence は、前述の場合ほど大きくない。
*参考文献*
Author