Blog
【採択論文紹介】デザイナのグラフィックス編集工程を模した機械学習モデル (CVPR2023)
AI Lab Creative Researchチームの井上です。我々のチームでは広告クリエイティブの制作支援と自動生成に関する研究開発に取り組んでおり、その中でも自分は特にバナー画像の自動生成技術の開発に取り組んでいます。この記事ではCVPR2023にhighlight (採択された論文の中の上位10%です) として採択されたデザイナのグラフィックス編集工程を模した機械学習モデルに関する論文について紹介します。
Towards Flexible Multi-modal Document Models
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
はじめに
バナーやスライド、ポスターなどといったグラフィックデザインは、多くの場合オーサリングツール (例: Photoshop) 上で制作され、画像・テキストとそれに対する多種多様な装飾のメタデータ集合としてデータが保持されています。皆さんがデザインを編集する時、完成形にいきなり辿り着く事はおそらく非常に稀であり、大半の時間は作業中のデザインに対し、編集を加えて良ければ採用し、しっくりこなければ遡ってやり直す、というプロセスを繰り返すことになると思います。本研究ではこのプロセスをサポートするために、編集案を提示する機械学習モデルを提案しました。図1に示すように、提案モデルは作業中のデザインのマルチモーダルな情報を入力とし、レイヤーの配置、画像の当てはめ、細かなテキストスタイリングなど様々なタスクを行うことを目標としています。
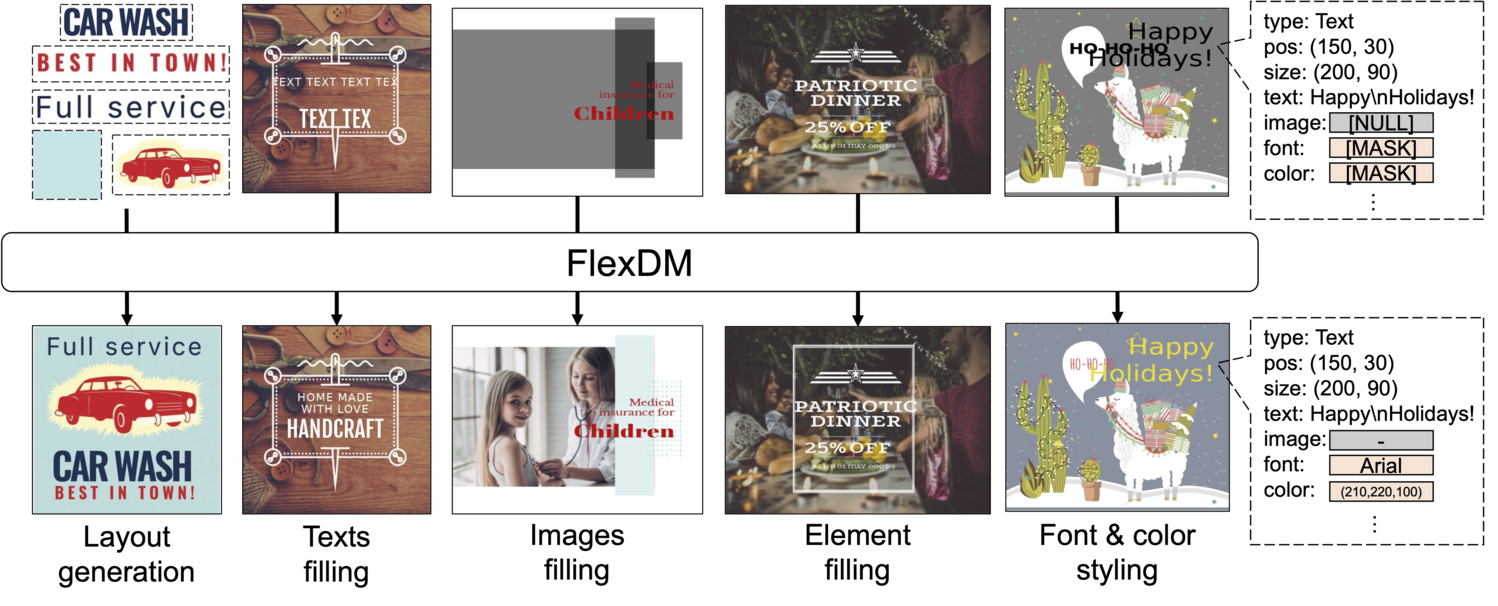
図1: 提案手法で解くことが出来る、ベクターグラフィックドキュメント生成タスクの例。
提案手法: flexible document model (FlexDM)
このようなモデルを作るにあたって難しい点は2点あります。(i) デザインに含まれる変数の多様性: フォントサイズのような1次元で表現できる属性から画像やテキストのような高次元データまで、連続変数もあれば離散変数もあり、各要素あたりの属性数もそれなりに多いです。(ii) タスクの多様性: デザインの編集工程をステップ毎に見ていくと,実に多様な入出力対を扱っています。それぞれの状況に特化したモデルを作るのは非現実的です。
問題を解くための鍵となるデータ構造を図2の左側に示します。それぞれの要素の各属性を固定長の特徴量で表現すれば、グラフィックデザインは要素数 × 属性数個の特徴量ベクトルの配列とみなすことが出来ます。一番のポイントは、我々が扱いたいタスクの多くが実はこのデータ構造上では特徴量学習の文脈で頻出の「穴埋め学習」(例: 画像 [1] / テキスト [2] )とみなせることです。図2の右側のように、出力してほしい部分に [MASK] トークンを置き,ネットワークは周辺文脈情報からこの部分を予測します。様々な入出力パターンがこのマスキングパターンの切り替えで表現できます。
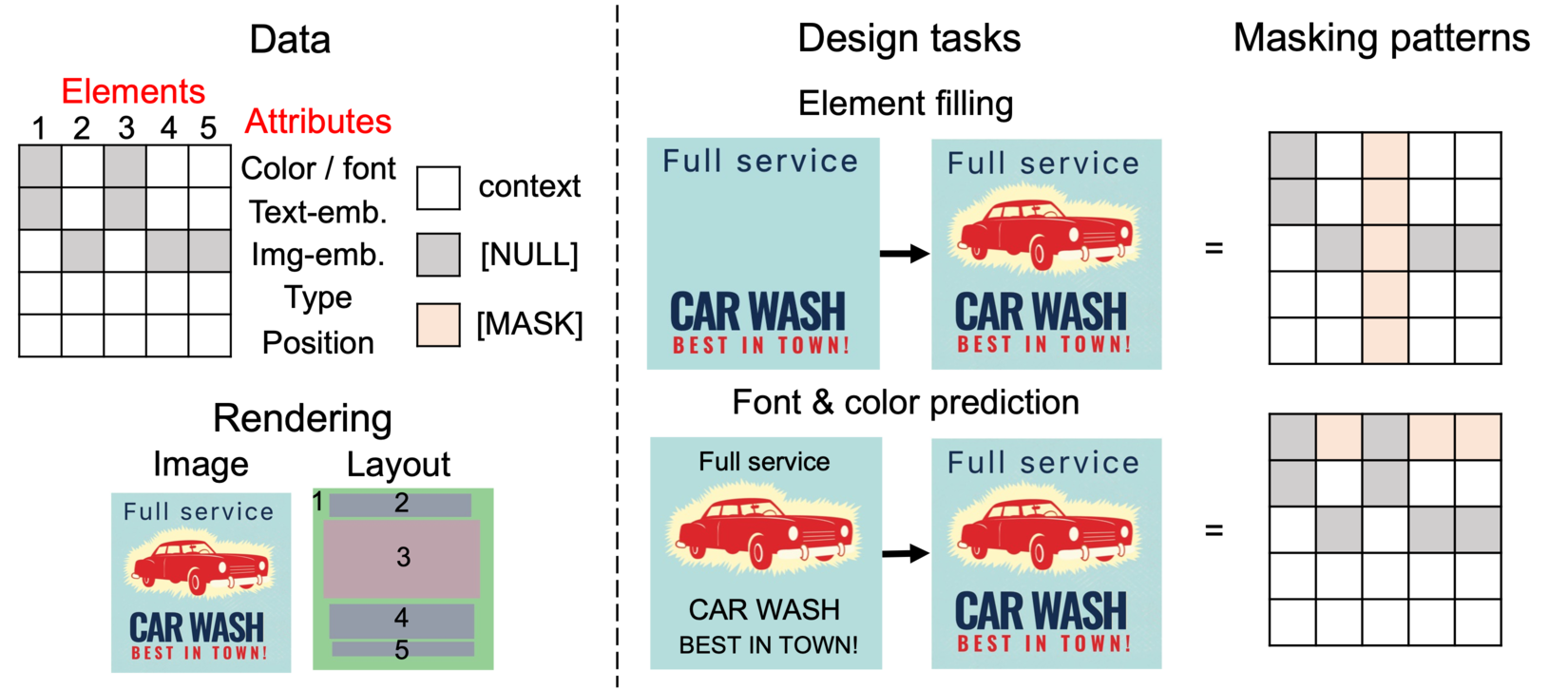
図2 左: 本研究で取り扱うデータ構造 (上) と その見た目及びレイアウトを描画したもの (下)。各要素が取り得ない属性 (例: 画像要素のフォント属性) は [NULL] を用いて埋める。簡単のために幾つかの属性をまとめて表記している (例: Position は実際には位置とサイズの4変数。) 右: 生成タスクとそれをどう穴埋め問題の枠組みで表現するかの例。
実験結果
提案手法で様々なタスクを解いた結果の例を図3に示します。グラフィックデザインには画像やテキストが最大十個程度存在しており、同時生成は技術的に挑戦的すぎるため、画像やテキストは事前に CLIP [3] で符号化して比較的低次な特徴量として扱っています。 提案モデルによって様々なデザイン過程がモデリングできることがわかります。我々はさらに既存研究で扱われていた幾つかのタスクにおいて、提案モデルがタスク特化モデルに近いパフォーマンスを示すことを定量的に確認しました。詳細についてはぜひ論文をご覧ください。
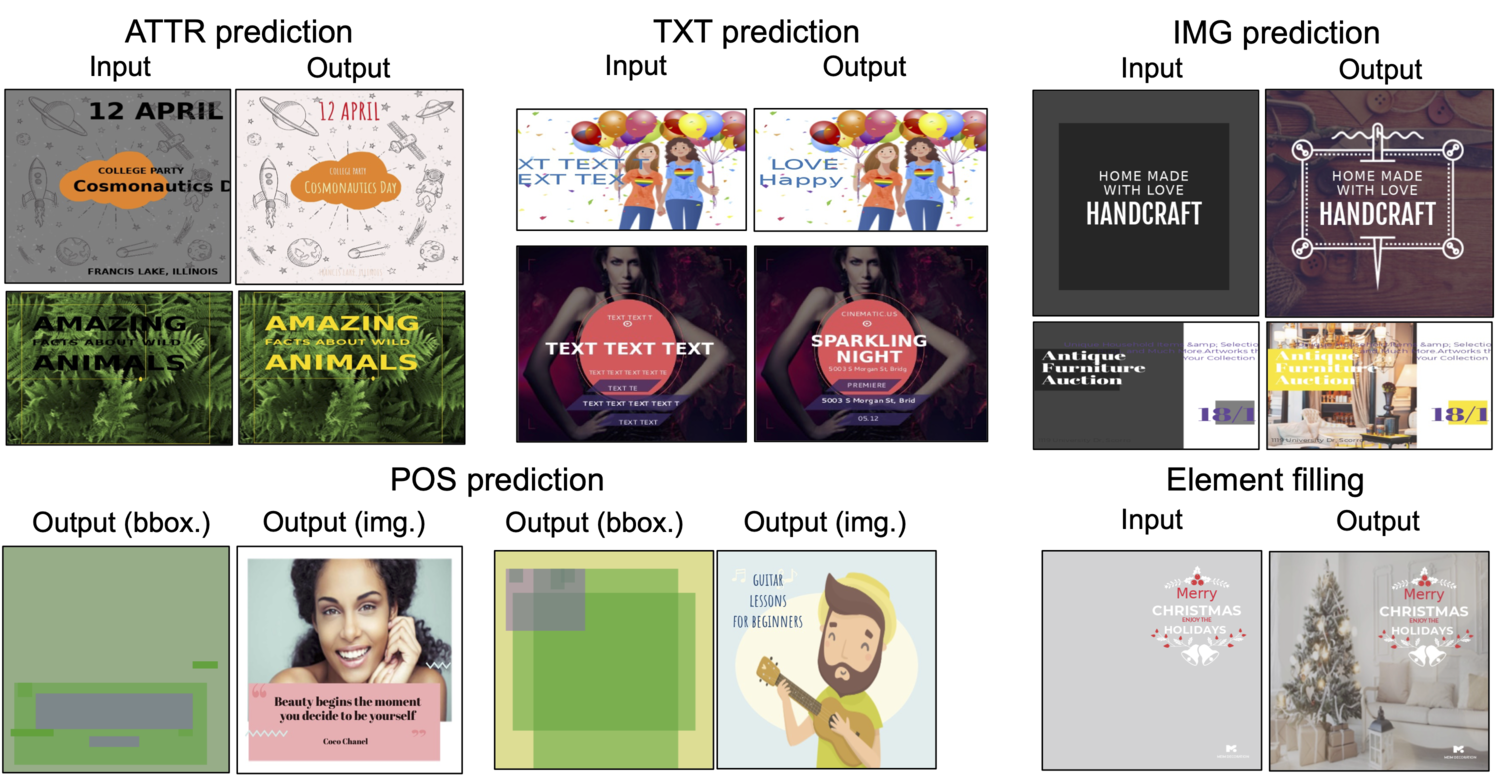
図3: FlexDMのCrelloデータセット [4] における予測結果の例。[MASK] トークンは入力側では グレーの塗り (画像)、ダミー文字列 (テキスト)、デフォルト値(その他特徴、例えばテキストの色やフォント)などで表されている。POS predictionは位置情報以外の全ての要素がわかっていて位置を当てるタスク。画像・テキストは予測された特徴量から素材データベース内で最近傍検索することで得た素材を表示して最終的な予測結果を可視化している。
おわりに
本研究では、デザイナのグラフィクス編集工程を模した機械学習モデルを提案・検証して一定の成果を得ました。提案手法は性能に関してはまだまだ発展途上で、画像・テキストの埋め込みに頼らない完全なend-to-end生成、より良いモデルやより大きなデータセットの構築、要素の有無よりも複雑な指示による編集 (例: 曖昧なヒントや言語指示)、など、様々な拡張が考えられます。弊社では博士課程の学生を対象にリサーチインターンシップを募集しています。このような研究に興味を持たれた方はぜひ私たちに声をかけてみてください、一緒に研究しましょう。
参考文献
[1] Devlin et al., “Bert: Pre-training of deep bidirectional transformers for language understanding”, In NAACL, 2019.
[2] He et al., “Masked Autoencoders Are Scalable Vision Learners”, In CVPR, 2022.
[3] Radford et al., “Learning transferable visual models from natural language supervision”, In ICML, 2021.
[4] Kota Yamaguchi, “CanvasVAE: Learning to Generate Vector Graphic Documents”, In ICCV, 2021.
Author