Blog
レイアウト生成の研究紹介
はじめに
AI Labの井上です.AI Labでは広告表現,特にバナー画像の自動生成技術の開発に取り組んでいます.バナー画像は一枚のラスタ画像として最終的には表現されますが,生成過程ではベクタ形式のデータを取り扱い,画像・テキスト・装飾など多種多様なレイヤーを適切に配置することを考えなければなりません.今回はその基礎をなすレイアウト生成について,ニューラルネットワークを用いた最新の研究を紹介していきたいと思います.
レイアウト生成の問題設定とその代表的な手法
ここから紹介する研究の大半で生成するレイアウトのデータ形式を記しておきます.表記は LayoutGAN [1] に準拠します.レイアウトとは \(N\) 個の要素から構成された集合 \( \{(p_{1}, \theta_{1}), \ldots, (p_{N}, \theta_{N})\}\) と表現されます.各要素は位置情報を表す \( \theta \) とカテゴリ情報を表す \( p \) からなります. \( p \) はデータのドメインに依存します.例えばPubLayNet [2] という論文データセットのレイアウトであれば「文章」「表」「図」などがカテゴリとして挙げられます.
生成の手法は大きく分けて conditional / unconditional generation の2つに分けられます.前者では要素数・メタデータ・要素間の関係性などの条件を入力に,その条件を満たしたレイアウトを生成します.後者ではそのような制約はありません.
Unconditional generation
レイアウトは本質的には集合 (set) ですが,適当に順序をつけて列 (sequence) とみなすことで,自然言語処理分野で目まぐるしく発展している文章生成技術を (ほぼ) そのまま用いることが出来ます.特に,Transformerベースの生成が非常に良く用いられています.
LayoutTransformer [3] では,Transformerを用いた自己回帰型モデルを用いてレイアウトの各要素を一つづつ順番に生成します.元々のテキスト生成モデルではカテゴリ変数のシーケンス生成を対象にしているので,位置情報を離散化することでレイアウト生成に応用しています.生成順は固定(例: raster scan order)ですが,良いクオリティの生成が実現されています.論文では,デザイン系のデータだけでなく,自然画像中のオブジェクト配置や3D物体生成等でも全く同じ原理で生成できる事を示しています.
LayoutTransformerのアーキテクチャ(図は元論文から引用)
Variational Transformer [4] では,生成モデルの一つである Variational AutoEncoder を,Transformerを使うことでレイアウト生成に応用しています.Jiang et al., [5] では,レイアウトが多くの場合は木構造で元々表現されていた(例:webページのDOM tree)ことに注目して,下図に示すようにまず大まかな領域レイアウトを生成したあとで各領域の要素配置パターンを生成する,二段階の手法が用いられています.
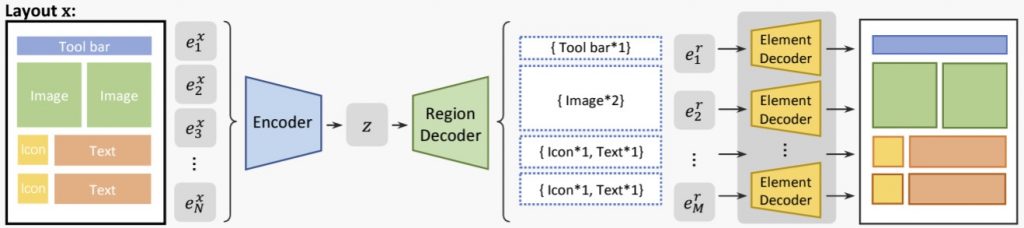
Jiang et al., [5] のアーキテクチャ(図は元論文から引用)
Conditional generation
Unconditional generation は大まかなデータ分布を理解するのには役立ちますが,ユーザが所望するようなレイアウトの実現にはそのまま使えません.conditional generation では様々な制約を入力としてレイアウトの生成を行います.
最初に行われたのは,カテゴリ情報をネットワークの入力に与える生成です.
LayoutGAN [1]では,推定されたレイアウトの良さをGenerative Adversarial Network (GAN) によって判別することで,ニューラルネットワークを用いたレイアウトのconditional generationを初めて実現しました.
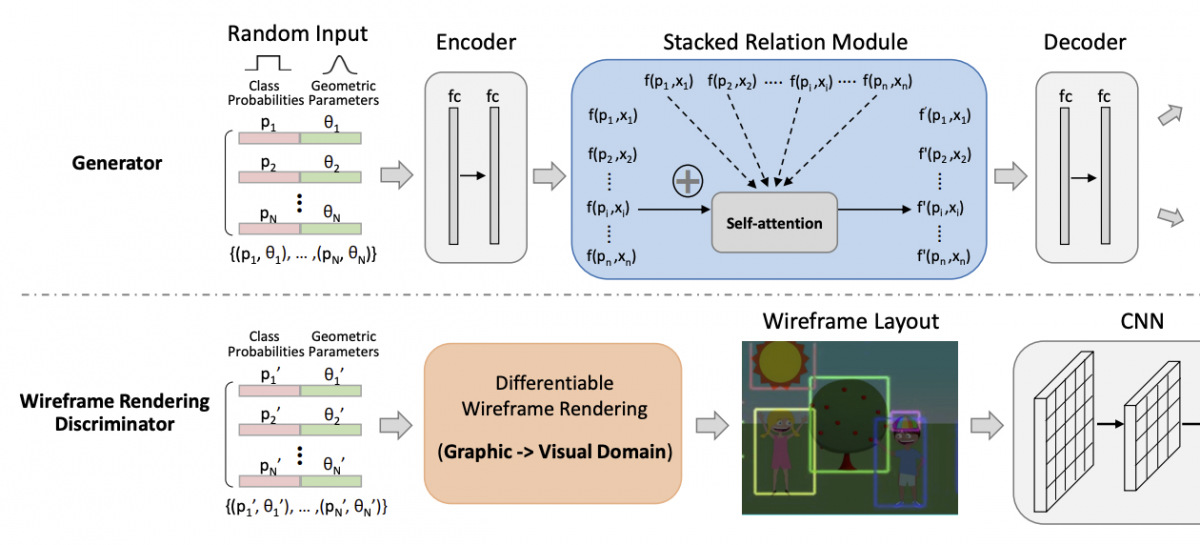
LayoutGANのアーキテクチャ(図は元論文からの引用)
カテゴリ情報以上の情報を入力に追加することでよりユーザの意図により忠実な生成を行う研究も出てきています.
NDN [6] では,要素やキャンバス全体の位置やサイズの関係を明示的に入力として取り込んだ上での生成に取り組んでいます.Graph Neural Networkによって要素間で情報をやり取り,refinement moduleで人間の目に違和感を生じさせがちなoverlapやalignmentといった特徴を補正,などといった工夫が多く取り込まれています.
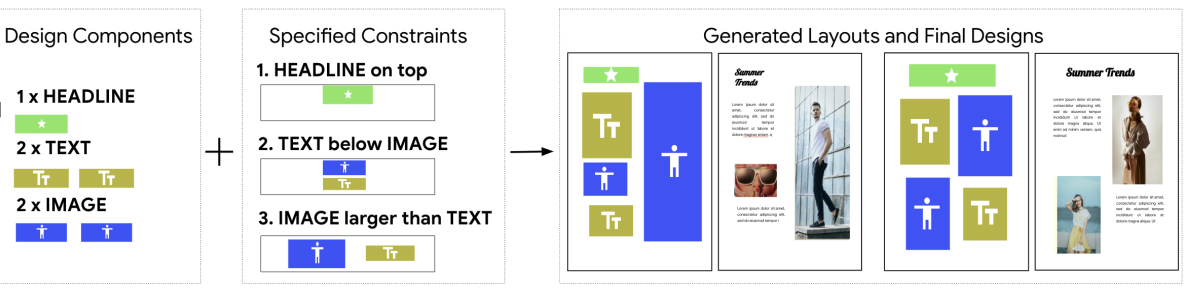
NDNのコンセプト(図は元論文からの引用)
Attribute-conditioned Layout GAN [7] では読み順・要素の大きさの比・要素の縦横比といった比較的直感的・もしくは定義から自動的に定めることのできる細かな要素を追加入力とすることに取り組み,自然な見た目のバナーレイアウトを生成することに成功しました.
CLG-LO [8] では [7] と対照的に,学習済みの条件付き生成モデルがある時に,post-optimizationとして前述の関係性を満たすような生成モデルのlatent codeを探す探索問題とする新しい方向性の研究が行われています.
課題
ここまで議論してきたように色々な技術が開発されていますが,まだまだ多くの課題が存在します
解の多様性
生成されたサンプルは,実物と見間違うクオリティのものもありますが,[9] によるとconditional generationでは同じ条件を入力にレイアウトを複数生成すると,本来色々な種類が出るべきところなのに似すぎてしまう,等の問題が報告されています.多様な生成を実現する手法やそれを可視化するための評価指標の開発等が求められています.
レイアウトの定義
本稿ではレイアウト情報は位置とカテゴリ情報のみを扱っていますが,例えばバナー画像の自動生成を目標とするなら,そこに実際に挿入される画像・テキストといった情報やフォント等の細かなスタイリング情報も同時に考慮できることが望ましいです.CanvasVAE [10] はその方向で先駆的な研究をしていますが,マルチモーダル情報のモデリングは難しいことが同時に示唆されています.また,[5] のように構造化されたデータ形式を扱うことも,webページのようなより複雑なレイアウトを考えていく上では必須になってくるものと考えられます.
おわりに
レイアウト生成というと画像や文章の生成に比べると非常に簡単だというイメージを持たれるかもしれませんが,実際には本記事で議論してきたように様々な難しさや研究の方向性が存在します.Autoregressive Flow や Diffusion Model など最新の生成モデルと組み合わせたり,GPTに代表されるような万能型のマルチタスクモデルを構築するのも面白いかもしれません.このようなトピックに興味のある方は,ぜひ私たちに声をかけてみてください.
参考文献
[1] LayoutGAN: Generating graphic layouts with wireframe discriminators, Li et al., ICLR 2019.
[2] PubLayNet: largest dataset ever for document layout analysis, Xu et al., ICDAR 2019.
[3] Layout Generation and Completion With Self-Attention, Gupta et al., ICCV 2021.
[4] Variational transformer networks for layout generation, Arroyo et al., CVPR 2021.
[5] Coarse-to-Fine Generative Modeling for Graphic Layouts, Jiang et al., AAAI 2022.
[6] Neural Design Network: Graphic Layout Generation with Constraints, Lee et al., ECCV 2020.
[7] Attribute-conditioned Layout GAN for Automatic Graphic Design, Li et al., TVCG 2020.
[8] Constrained Graphic Layout Generation via Latent Optimization, Kikuchi et al., ACMMM 2021.
[9] Diverse Multimedia Layout Generation with Multi Choice Learning, Nguyen et al., ACMMM 2021.
[10] CanvasVAE: Learning to Generate Vector Graphic Documents, Yamaguchi et al., ICCV 2021.
Author