Blog
人間の意思決定とロボットの意思決定、コミュニケーションにおいて何が違うのだろうか

要約
- 人間もロボットも日々意思決定して存在している
- 人間の意思決定とロボットの意思決定、コミュニケーションにおいて何が違うのだろうか?
- 現状では、対話相手の心的状態を理解した上での意思決定ができないところが異なる
- 将来には人間の意思決定とロボットの意思決定にコミュニケーションにおいて違いはないといえるかもしれない
- もし、そうでないとしたら、それが人間らしさというものになるのだろう。
はじめに
我々は常に意思決定をしている。例えば、休日に何をするかなど枚挙にはいとまがない。
もし、この意思決定が人工物、例えばコンピュータができるとしたらどうだろうか。例えば、命令が与えられていない時何をするかなど人と同じく枚挙にいとまがない。
この問いに先駆的に取り組んだ人はノーベル経済学賞を受賞したハーバートA・サイモンである。ハーバートA・サイモンはこの問いについて『意思決定の科学』[1]にまとめた。『意思決定の科学』では、経済の観点において、人間とコンピュータとの意思決定の違いについて述べている。「発見的な問題解決」はコンピュータには解決できないとサイモンは述べている。
今回はこのサイモンと異なる観点で、「人間の意思決定とロボットの意思決定、コミュニケーションにおいて何が違うのだろうか」という問いを取り扱う。一般的な意思決定から始まり、サイモンのようにコミュニケーションの観点に絞り、科学的な面や工学的な面から比較を行う。果たして人間とロボットは意思決定、コミュニケーションにおいてそれらを分かつ明確な境界はあるのだろうか。
現状における人間の意思決定とは
まず、人間の意思決定とは何かを考えてみよう。
一般的な人間の意思決定とは
一般的な人間の意思決定とは、”問題解決に当たって,実行可能な行為の中から最適と思われるものを選択すること”[2]である。なお、傍観のような積極的に何もしないことも意思決定に含まれるとも考えている。また、感覚遮断実験のように何も刺激を与えないときに積極的にその環境から出ようとすることも意思決定に含まれると思われる。
この章では個人の意思決定について焦点を合わせることにする。したがって、集団や法人といった存在の意思決定は特に取り扱わないとする。
人間の意思決定をすべて説明する理論はまだ難しいと言った状況にある。現状では意思決定の一部を切り取り、モデル化している段階にある。したがって、今回は意思決定のモデルを数多く紹介するのではなく、ロボットと関連の深いものを中心に説明していく。
人間の意思決定に関する初期の研究としてパブロフが発見した条件反射がある。条件反射はパブロフの犬という有名な実験で示された意思決定方法である。パブロフの犬で発見したことは特定の条件では意識によらず無意識が行動を決定することを後天的に学習できるということである。ただし、意思決定と言うにはあまりに機械的な仕組みである。
人間の意思決定に関する中期の研究としてスキナーが体系化したオペラント条件付けがある。オペラント条件付けはスキナー箱という名前で有名な実験で示された意思決定方法である。スキナー箱で発見したことはブザーという先行刺激をネズミに与えることで、餌が出てくるレバーを押す行動が決定されるように意識的に学習できるということである。オペラント条件付けによる意思決定の頻度の高まりを強化と呼ぶ。
人間の意思決定に関する後期の研究としてベンジャミン・リベットの研究がある。ベンジャミン・リベットの研究で発見したことは、ボタンを押すという単純な意思決定は意識によって決められる前に脳が決めているということである。この研究から人間には自由意志が存在しないのではないのかとの仮説が立てられ、物議が醸されている。
以上の研究から、人間の意思決定の一部は極めて機械的であり、ロボットに実装可能であると考えられる。
コミュニケーションにおける人間の意思決定とは
コミュニケーションにおける人間の意思決定とは、対話相手から何らかの反応を受け取ったときに何らかの反応を返すことである。なお、積極的に無言を返すことも意思決定に含まれるとも考えている。
最も単純で大切なコミュニケーションに関する意思決定は挨拶だろう。対話相手から挨拶された場合、通常挨拶し返すのが礼儀である。しかし、無言で答えることも選択肢の1つとしてある。もちろん無言で答えた場合、お互いの仲が険悪になるということは言わずもがなだろう。
もう少し複雑なコミュニケーションに関する意思決定としては対話がある。対話にはいろいろな要素が含まれている。たとえば、対話を開始すべきか終了すべきかどうかというエンゲージメントの問題や、対話中に話を切り出すかというターン・テイキングの問題など様々ある。
最も重大と思われるコミュニケーションの意思決定として治療方針の決定がある。例えば、延命治療を行うかどうかは本人の意思決定によって決めるものだが、意思決定できない状態にある場合もある。
現状におけるロボットの意思決定とは
次にロボットの意思決定とは何かを考えてみよう。
一般におけるロボットの意思決定とは
ロボットの意思決定とは、センサからの入力に対して、モーターなどのエフェクターへ何を出力するかをアルゴリズムに基づき決定することだと筆者は考えている。なお、積極的に何も出力しないことも意思決定に含まれるとも考えている。このように定めるとロボットアームの制御から複数ロボットの協調動作まで広く定義される。
この定義に基づいた最も単純なロボットの意思決定方法とはルールベースである。ルールベースとは「もしAが入力されたならば、Bを出力する」という仮定法で記述されるアルゴリズムである。例えば、もし人間から「こんにちは」と話しかけられたら、ロボットは「こんにちは」と挨拶し返すことがある。人間の条件反射はまさにルールベースな行動であると言えよう。
ルールベースを発展させたものとして、エキスパートシステムがある。”エキスパートシステムとは、ある分野の専門家の持つ知識をデータ化し、専門家のように推論や判断ができるようにするコンピュータシステムのこと”[3]である。例えば、エキスパートシステムは、人間は死ぬという知識とアリストテレスは人間という知識から、アリストテレスは死ぬという命題は真であると導くことができる。しかし、このルールベースで実世界の意思決定をすべてを記述しようとすると、無限のルールを有限時間しか存在できない人間が決める必要となる。
ルールベース以外の意思決定方法として、非ルールベースがある。非ルールベースとは、ルールベースではなく、機械学習や統計学、ベイズ推定、最適化手法のことを指す。これらの定義はEUのAI規制ガイドライン[4]の付録を参考にして作った。人間のオペラント条件づけはまさに非ルールベースであると言えよう。
非ルールベースの中で特筆すべき意思決定方法として強化学習が挙げられる。強化学習とは環境の中にいるロボットが環境の状態を観測してその観測結果に基づいて行動することを試行錯誤しながら学習する意思決定方法である。このとき、ロボットの製作者が望ましいと思われる状態にロボットが行動により変化させられたならば、報酬が与えられ、強化される。強化学習は人間のオペラント条件づけの強化をモチーフに作られたものだと考えられている。[5]
逆にロボットの意思決定を制限する指針としてアイザック・アシモフが『われはロボット』にて提示したロボット工学三原則が挙げられる。ロボット工学三原則とは、第一条から優先適用される以下の通りのルールである。
- “第一条 ロボットは人間に危害を加えてはならない。また、その危険を看過することによって、人間に危害を及ぼしてはならない。” ([6]より引用)
- “第二条 ロボットは人間にあたえられた命令に服従しなければならない。ただし、あたえられた命令が第一条に反する場合は、この限りではない。” ([6]より引用)
- “第三条 ロボットは、前掲第一条および第二条に反するおそれのないかぎり、自己をまもらなければならない。” ([6]より引用)
ロボット工学三原則は、SF小説をミステリアスにするための設定ではある。しかし、作中にもある通り、この原則は模範的な人間の行動ルールであり、ロボット工学者はなるべくならばこの原則を守ったロボットを作るべきだとされている。
コミュニケーションにおけるロボットの意思決定とは
コミュニケーションにおけるロボットの意思決定とは、対話相手であるユーザの状態に応じて適切な行動をロボットが決定することと定義できる。この定義からルールベースや強化学習はこの意思決定の問題を解決する手段の例と言える。
特にこの広範に渡るコミュニケーションにおける意思決定の問題を解決する手法としてポテンシャルを秘めているのが強化学習である[7]。この分野をまとめた論文[7]では、人間とロボットとの強化学習をInteractive Reinforcement Learningとして定義しており、新しい研究分野であると示唆している。この問題を強化学習で解いた特筆すべき研究としてQureshiらの研究[8]がある。Qureshiらの実験の様子を図1に示す。

図1 握手を求めるタイミングを映像から判断するロボット([8]より引用)
Qureshiらは人間を含む映像を入力として握手などの行動を出力する意思決定問題を深層強化学習により世界ではじめて解いている。これは限りなく人間に近い意思決定手法と言えるだろう。
そのアーキテクチャが図2である。アーキテクチャはMultimodal Deep Q-Network (MDQN)と呼ばれている。グレースケールの画像と深度画像を入力とし、握手などの行動を出力としている。アーキテクチャの構造は人間の視覚野と類似している畳み込みニューラルネットワークを用いている。このアーキテクチャが特に人間に似ているように見える。
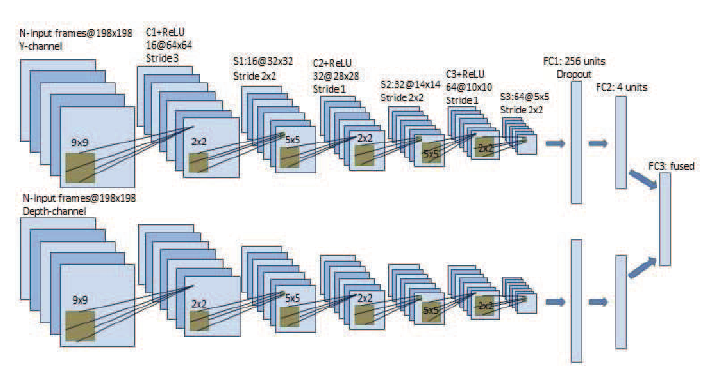
図2 Multimodal Deep Q-Networkのアーキテクチャ([8]より引用)
筆者であるAI Labの尾崎安範もこの分野を研究する者の一人である。「空気を読むロボット」というコンセプトをベースに、人間の心的状態と相関する行動に基づいて、コミュニケーションの意思決定を強化学習で学ぶロボットを開発した[10]。ロボットの様子を図3に示す。

図3 展示員のタスクを与えられた、空気を読むロボット(右側)([10]より引用)
このロボットは図2の環境にいる展示員のタスクを与えられており、トイレに行く人を邪魔せずに展示に興味がありそうな人だけに声をかけるように学習した。
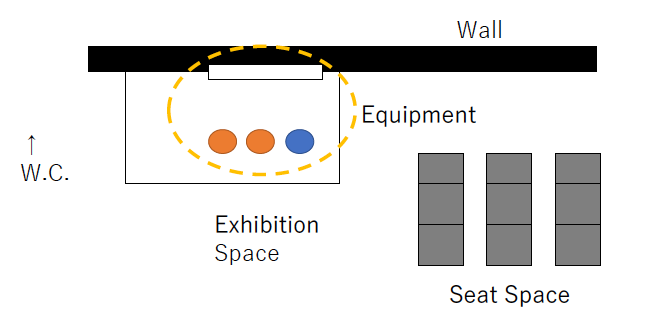
図4 展示員のタスクを与えられたロボットの実験環境([10]より引用)
筆者の研究はQureshiらとは違い、既存研究に基づいた人間の行動モデルを明示的に仮定して強化学習を行う。このため、明示的に人間の心的状態と相関する行動を判断できるようにできている。この人間の行動モデルにより、ロボット工学三原則の第一条と第二条に適する行動を自律的に獲得できるように強化学習できている。
コミュニケーションにおける人間の意思決定とロボットの意思決定との境界線とは
コミュニケーションにおける人間の意思決定とロボットの意思決定との境界線とは、対話相手の心的状態を理解した上での意思決定ができないところである。例えば、「おはよう」と人間が言ったものの元気がない様子であれば、「おはようございます。昨日は何かあったんですか?」とロボットが心配することは今の所できない。もちろん、そのルールだけを実現することは可能ではあるが、類似のルールを記述しきることは難しい。
コミュニケーションにおいて人間とロボットを区別する方法として、チューリングテスト[11]がある。チューリングテストは例えばテキストベースの雑談で人間と人工知能で見分けるものであった。実はすでにこのチューリングテストを突破する人工知能は現れており[12]、この問題は解決されたとされている。もう少し発展させて複雑な意思決定に関しても人間と変わらないことを示せれば、意思決定に関しても人間とロボットを区別できないという結論が得られるかもしれない。
やがて社会で活躍するロボットの意思決定とは
やがて社会で活躍するロボットの意思決定とは、心の理論に基づいた意思決定である。心の理論とは、”他者の心を類推し、理解する能力である”[13]。また、同義語として、”mentalizing”がある[13]。心の理論を持つロボットを実現することは容易ではない。特に非言語の領域ではプログラミング言語のような言葉にすること自体が困難であるため、研究が難しい。
心の理論の一部を機械的に説明した「心を読むシステム」をバロン・コーヘンが提案している[14]。心を読むシステムは、意図の検出器、視線方向の検出器、注意共有の仕組み、心の理論の仕組みで構成されるシステムである。ここで注目してほしいのは視線方向の検出器である。他のモジュールと違い、かなり物理的で客観的である。ロボットに実現するには容易な部類であると言えよう。ただし、その容易な視線検出も、例えば、歩行者の視線を取るのは現代の技術でも難しいというのが実情である。なお、Proof of Conceptとしての心を読むシステムを筆者が実装した例[15]がある。その様子を図5に示す。

図5 心を読むシステムを実装した対話システムの例 ([15]より引用)
筆者が実装した心を読むシステムは、以下のステップで心を読む。
- 画面上のエージェントが画面と向き合っている人間がいる。
- 画面上には表示されている物体、球と立方体2種類が表示されている。
- 人間は球か立方体、あるいは虚空をみて、「これはなんですか?」という代名詞の質問を行う。
- 画面上のエージェントは人間の視線を見てどの物体を見ているか推察し、例えば「これは球です」といった返答を行う。
これという代名詞は言語の外にある非言語情報がなければ、実現は不可能である。人間は決して言語だけでできているわけではないことがわかる。心を読むシステムをさらに発展させたシステムをロボットに実現することが今後の課題と言える。
近い将来には人間の意思決定とロボットの意思決定にコミュニケーションにおいて違いはないと言える日が来るのだろう。そのときには多くの人の命の救う意思決定が客観的にできるようになるかもしれない。
しかし、その日が来なければ、その違いが人間らしさというものになるのだろう。その人間らしさを探すのが我々認知科学を研究するもののの勤めではないかとも私は思うのだ。
参考文献
[1] ハーバートA・サイモン, 稲葉元吉, 倉井武夫共訳, “意思決定の科学”, 1979
[2] “最新 心理学事典”, 2013, https://kotobank.jp/word/意思決定-30537
[3] “エキスパートシステム”, IT用語辞典 e-Words, 2018 https://e-words.jp/w/エキスパートシステム.html
[4] “Proposal for a Regulation laying down harmonised rules on artificial intelligence”, 2021
[5] 吉本潤一郎, 伊藤真, 銅谷賢治, “《第10回》脳の意思決定機構と強化学習”, 計測と制御, 2013
[6] アイザック・アシモフ作, 小尾芙佐訳, “われはロボット〔決定版〕”, 2014
[7] Neziha Akalin et al., “Reinforcement Learning Approaches in Social Robotics”, Sensors, 2021
[8] Ahmed Hussain Qureshi, Yutaka Nakamura, Yuichiro Yoshikawa and Hiroshi Ishiguro, “Robot gains social intelligence through multimodal deep reinforcement learning”, Humanoids, 2016
[10] Yasunori Ozaki, Tatsuya Ishihara, Narimune Matsumura, Tadashi Nunobiki, “Can User-Centered Reinforcement Learning Allow a Robot to Attract Passersby without Causing Discomfort?”, IROS 2019
[11] A. M. TURING, “I.—COMPUTING MACHINERY AND INTELLIGENCE”, Mind, 1950
[12] “露スパコンに「知性」、史上初のチューリングテスト合格”. AFP通信, 2014 https://www.afpbb.com/articles/-/3017239
[13] 大神田 麻子, 板倉 昭二, “心の理論”, 2021, https://bsd.neuroinf.jp/wiki/心の理論
[14] サイモン バロン=コーエン, 長野 敬 (翻訳), 今野 義孝 (翻訳), 長畑 正道 (翻訳), “自閉症とマインド・ブラインドネス”, 2002
[15] 尾崎安範, “これ”はなんですか、コンピュータさん? -「心を読むシステム」の実装- https://qiita.com/alfredplpl/items/81d6e56a48323dadec6d
Author