Blog
VQVAEを中心とした生成モデルの動向
AI Lab Creative Researchチームの下田です. 本稿では, VQVAEを中心とした生成モデルの動向というタイトルで近年の生成モデルの動向について, VQVAE[1]を中心に紹介します.
これまで様々な深層生成モデル(図1)が提案されてきましたが, その中でも特に, GANとVAEによるアプローチは広く注目を集めてきました. 高解像度な画像生成手法としてはGANが黎明期から注目を集めていましたが, 近年の高解像度な画像生成についての論文ではVAEに基づいたモデルもよく目にします. 今回は, 近年の生成モデルの動向について, VQVAEを中心に調べたので情報共有できればと思います.

図1 著名な深層生成モデル(link).
VAE
VAEはLatent code(図1におけるz)をサンプリングし, 復号モデルにより復号することで, 学習データの分布に近い画像を生成可能です. GANとは異なり尤度を明示的にモデリングしており, 多様なデータを生成する上で利点があることが知られています. 一方で, 画像の生成結果がぼやけやすい傾向にあります. (図2, VAEとGANの比較[2])

図2 VAEとGAN, 並びにVAE/GAN(VAEとGANの組み合わせ)の結果例[2].
VQVAE
VQVAE[1]はVAEベースのアプローチにおいて, 高解像度な画像を生成する上で近年頻繁に活用されている手法です. Patchを離散的に符号化し, 自己回帰モデルの生成と組み合わせることで, 多様で高解像度な画像生成を可能にしています.
Latent codeの離散化とPatchについての符号化
VQVAEはLatent codeに一様分布の離散表現を仮定し, Patchについての符号化, 復号を行うモデルです(図3). VQVAEにおける符号化結果はPatchごとに分かれており, 従来のVAEのように単一のLatent codeをサンプリングし, そのまま復号することはできません. そこで, VQVAEでは自己回帰モデルを用いてPatch集合をサンプリングします.
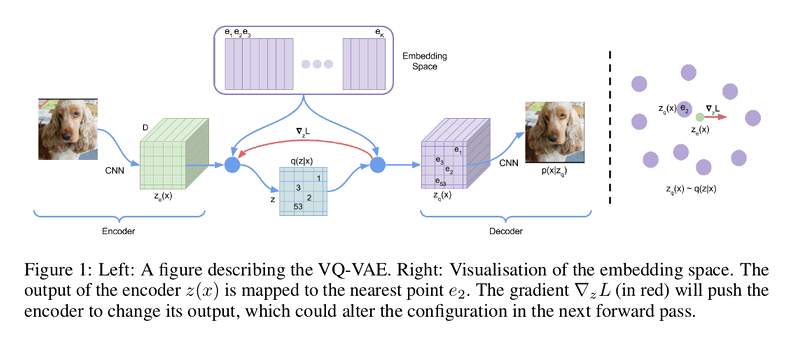
図3 VQVAEの概要.
自己回帰モデルによるPatch集合のサンプリング
自己回帰モデルによる生成手法はNLP分野をはじめとした幅広い分野で使われている生成手法です. 自己回帰モデルによる生成においては, 既知の時系列情報を入力として未知の時系列情報の尤度を推定し, この尤度から時系列情報のサンプリングをします. サンプリングと尤度の更新を繰り返し, 徐々に全体の時系列情報を生成します. 画像分野における自己回帰モデルとしてはPixelCNN[3]が著名です. 連結しているピクセルを時系列情報とみなし, 左上のピクセルから一列ごとに図4のような順(raster scan order)でサンプリングを行い画像を生成します.
VQVAEでは, PixelCNNを活用し符号化された画像のPatchの集合を生成します. Patchをバラバラにサンプリングすれば学習データに存在しない組み合わせが生じやすくなりますが, 自己回帰モデルによりこのような不整合が生じる問題を緩和しています.
また, VQVAEのLatent codeは離散表現になっていますが, このLatent codeの表現がPixelCNNの学習の安定化に役立っています. 連続表現では, 入力の条件を無視しデータの最頻値を出力するように学習してしまう問題(posterior collapse)が発生することが知られていましたが, VQVAEでは離散表現を活用することにより, このような問題を回避し, 自己回帰モデルを高次元な空間で適用可能にしています. また, Top-kサンプリングやTop-pサンプリングをはじめとしたカテゴリカルなデータのサンプリングが可能になっています.

図4 PixelCNN概要.
VQVAE-2
VQVAEにおける離散的なLatent codeに画像の情報を圧縮する方法は, ImageNetのような高解像度かつ大規模な画像データにおいてもスケールすることが報告され(VQVAE-2[4]), 大きく注目を集めました. VQVAE-2[4]はVQVAEについて階層的なLatent codeの活用を加え, 当時のGANベースのアプローチ[5]に匹敵するクオリティの画像を生成しています. また, GANベースのアプローチと比較して, 特定のカテゴリにおいても多様性のある画像が生成可能であることが示されています(図5).

図5 VQVAE-2[4]とBigGAN[5]の比較例.
Patch集合のサンプリング方法
VQVAEの登場により, 高解像度な画像をPatch単位で符号化, 復号できるようになりましたが, Patchの集合のサンプリングは自己回帰モデルに依存しています. 自己回帰モデルは時系列情報を順繰りに生成するので, 推論とサンプリングを繰り返す必要があり, 誤差が蓄積する問題と生成時の計算コストが大きくなる問題があります. VQVAEにおいてもこのような自己回帰モデル由来のデメリットがあります. 近年はPatch集合の生成方法についての研究が注目を集めているように感じられるので, こちらについても紹介します.
VQGAN
VQVAEではPixel CNNを活用していましたが, 近年の時系列データの生成においてはTransformerが標準的な手法になりました. VQGAN[6]ではPixelCNNの代わりにTransformerを活用することを提案しています. 精度, 速度ともに画像生成のために設計されたPixel CNNを上回っていることを示しました. また, VQGANではGANも併用しています. GANを併用することにより, 一定の範囲内であればPatchの解像度を圧縮しても高解像度な画像が復元可能であることを示しました.
また, VQGANではサンプリングの順序に着目した実験も行っています. 著者らは背景から画像を生成することになるであろう”Spiral in”(外側から中心にサンプリング)が最もよくなると予測していましたが, 結果としては”Row major”(raster scan order)が優れていたと報告しています(図6). 原因は不明ですが学習時にランダムな位置のPatchをマスキングしているのでその影響がでているのではないかと考えられます.

図6 VQGANによるサンプリングパターンと生成画像の変化
サンプリング方法の派生として, サンプリング回数を減らし高速化を狙うために, 複数のパッチを同時にサンプリングするアプローチがあります. Image-GPT[7]では列ごとにサンプリングする方法(図7a), Cogview2[8]においては, Inpaint+斜めにサンプリングしていく方法(図7b)を提案しています.

図7 その他のサンプリングパターン例.
VQDiffusion
VQDiffusion[9]においては, Diffusionモデルを活用してPatch集合のサンプリングを行う方法を提案しています(図8). Diffusionモデルは, VAE同様尤度を最大化する生成モデルですが, VAEとは異なり符号化に学習が不要です. そのため, 符号化に失敗する恐れを考慮せずに, 自己回帰モデルによるサンプリングをDiffusionモデルによるサンプリングに置き換えることが可能です.
VQDiffusionにおいては, 従来のDiffusionモデルをMasked Language Model(MLM)に見立て, Patch集合のサンプリングに適用しています(図8). 自己回帰モデル同様, 繰り返し推論する必要がありますが, 生成順が存在せずサンプリングによる誤差の蓄積の心配がありません. また, 自己回帰モデルと比較して, 速度と生成クオリティについて良いトレードオフを達成しています.
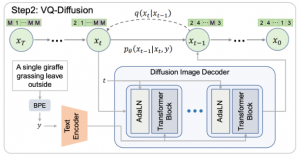
図8 VQDiffusionによるPatch集合のサンプリング
まとめと今後の展望
今回のブログではVQVAEを中心とした生成モデルの動向というタイトルでVQVAEを中心とした近年の生成モデルの動向について紹介しました. VQVAEの登場により, VAEベースのアプローチでも高解像度な画像が生成可能になりましたが, 依然として計算速度の問題などが残っています. クリエイティブ領域ではインタラクティブな画像生成によるアプリケーションなども考えられるので, 生成速度についての研究には今後も注目したいです. 現状のVQVAEベースの手法では, Diffusionモデルと組み合わせた方法が良い性能と速度のトレードオフを達成していますが, Diffusionモデルは実装が複雑であるといった問題もあります. Cogview2のようなサンプリング方法を工夫するようなアプローチの進展にも注目していきたいです. できれば, 従来のVAEのようにワンショットでLatent codeを復号可能で有望なモデルが出てきて欲しいところですが, まだしばらくは難しそうな状況かと思います. 近年は自己教師あり学習などにおいて, 符号化の研究も広く注目を集めているので, こちらの進展にも注目しておきたいです.
[1]Neural Discrete Representation Learning, Van et al, NIPS, 2017
[2]Autoencoding beyond pixels using a learned similarity metric, Boesen et al., ICML 2016
[3]Conditional Image Generation with PixelCNN Decoders, Van et al, NIPS 2016
[4]Generating Diverse High-Fidelity Images with VQ-VAE-2, Razavi et al, Advances in neural information processing systems, 2019
[5]Large Scale GAN Training for High Fidelity Natural Image Synthesis, Brock et al., ICLR 2019
[6]Taming Transformers for High-Resolution Image Synthesis, Esser et al, CVPR 2021
[7]Generative Pretraining from Pixels, ICML 2020
[8]CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers, Ding et al., arXiv preprint arXiv:2106.06866
[9]Vector Quantized Diffusion Model for Text-to-Image Synthesis, Gu et al, CVPR 2022
Author