Blog
【CVPR’22】物体検出アルゴリズムの新しい評価指標
Media fundamentalsチームの大谷です。今回は物体検出を評価するための新しい指標を設計したので、その研究について概要を解説します。この研究成果はCVPR2022に採択されています。論文のリンクはこちらです。
Mean Average Precisionはなにを見ている?
物体検出の評価では多くの場合Mean Average Precision (mAP)が使われています。まずAPについて概要を確認しておきましょう。APは検出したオブジェクトをconfidence score順に並べてprecision-recall curveを求め、その曲線の下の面積で求められます。これをカテゴリごとに計算し、全てのカテゴリ上で平均したものがmAPです。ここでは詳細に触れませんが、実際のAPの計算では諸々の実装上の事情があり、それらがAPの振る舞いにおいて少なくない影響を及ぼしています。ここの説明はAPが評価しているものについての簡単な説明なので、実際のAP計算とは異なる点があるので悪しからず。
mAPは物体検出をデータセット全体から見つけたオブジェクトのランキング問題として評価しています。この前提は物体検出を開発しているコミュニティでもあまり意識されていない点ではないでしょうか。この「データセット全体における」「ランキング問題」として物体検出を評価するという姿勢は、なかなかに強い前提です。
一つ論文で出した極端な例を紹介します。下のイラストに示すような、アヒルとロバの検出器、A,B,Cと3枚の画像からなるデータセットを考えます。この例ではある検出器Bはデータセットの画像2枚を完全に無視していますが、mAP上では検出器Aと区別がつきません。APは見つけたオブジェクトを画像からひっぺがして評価するので、データセットの画像それぞれで検出が成功したかどうかという情報は基本的には失われています。これはある画像グループで性能が極端に悪くなっていたとしても、評価指標上では現れないことがあるということです。これは多様な画像で安定した性能を求められるようなアプリケーション、例えば画像認識APIの評価などでは好ましくないでしょう。また検出器Cは大量のロバを誤検出しています。しかし、これらの誤検出はAPを下げません。これは検出された物体のうち、正しいものが誤検出よりも上位にランキングされているかどうかを重視しており、ランキング下位の誤検出については直接ペナルティを課していないことが理由です。
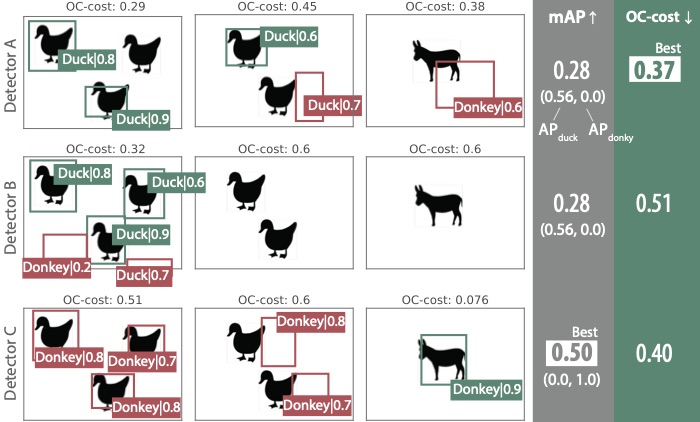
もう一つ、クラス識別を重視するという点もAPの特徴的なスタンスです。APでは予測クラスが間違っていた場合、その検出結果は「完全な失敗」として扱われ、位置の正確性については評価されません。これは扱うクラス数が膨大な場合や、クラス識別よりも位置の予測を重視するアプリケーションには少々厳しすぎる方針かもしれません。
このようにmAPには、データセット全体に対するランキング性能を見ていることに由来する、評価の「クセ」があります。以下は今回の研究で注目したmAPの性質です。
-
物体検出をデータセット全体における検出物体のランキングとして扱っている
-
confidence scoreの低い誤検出の影響は小さい
-
各画像のAPに対する影響は平等ではない
-
クラス識別が位置推定よりも重視される
-
評価時に参照する真値アノテーションが最適でない場合がある
これらの特徴のほとんどは良い悪いというものではありません。最終的にやりたいことが画像データセット全体から見つけた物体領域のうちconfidence scoreの上位~%を検出とするようなアプリケーションであれば、これらの性質はそれなりに妥当と言えそうです。評価の際は最終的にどんな検出器が欲しいのかを考慮して、目的に合った評価指標を使うことが理想でしょう。ですが、今のところ物体検出に関してはAPとAPをベースに改良された指標がいくつかあるぐらいで、実質的な選択肢は限られています。そこで今回は、APとは違った発想で検出結果を評価する別の指標を考えました。
Optimal Correction Cost
今回提案した指標はOptimal Correction Cost (OC-cost)と呼んでいます。OC-costは誤差を含む検出結果を正解に修正するためにかかるコストを使って、検出結果の品質を測ります。この方法は去年物体検出モデルの学習法として提案されたOTAを参考にしています。実際、その最終的な目的を学習とするか評価とするかで、OTAと提案指標は設計が異なってきますが、技術的には多くの部分で共通しています。

まず検出結果と真値アノテーションからコスト行列を作ります。コスト行列のそれぞれの要素はある検出結果を真値アノテーションのどれかに修正するためにかかるコストです。このコストはクラス識別に関する誤差と予測位置の誤差から計算します。このコスト行列からトータルの修正コストが最小となるような検出結果と真値アノテーションの対応を最適輸送問題を解くことで求めます。そしてその時かかった修正コストをOC-costとします。バウンディングボックスに対する編集距離のようなイメージです。この指標の性質としては以下のようなものがあります
-
画像1枚に対して検出精度を評価できる
-
識別の誤差と位置ずれの誤差を同時に評価できる(クラス識別が間違っていても位置予測精度は評価される)
-
適当な真値アノテーションとの比較に基づく評価ができる
-
余分な検出に対してペナルティを積極的に与える
繰り返しになりますが、この性質も最終的なアプリケーションによって良し悪しです。基本的には画像1枚1枚の検出精度が重要で、事前に検出結果を間引いておく必要があるようなアプリケーションに合っていると思います。
OC-costの実例
実際にこの指標の振る舞いを実例を使ってみていきます。左からOC-costが低い(=良いと判断された)検出結果です。まあまあ納得感のある結果ではないでしょうか。

次にmAPとOC-costをそれぞれ使って検出結果をフィルタリングするパラメータを調整してみます。具体的にはNon maximum supressionの閾値パラメータをmAPを最大化、あるいはOC-costを最小化するようにパラメータを最適化しています。この結果を見比べてみることで、それぞれの指標がどのような検出器を高く評価するのかわかります。以下が実例です。

mAPは正しい検出結果を得るチャンスを上げるために、なるべくたくさんの予測を出すモデルを好みます。余計な検出が大量に出力されたとしても、そのconfidence scoreが相対的に低ければあまり問題としません。mAPはユーザがそれぞれconfidence scoreの適切な閾値を決めるものと想定しています。一方、OC-costは余計な検出にはペナルティを与えます。検出結果を事前にフィルタリングしておく必要があるような場合にはOC-costを用いたチェックが有効でしょう。
さいごに
物体検出アルゴリズムの新しい評価指標を紹介しました。さらに詳しい内容については論文を見ていただけると幸いです。さて、物体検出の評価もこれをもって十分とはまだ言えません。また他の領域でも評価方法の改良はまだまだやることがありそうです。コンピュータビジョンの発展に評価の観点から貢献することに興味のある方がいればぜひご連絡ください。
Author