Blog
グラフィックスデザインのための機械学習研究動向
こんにちは、AI Labの山口です。
以前の記事でもお伝えした通り、AI Labでは広告表現を生成するための技術開発に取り組んでいます。広告表現を直接のターゲットとしてバナー画像や動画を生成するような研究は多くは存在しませんが、それでも最近は深層生成モデルを代表として、広告表現の生成につながりそうな要素技術が見られるようになってきました。
グラフィックスデザインでは一般にベクター形式のデータと解像度の高いラスタ画像を扱います。解像度の高いラスタ画像を生成する試みはこれまでにもいくつか見られてきましたが(Glow、BigGAN、StyleGAN、GauGAN)、これだけではポスターやバナー制作のようなベクター形式の画像編集に用いることができません。幾何変換、ストロークやポリゴンのようなデータ表現、フォントなど、扱うべきデータはピクセル以外にも多く存在します。
そこで、今回の記事ではベクター形式での画像編集や画像生成を念頭に置いた最近の研究事例をいくつか紹介します。
Vectorization
Vector Image Generation by Learning Parametric Layer Decomposition
Othman Sbai, Camille Couprie, Mathieu Aubry
arXiv:1812.05484

Fig 1 from the paper
与えられた画像を解像度フリーな単色のレイヤー群に分解する手法を提案したもの。座標系からマスクを描く関数のパラメータとそのマスクの色を、入力画像から逐次的に推定しています。全て微分可能なプロセスで記述でき、また座標系の連続値を入力とすることで解像度を問わないレイヤー分解ができます。
かなり実験的な取り組みのようで、実際にはこの手法ではかなりぼやけた画像が生成されるものの、画像のスタイル変換を後処理的に噛ませることで見た目の良い画像に仕上げることができるとのこと。小山らの色分離手法に比べると入力画像の再現性は低そうですが、レイヤーそのものを関数で表現できる点は興味深いです。例えば関数として図形を使ったフィッティング(=完全なベクター化)をかけることも原理的には可能でしょう。
ラスタ画像からレイヤーが一旦分離されてしまえば、例えば色調を変える、といった画像のスタイリング編集は容易にできます。自然画像よりもイラストのような、色分布が偏ったデータで真価を発揮しそうです。画像圧縮手法としての一面もあります。
End-to-End Wireframe Parsing
Yichao Zhou, Haozhi Qi, Yi Ma
arXiv:1905.03246

Fig 1 from the paper
ワイヤーフレームをEnd-to-endで抽出する手法。ワイヤーフレームは線分、交点を抽出し、つなぎ合わせる必要がありますが、この論文では一貫して全てを一つのネットワークで出力するようにモデルを設計しています。モデルはバックボーンCNN、交点のサンプリング、線分のサンプリング、最後に線分の判定をするモジュールをつないでいます。
Semantic Segmentation for Line Drawing Vectorization Using Neural Networks
Byungsoo Kim, Oliver Wang, A. Cengiz Öztireli, Markus Gross
Eurographics 2018
Author website

重なりを考慮してストロークを分割するベクター化の手法。ある点が他の点と同一のパス上に存在するかを判別するPathNetと、ある点がパスの交差上に位置するかを判別するOverlapNetを使い、マルコフ確率場でピクセルのラベリングを行います。これによってパスのインスタンスを分割します。潜在関数としてニューラルネットワークを用いている点がポイントです。一旦パスをそれぞれラベリングができれば、パスのアウトラインを出すことで完全なベクター化ができます。
Learning to Infer Graphics Programs from Hand-Drawn Images
Kevin Ellis, Daniel Ritchie, Armando Solar-Lezama, Joshua B. Tenenbaum
NeurIPS 2018
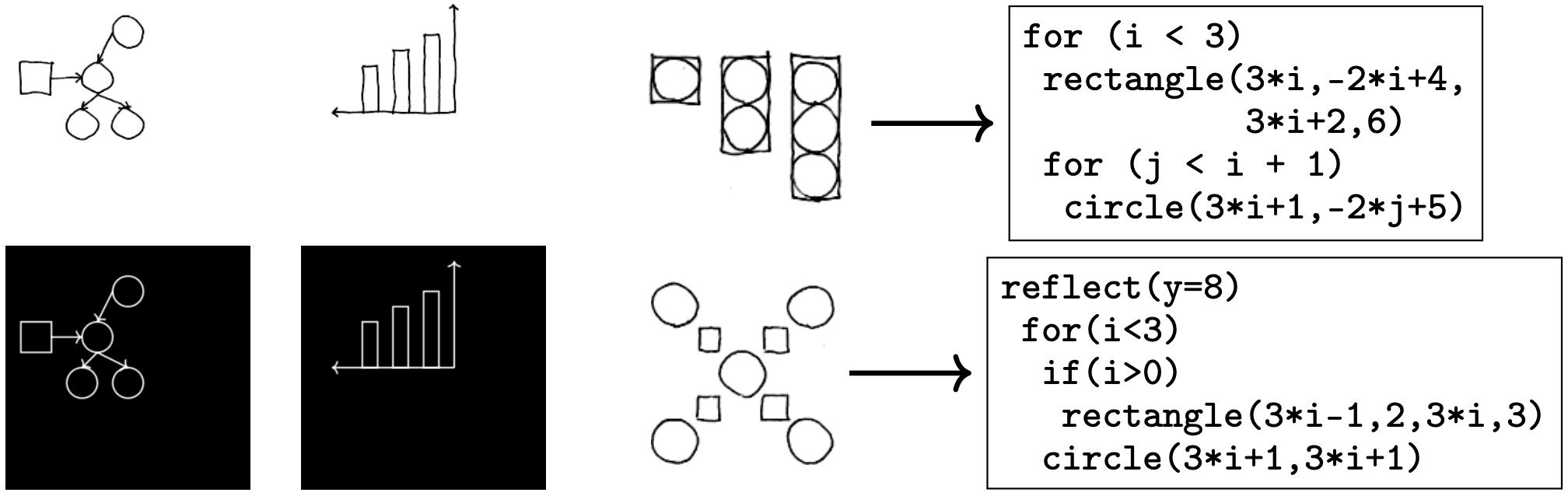
Figure 1 from the paper
スケッチからこれを生成するプログラムを出力する手法。手法は大きく二つのステップに分かれていて、最初にスケッチから図形要素の抽出、そして図形要素群からプログラムの記述が行われます。スケッチからの図形要素の抽出は畳み込みネットワークにアテンションを組み込んだもので、 circle(x=7, y=12) のような図形プリミティブを認識します。これをプログラム言語の文法に従い最適化問題として定式化し、適切なプログラム記述を探索します。各ステップは認識だけでなく生成もできます。
StrokeNet: A Neural Painting Environment
Ningyuan Zheng, Yifan Jiang, Dingjiang Huang
ICLR 2019
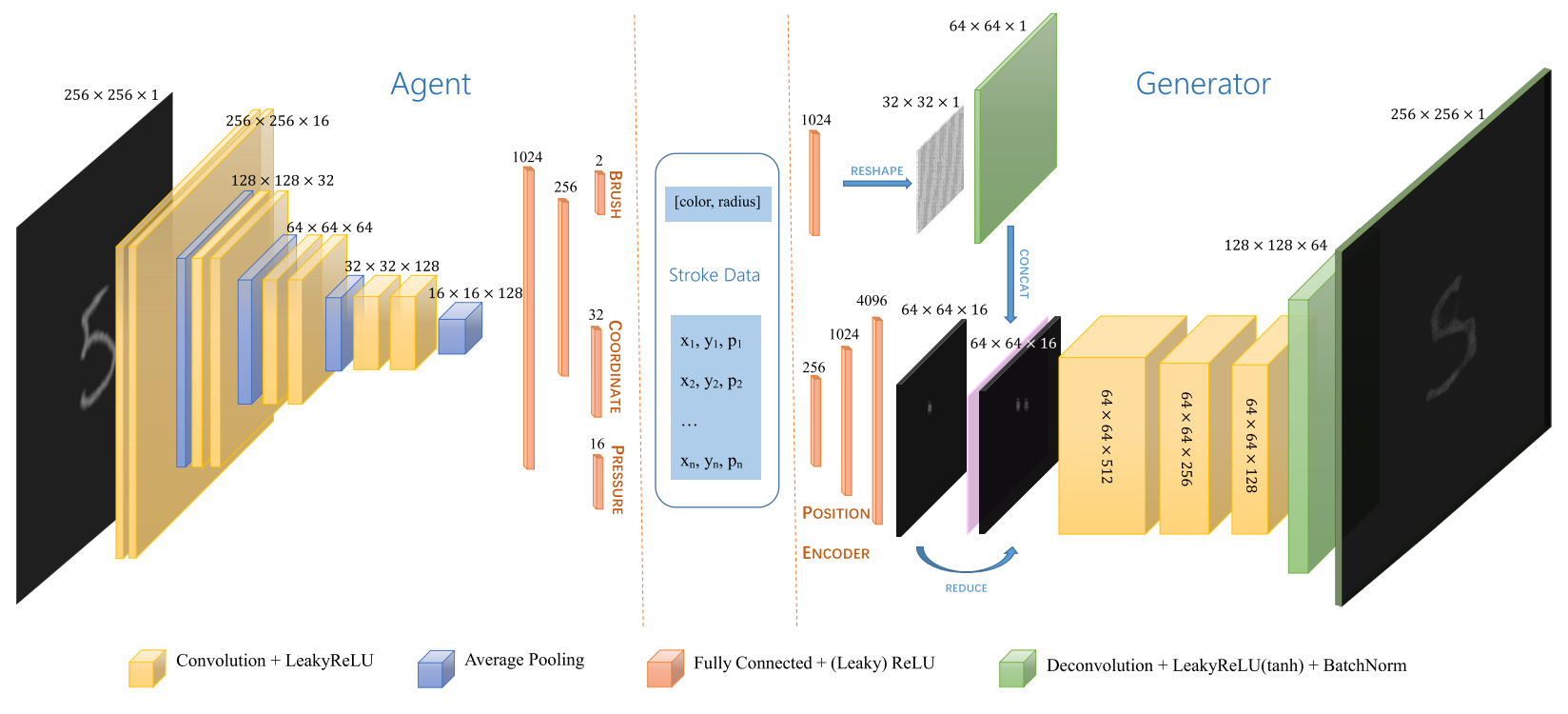
Fig 1 from the paper
ストロークを筆の太さ、色、座標・筆圧のシーケンスのタプルとして捉え、ここから画像を生成するMLPと、与えられた画像からストロークを再現するエージェントを強化学習する手法。エージェントは与えられた画像と現在のキャンバスを入力としてVGGベースのCNNを使ってストロークの一点を再帰的にキャンバスに足していきます。描画環境には一般のWebGLレンダリングエンジンを用いていて、微分できない環境でも強化学習を使ってストローク表現を探索できることを示しています。強化学習を用いた描画は最近よく見られるようになり(PaintBot、T Zhou, 2018、Z Huang, 2019、R Nakano, 2019)、今後も目が離せません。
関連: David Ha and Douglas Eck. A neural representation of sketch drawings, arXiv:1704.03477
Image composition
ST-GAN: Spatial Transformer Generative Adversarial Networks for Image Compositing
Chen-Hsuan Lin, Ersin Yumer, Oliver Wang, Eli Shechtman, Simon Lucey
CVPR 2018
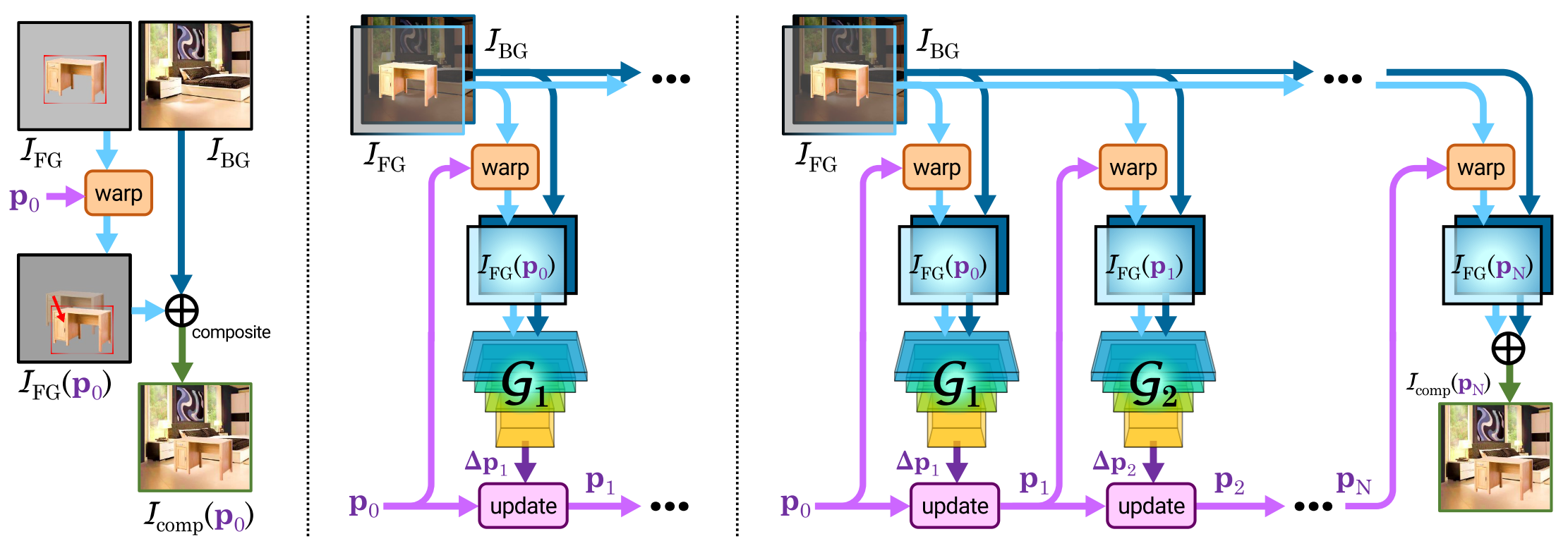
Fig 2 from the paper
Spatial Transformer(M Jaderberg 2015)ではニューラルネットを使って微分可能な画像のワープを実現していました。この仕組みを使い、新しい物体を背景の中に設置するモデルがST-GANです。こちらはアフィン変換のようなワープのパラメータ差分を物体画像と背景画像から逐次的に求め、物体の配置場所を決定します。学習の際により自然な画像になるように敵対的損失関数を含めているため、ST-GANと呼ばれています。逐次的にワープパラメータを推定する理由はおそらく解が一意ではない、大きな幾何変換を一度に推定すると細かい精度が悪い、といった理由があるようです。
よく見る画像生成モデルでは直接ピクセルのパターンを生成していますが、この方法は解像度が固定されるという弱点があります。しかし、ST-GANの利点は解像度に依存しないワープパラメータを求める点にあります。実際、ST-GANの推論は低解像度の画像で行い、求めたワープパラメータを高い解像度の画像に適用するという使い方が想定されています。ベクター画像には非常に相性の良い手法でしょう。
Compositional GAN: Learning Image-Conditional Binary Composition
Samaneh Azadi, Deepak Pathak, Sayna Ebrahimi, Trevor Darrell
arXiv:1807.07560
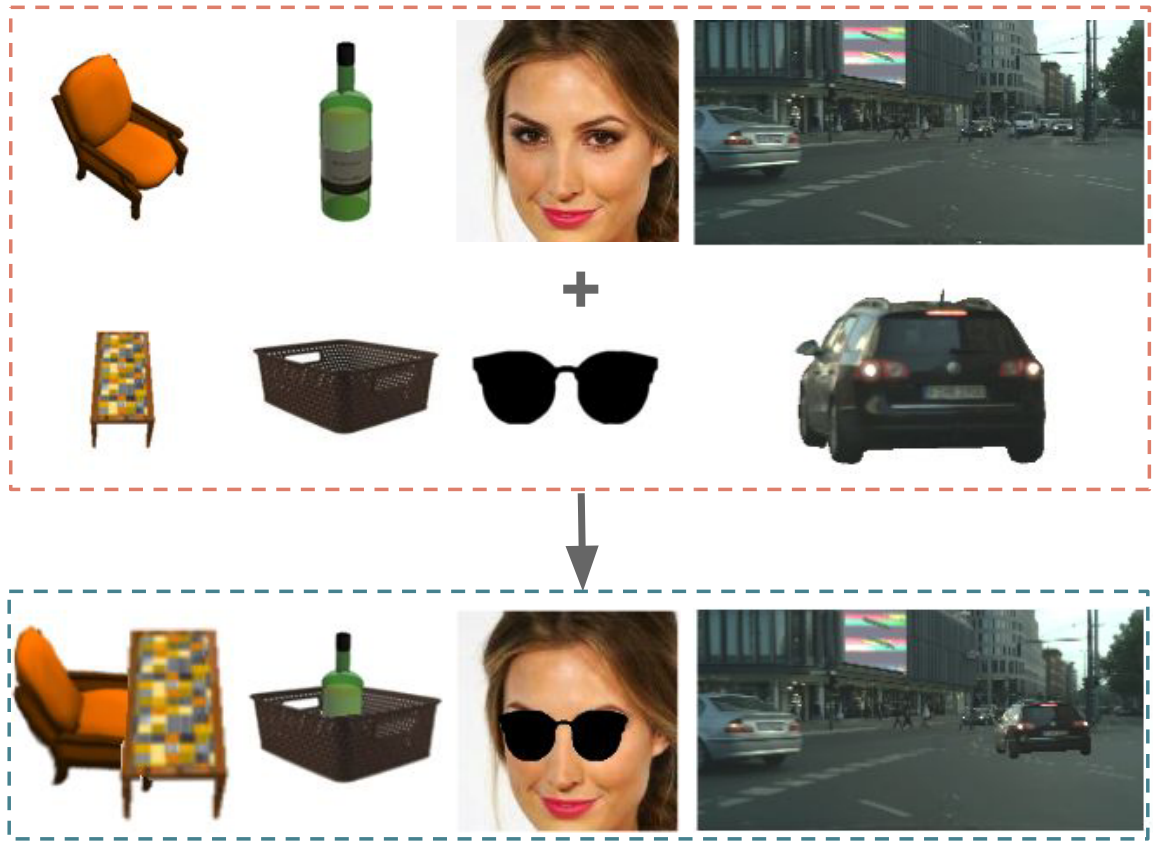
Fig 1 from the paper
二枚の画像の関係性を考慮して適切に合成するモデル。二つの物体を置いた時の合成画像の分布が自然画像の分布に近くなるように学習を行います。あらかじめマスキング済みのデータセットに対し、Spatial TransformerまたはRelative Appearance Flow Network(RAFN)と呼ぶencoder-decoderモデルを使い入力画像を相対座標にワープさせたのち、これをcomposition-by-decomposition (CoDe)と呼ぶネットワークに入力して画像を合成します。これは二つの画像を入力して一枚の画像として出力するGANで、合成画像から二つの画像を分離するself consistencyを考慮して学習させています。また、合成画像を入力としてマスクの推定を行うGANも組み合わせて損失関数を構成しています。ペアとなる入力と合成画像がない場合、インペインティングを使って画像を補間したものを使用しています。テーブルと椅子、顔にサングラス、道路に車といったデータで評価実験を行なっています。
Self consistencyが特徴的で多くのGANを組み合わせた手法ですが、ST-GANと同じく解像度に依存しないワープを使っている点、最終的な画像が尤もらしいかどうかを敵対的損失を使って学習させる点など、重要な点では共通するところも見られます。
Fonts
TET-GAN: Text Effects Transfer via Stylization and Destylization
Shuai Yang, Jiaying Liu, Wenjing Wang, Zongming Guo
AAAI 2019

Fig 6 from the paper
フォントのエフェクトを転移するGANの一種。スタイリングと逆方向のでスタイリングを学習します。スタイル変換系でよく見られるモデル構成ですが、フォント効果のデータセットを構築している他、少数のサンプルでも学習できるように一つの画像からのパッチのサンプリングする例も提案しています。
関連: Controllable Artistic Text Style Transfer via Shape-Matching GAN
A Compositional Textual Model for Recognition of Imperfect Word Images
Wei Tang, John Corring, Ying Wu, Gang Hua
arXiv:1811.11239
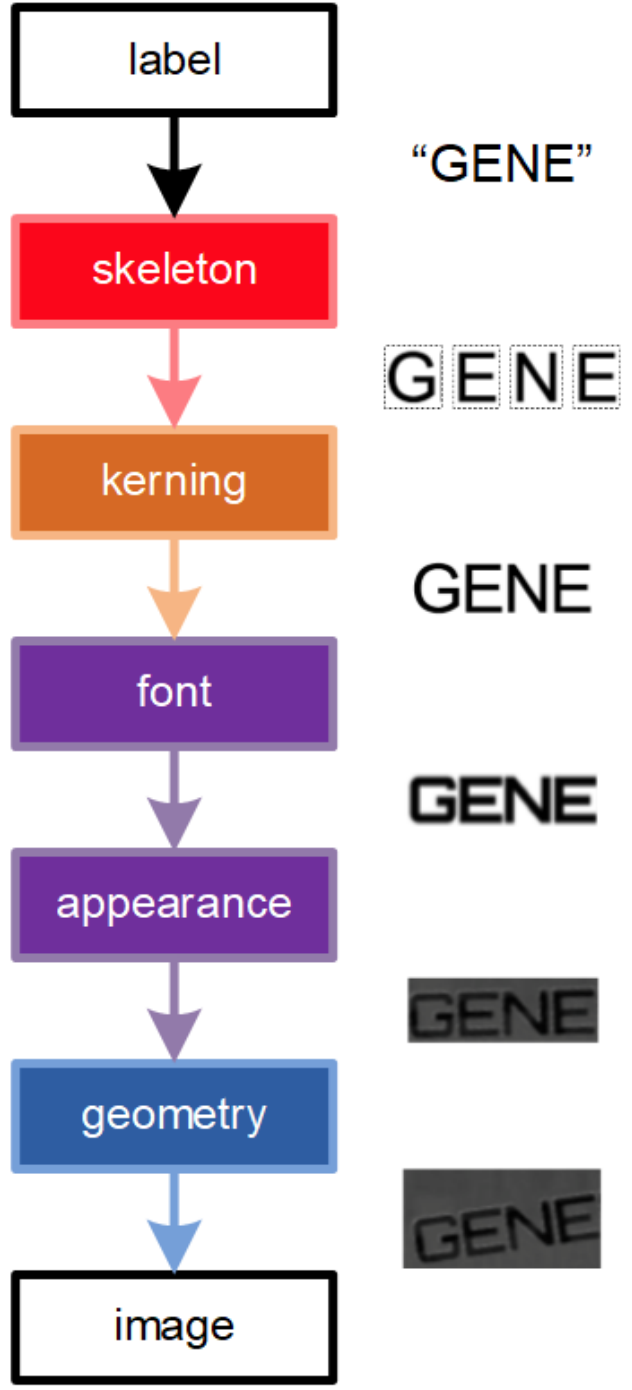
Fig 1 from the paper
テキストのレンダリングは大きく以下のプロセスに分けられます。
- Skeletonization: 単語を文字列に分割
- Kerning: 文字間隔を調整
- Font: 字体を決定
- Appearance: 色やシャドウなどの効果付け
- Geometric distortion: 幾何変換
この論文ではそれぞれのステップの逆変換を施すend-to-endなモデルの構築を目指し、各ステップに対応するニューラルネットワークを記述しています。OCRでは単語の認識が最終的な目標になりますが、各ステップを微分可能なレンダリングモジュールで記述することができれば、例えば文字認識以外のパラメータをニューラルネットワークで最適化することも可能になりそうです。
おわりに
ラスタ画像のベクター化、画像合成、フォントに関していくつか論文を見てきました。ニューラルネットワークでend-to-endに扱えるように、微分可能なモジュールを設計する、強化学習で微分不可能なシステムを扱う、ラスタ画像につきものの解像度の問題を回避するデータ構造、といったアイディアが取り入れられていることがわかります。この記事では取り上げませんでしたが三次元グラフィックスでも微分可能なレンダラーが提案されて以降、ライブラリが整備されるなど、コンピュータグラフィックス領域で扱っていたトピックに急速に機械学習が入ってきています。
サイバーエージェントAI Labでは「広告表現のための機械学習」に取り組んでいます。この記事で上げたような研究内容に興味のある方はぜひ学会などで私たちに声をかけてください。
Author