Blog
ハイパーパラメーター最適化フレームワークOptunaの実装解説
AI Lab AutoMLチームの芝田です (GitHub: @c-bata)。
ハイパーパラメーター最適化は、機械学習モデルがその性能を発揮するために重要なプロセスの1つです。Pythonのハイパーパラメーター最適化ライブラリとして有名な Optuna [1] は、様々な最適化アルゴリズムに対応しつつも、使いやすく設計的にも優れたソフトウェアです。本記事ではOptunaの内部実装についてソフトウェア的な側面を中心に解説します。
Optunaの内部実装を理解するためには、主要コンポーネントの役割と全体の動作の流れを押さえる必要があります。しかしOptunaの開発は活発で、コード量も多くなり、全体の流れをコードから読み取ることは難しくなってきました。そこで今回Minitunaという小さなプログラムを用意しました。Minitunaには全部で3つのversionがあり、それぞれ100行、200行、300行とコード量が増えていきます。最終的にできあがるのは300行程度の小さなプログラムですが、実用的な枝刈りアルゴリズムを備えていて結構本格的です。
Minituna: Simplified Optuna implementation for new contributors.
https://github.com/CyberAgentAILab/minituna
Minitunaの各バージョンはそれぞれ次のステップでOptunaの設計を理解してもらうことを意図して実装しています。
- Optunaの主要コンポーネントとそれらの呼び出しの流れを理解する
- categoricalやinteger、loguniformの扱い方を理解する
- 枝刈りのAPIとMedian stopping ruleのアルゴリズムを理解する
Minitunaを写経して設計を理解できればOptunaのコードを読み進めることはそれほど難しくないでしょう。本記事ではMinitunaのコードから簡単に読み取れることはあえて扱いませんが、その代わりMinitunaのコードリーディングや写経を進める際に手がかりになるヒントやOptunaとの違いなどを補足して解説していきます。
minituna_v1: Trial, Study, Sampler, Storageの役割と流れ
Minituna v1は100行程度のプログラムです。非常に小さなプログラムですが、主要なコンポーネントはすでに実装されており、次のようなプログラムが動作します。ちなみに今回用意したexampleはすべてOptunaとの互換性があり、import文を import optuna as minituna のように切り替えても問題なく動作します。
|
1 2 3 4 5 6 7 8 9 10 11 |
import minituna_v1 as minituna def objective(trial: minituna.Trial) -> float: x = trial.suggest_uniform("x", 0, 10) y = trial.suggest_uniform("y", 0, 10) return (x - 3) ** 2 + (y - 5) ** 2 if __name__ == "__main__": study = minituna.create_study() study.optimize(objective, 10) print("Best trial:", study.best_trial) |
Optunaではこのように目的関数を定義します。目的関数はTrialオブジェクトを受け取り、評価値を返す関数です。この例では目的関数を10回呼び出し、その中で得られた最も良い評価値(ここでは最小化問題を考えます)とそのパラメーターを出力します。
それではminituna_v1のコードリーディングを進めてみてください。minituna_v1には5つのクラスが定義されています。これらはOptunaのコードにも頻繁に登場する重要なコンポーネントです。これらの役割と呼び出しの流れをコードから確認してみましょう。
- Study: 1つの最適化タスクに関する一連の情報を管理するコンポーネント
ある最適化タスクに対して、どのアルゴリズムを使うのか(Sampler)、どこに試行結果を保存するのか(Storage)といった情報をすべてこのStudyコンポーネントで管理します。 create_study() 関数の引数で指定します。 - Trial: 各試行(Trial)に対応するコンポーネント
目的関数はこのTrialオブジェクトが提供するAPIを経由してOptunaからパラメーターをサンプルしたり、中間評価値を報告して枝刈りを行います。 - Storage: 最適化の試行結果を保存するコンポーネント
このコンポーネントのおかげで、OptunaはRDB storageなどにも対応でき、試行結果の永続化や分散最適化が可能になっています。 - FrozenTrial: Storageレイヤー上での各試行(Trial)の表現
各試行(Trial)において目的関数の評価に使ったパラメーターや評価値を保持するコンポーネントです。たとえばRDB storageなどを利用する際も、SQLでDBから取り出した情報をこのFrozenTrialオブジェクトに詰め込みます。 - Sampler: 次に評価するパラメーターを選択するアルゴリズムを実装するコンポーネント
どのパラメーターを評価すればより良い評価値を得られるかを求めるアルゴリズムを実装するコンポーネントです。ベイズ最適化や進化戦略アルゴリズムにおけるハイパーパラメータのサンプリングはこのSamplerコンポーネントに定義します。Minitunaでは説明を簡単にするためRandom samplingのみ実装しています。Optunaがサポートしているベイズ最適化や進化戦略のアルゴリズムの詳細については、本記事で詳しく扱いません。弊社AI Lab研究員 野村のPyCon JP 2019の発表 機械学習におけるハイパーパラメータ最適化の理論と実践をご覧ください。
minituna_v2: CategoricalやInteger、LogUniformの扱い方
minituna_v2では suggest_uniform() (一様分布からの実数パラメーターのsample)に加えて次のSuggest APIをサポートしています。
- suggest_categorical(name, choices=[…]) : 質的パラメーターをサンプルする
- suggest_int(name, low, high) : 整数パラメーターをサンプルする
- suggest_loguniform(name, low, high) : 対数スケールの空間から実数パラメーターをサンプルする
このおかげで、次のような目的関数も最適化できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def objective(trial): iris = sklearn.datasets.load_iris() x, y = iris.data, iris.target classifier_name = trial.suggest_categorical("classifier", ["SVC", "RandomForest"]) if classifier_name == "SVC": svc_c = trial.suggest_loguniform("svc_c", 1e-10, 1e10) classifier_obj = sklearn.svm.SVC(C=svc_c, gamma="auto") else: rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32) classifier_obj = sklearn.ensemble.RandomForestClassifier( max_depth=rf_max_depth, n_estimators=10 ) score = sklearn.model_selection.cross_val_score( classifier_obj, x, y, n_jobs=-1, cv=3 ) accuracy = score.mean() return 1 - accuracy # 最小化問題に変えています |
minituna_v2 のコードを理解するうえで押さえておくべきポイントは、すべてのパラメーターがStorage上ではfloatで表現される点です。先程の例において、質的パラメーターは “SVC” や “RandomForest” のように文字列となりますが、storage上ではこれらもfloatで表現されます。そのために次の抽象基底クラスを導入します。
|
1 2 3 4 5 6 7 8 |
class BaseDistribution(abc.ABC): @abc.abstractmethod def to_internal_repr(self, external_repr: Any) -> float: ... @abc.abstractmethod def to_external_repr(self, internal_repr: float) -> Any: ... |
各パラメーターはinternal_reprとexternal_reprという2つの表現があります。internal_reprはストレージ上でのパラメーター表現でありfloat値です。external_reprは実際に目的関数で扱う表現なので文字列だったり整数値だったりします。実際に動かしてみるのが理解に繋がるでしょう。
|
1 2 3 4 5 6 7 8 9 10 |
>>> import minituna_v2 as minituna >>> distribution = minituna.CategoricalDistribution(choices=["SVC", "RandomForest"]) >>> distribution.to_internal_repr("SVC") 0 >>> distribution.to_internal_repr("RandomForest") 1 >>> distribution.to_external_repr(0) 'SVC' >>> distribution.to_external_repr(1) 'RandomForest' |
internal_repr と external_repr の変換にはdistributionオブジェクトが必要です。そのため、distributionオブジェクトはstorageにも保存します。FrozenTrialにdistributionsフィールドが追加されているのはそれが理由です。
MinitunaとOptunaはSuggest APIに関していくつか異なる点があります。
- OptunaにはDiscreteUniformDistributionやIntLogUniformDistributionも存在します。DiscreteUniformDistributionはIntUniformDistributionと離散化の幅が異なるだけで本質的に同じです。IntLogUniformDistributionはLogUniformDistributionと同じような対応をIntUniformDistributionに加えただけです。そのため、minituna_v2を写経すれば簡単に読みすすめることができます。
- Optunaには、 suggest_float(name, low, high, step=None, log=False) というAPIが用意されています。これは suggest_uniform(low, high) や suggest_loguniform(low, high) のuniformという単語が少し分かりにくいことや、suggest_intとの一貫性を考慮して追加されました。suggest_floatは無事に導入されたので、suggest_uniformやsuggest_loguniform、suggest_discrerte_uniformはDeprecateする選択肢もあると思いますが、その辺りの議論は止まっています。
- DistributionをRDBStorageやRedisStorageに保存する際には何らかの形式にserializeする必要があり、OptunaではJSONにserializeして格納しています。つまりCategoricalパラメーターとして選択できる型は、 CategoricalChoiceType = Union[None, bool, int, float, str] のようにJSON serialize可能なオブジェクトに限定されることを意味しています。
Storageレイヤーをしっかり理解する
minituna_v2まで読み進めた方は、Optunaのコードリーディングに移るのもいいでしょう。minituna_v3の解説に入る前に、Storageレイヤーの補足解説をはさんでおきます。
自分がOptunaのコードリーディングをはじめたとき、最初にしっかり理解を深めたのはStorageレイヤーでした。どういう情報がストレージに保存されているかを整理すれば、各機能を実装するためにOptunaがどういうことをしないといけないのか自然と想像がついてくるからです。MinitunaとOptunaの設計の違いも、Storageレイヤーのコードを読めばだいたい把握できるでしょう。Storargeレイヤーの理解には、RDBStorageのSQLAlchemy モデル定義を確認するのがおすすめです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class StudyModel(BaseModel): __tablename__ = "studies" study_id = Column(Integer, primary_key=True) study_name = Column(String(MAX_INDEXED_STRING_LENGTH), ...) direction = Column(Enum(StudyDirection), nullable=False) class TrialModel(BaseModel): __tablename__ = "trials" trial_id = Column(Integer, primary_key=True) number = Column(Integer) study_id = Column(Integer, ForeignKey("studies.study_id")) state = Column(Enum(TrialState), nullable=False) value = Column(Float) datetime_start = Column(DateTime, default=datetime.now) datetime_complete = Column(DateTime) class TrialParamModel(BaseModel): __tablename__ = "trial_params" __table_args__ = (UniqueConstraint("trial_id", "param_name"),) param_id = Column(Integer, primary_key=True) trial_id = Column(Integer, ForeignKey("trials.trial_id")) param_name = Column(String(MAX_INDEXED_STRING_LENGTH)) param_value = Column(Float) distribution_json = Column(String(MAX_STRING_LENGTH)) |
Storageレイヤーのコードを読む際の、補足事項は次のとおりです。
- MinitunaのStorageはコードをシンプルにするため、1つのStudyに関する情報しか保持できませんが、実際のOptunaのコードは複数のStudyに対応しています。
- 複数のStudyに対応しているため、TrialModelのtrial_idフィールドは必ずしもStudy内で単調に増加するフィールドではありません。アルゴリズムを実装するうえで、Study内で 1, 2, 3, … と単調に増加する識別子があると便利なので、Optunaには number フィールドが導入されました。
- TrialStateには、 PRUNED や WAITING という状態があります。前者はminituna_v3で解説する枝刈り機能、後者は
enqueue_trial()の機能を実装するために追加されました。
minituna_v3: Median stopping ruleによる枝刈り
minituna_v3は300行程度のプログラムです。枝刈り(早期停止)アルゴリズムをサポートしています。枝刈りは必ずしもOptunaの利用者全員が使う機能ではないので、興味のある方だけ取り組むとよいでしょう。枝刈り機能はつぎのように利用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def objective(trial): clf = MLPClassifier( hidden_layer_sizes=tuple( [trial.suggest_int("n_units_l{}".format(i), 32, 64) for i in range(3)] ), learning_rate_init=trial.suggest_loguniform("lr_init", 1e-5, 1e-1), ) for step in range(100): clf.partial_fit(x_train, y_train, classes=classes) accuracy = clf.score(x_valid, y_valid) error = 1 - accuracy # 中間評価値を報告. trial.report(error, step) # 早期停止すべき状態なら TrialPruned 例外を送出. if trial.should_prune(): raise minituna.TrialPruned() return error |
枝刈りを利用する際に必要なAPIは2つだけです。
- trial.report(value, step) で中間評価値をStorageに保存
- trial.should_prune() が True なら、TrialPrued() 例外を送出し、学習を停止
![Optuna Trial APIの設計 (Optunaの論文 [1] Figure.6 より参照)](https://cyberagent.ai/wp-content/uploads//2020/09/suggest-pruner-api.jpg)
Optuna Trial APIの設計 (Optunaの論文 [1] Figure.6 より参照)
このAPIからわかるように現状Optunaがサポートしている枝刈りアルゴリズムは、すべて中間評価値の情報をもとに枝刈りの判断を行います。MinitunaはMedian stopping rule [2] というアルゴリズムを実装していますが、幸いにもOptunaがサポートしている枝刈りのアルゴリズムは、どれもそこまで複雑なものではありません。
これらのアルゴリズムはすべて、中間評価値が低ければ、最終評価値もそんなによくないだろうという経験的な知見をもとに途中で学習を停止させます。このあと紹介するMedian stopping ruleの他に、OptunaではSuccessive Halving [3, 4] やHyperband[5]といったアルゴリズムもサポートしていますが、基本的な考え方は大きくは変わりません。弊社AI Lab所属の研究員野村のPyCon JPでの発表 「機械学習におけるハイパーパラメータ最適化の理論と実践」で枝刈りのアルゴリズムも解説されているので気になる方はチェックしてみてください。
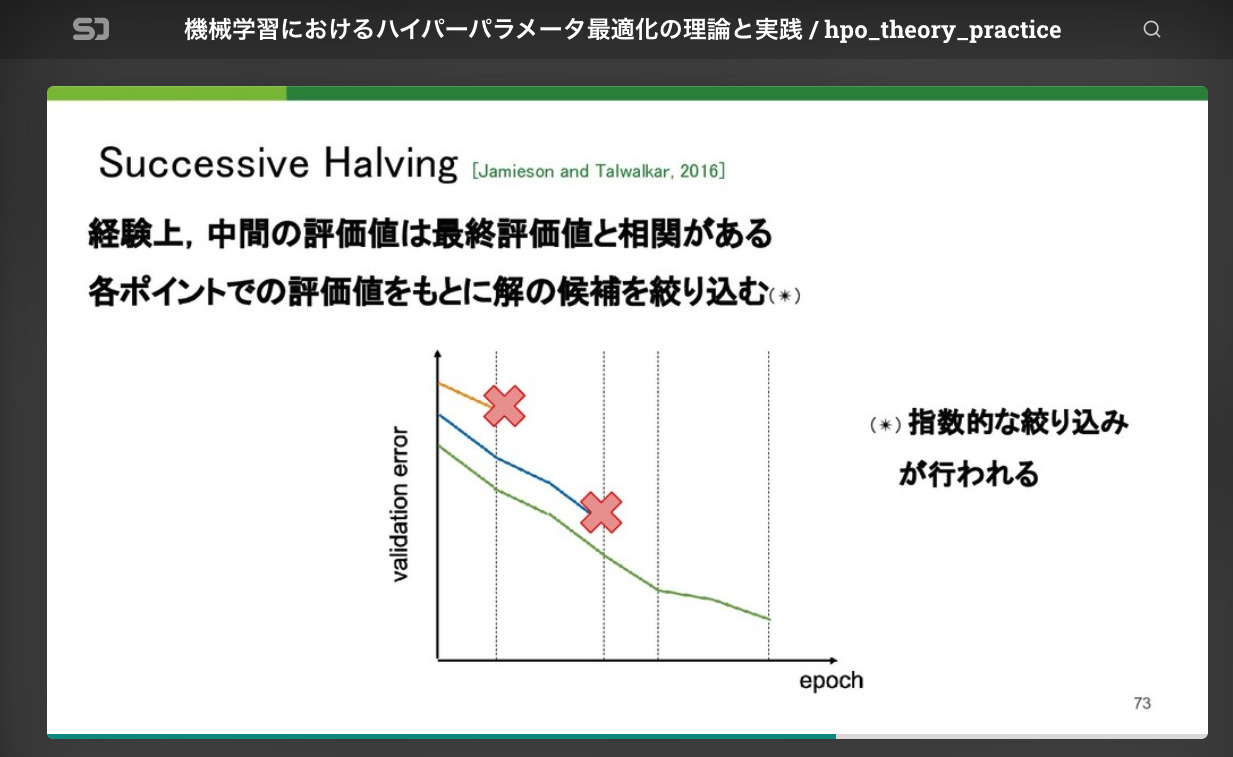
AI Lab 研究員 野村のPyCon JP 2019発表資料より抜粋
https://youtu.be/F1GGPQlra-E?t=1617
Median stopping ruleでは基本的に各stepで下位半分(過去のtrialの中間評価値のMedian値より悪いもの)を枝刈りします。Median stopping ruleの挙動を図示すると次のようになります。コードもシンプルなので次の図と合わせて読んでみるとMedian stopping ruleアルゴリズムの詳細がよくわかるでしょう。
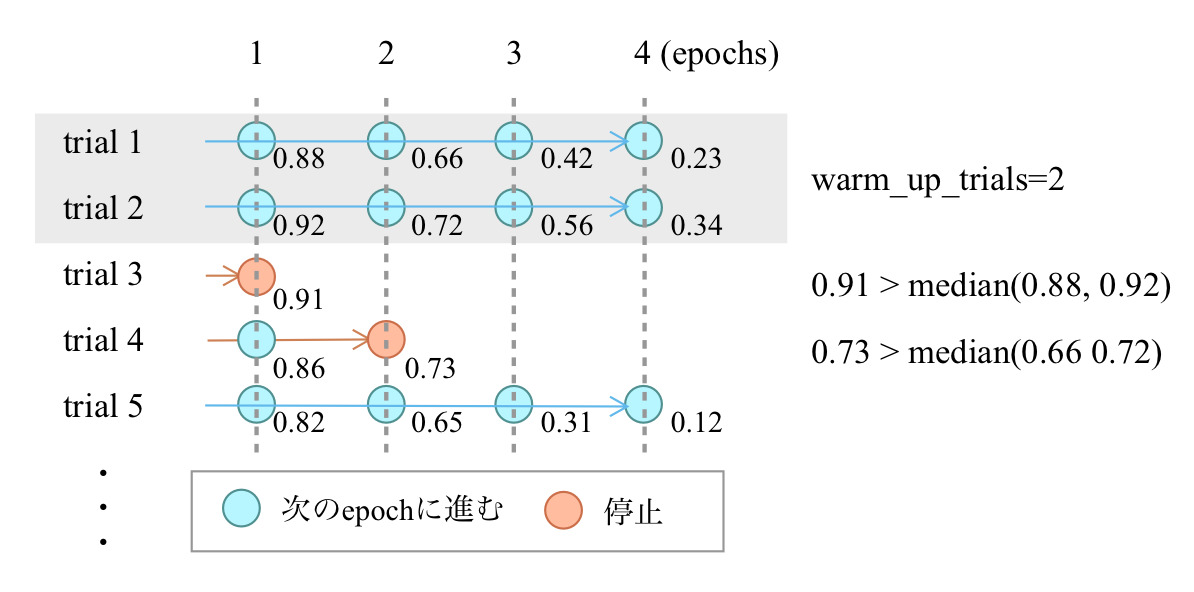
Median stopping ruleの挙動
OptunaのSuccessiveHalvingやHyperbandの実装を読んでみたい方には、1つ注意点があります。Optunaは特定のTrialの学習を中断/再開できるような設計にはなっていないため、アルゴリズムに少し改変を加えているため、論文で解説されているアルゴリズムとは異なった挙動をします。Optunaが実装しているSuccessive HalvingについてはOptunaの論文 [1] のAlgorithm 1、Hyperbandについては実装者のcrcrparさんによる解説ブログ「How We Implement Hyperband in Optuna」を参照してください。
Prunerの設計に関する課題感についても触れておきます。minitunaのコードからわかるようにOptunaではPrunerとSamplerのinterfaceは明確に分離されています。そのおかげでOptunaのコードは見通しがよく、SamplerとPrunerを自由に切り替えて組み合わせることができます。これは大きなメリットです。
その一方でPrunerとSamplerが密に連携する必要があるアルゴリズムもあり、それらは今の設計では実装できません。Hyperbandの実装においても実は裏側で少しトリッキーな実装を加えることでPrunerとSamplerを連携させて動かしています。PrunerやSamplerのインターフェイスには未だ議論の余地があります。もしこのあたりのコードを読んだうえで、何かアイデアがある方は提案をいただけると嬉しいです。
Define-by-RunインターフェイスにおけるRelative Samplingの仕組み
Minitunaでは実装ボリュームの都合上、解説することができなかったRelative Samplingについても触れておきます。このあたりはDefine-by-Runインターフェイスを採用したOptuna特有の仕組みです。SkoptSampler (GP-BO)やCmaEsSamplerのようにパラメーター間の相互作用を考慮できる最適化アルゴリズムを実装する場合には、Relative Samplingの理解が必要になります。ベイズ最適化や進化戦略アルゴリズムの研究をされている方は、Relative Samplingまで理解すれば、独自のSamplerをOptuna上で実装できるでしょう。
MinitunaのSamplerインターフェイスの設計は、Optuna v0.12.0時代のインターフェイスとほぼ同じものです。しかしOptuna v0.13.0以降のインターフェイスは、これらと異なります。次の2つのSamplerインターフェイスを見比べるとその違いがわかります。
- v0.12.0: https://github.com/optuna/optuna/blob/v0.12.0/optuna/samplers/base.py
- v2.0.0: https://github.com/optuna/optuna/blob/v2.0.0/optuna/samplers/_base.py
Relative Samplingを理解するために、いくつかの目的関数を例にそれぞれの探索空間がどのようになっているか考えてみましょう。
|
1 2 3 4 |
def objective(trial): x = trial.suggest_uniform("x", -100, 100) y = trial.suggest_categorical("y", [-1, 0, 1]) return x ** 2 + y |
この目的関数の探索空間は常に↓のようになります。
|
1 2 3 4 |
{ 'x': UniformDistribution(low=-100, high=100), 'y': CategoricalDistribution(choices=[-1, 0, 1]) } |
では次の目的関数の探索空間はどうでしょうか?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def objective(trial): x, y = ... classifier_name = trial.suggest_categorical("classifier", ["SVC", "RandomForest"]) if classifier_name == "SVC": svc_c = trial.suggest_float("svc_c", 1e-10, 1e10, log=True) classifier_obj = sklearn.svm.SVC(...") else: rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True) classifier_obj = sklearn.ensemble.RandomForestClassifier(...) accuracy = ... return accuracy |
Define-by-Runインターフェイスでは、実行時に探索空間が決定します。この例では、探索空間にif文による条件分岐が存在するため、探索空間は1つではありません。次の2つの探索空間がコンテキストに応じて切り替わります。
|
1 2 3 4 5 |
# SVC { 'classifier': CategoricalDistribution(choices=["SVC", "RandomForest"), 'svc_c': LogUniformDistribution(low=1e-10, high=1e10), } |
|
1 2 3 4 5 |
# RandomForest { 'classifier': CategoricalDistribution(choices=["SVC", "RandomForest"), 'rf_max_depth': IntUniformDistribution(low=2, high=32), } |
そこでCmaEsSamplerやSkoptSamplerはすべての探索空間で共通して登場しているものを、 Sampler.infer_relative_search_space(study, trial) メソッドで取り出し、 Sampler.sample_relative(study, trial, search_space) の第3引数に渡します。つまり上の例では classifier パラメーターのみがRelative Search Spaceとして扱われます。このRelative Search SpaceからのSampleにのみGP-BOやCMA-ESを使っていて、これをRelative Samplingと呼んでいます。一連の流れを図にしたものがこちらです。
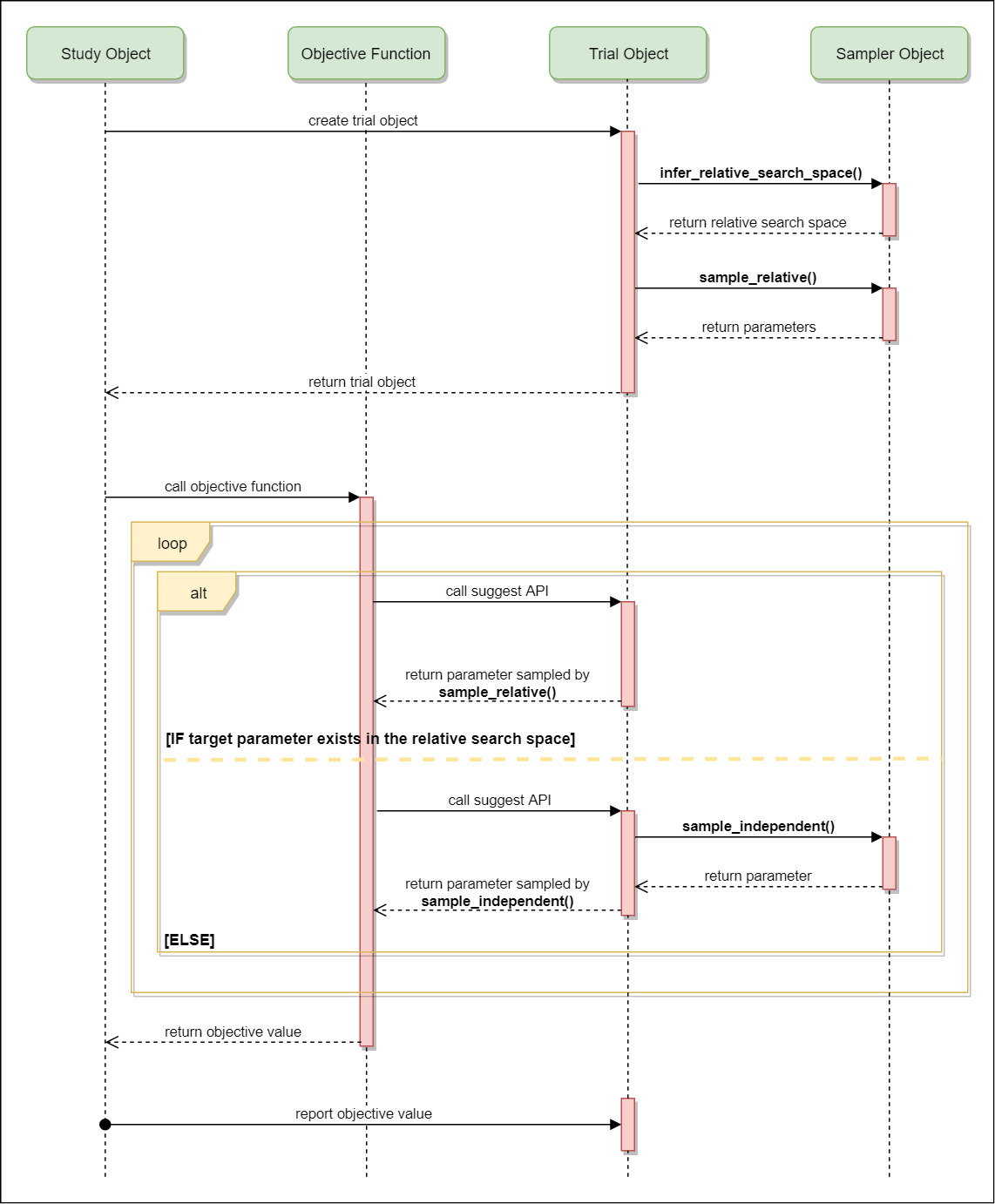
Samplerの呼び出しフロー (公式ドキュメンテーションより参照)
svc_c や rf_max_depth のようにRelative Search Spaceに含まれなかったパラメーターは、RandomSamplerやTPESamplerのように変数間の依存関係を考慮しない手法を実装したSamplerにfallbackします。
まとめ
本記事ではMinitunaの紹介とMinituna/Optunaのコードを読みすすめる上での補足解説を行いました。Minituna v2まで写経し、全体の流れがつかめた方であればOptunaのコードは読めると思います。興味のあるコンポーネントから読み進めてみてください。Optuna開発チームのみなさんは非常にsupportiveで、PRも丁寧にレビューしてくれます。この記事をきっかけにぜひOptunaの開発に参加してみてください。
参考文献
- T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama: Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 2623-2631, 2019.
- D. Golovin, B. Sonik, S. Moitra, G. Kochanski, J. Karro, and D.Sculley: Google Vizier: A Service for Black-Box Optimization. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1487-1495, 2017.
- K. Jamieson and A.Talwalkar: Non-stochastic Best Arm Identification and Hyperparameter Optimization. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (AISTATS), PMLR 51:240-248, 2016.
- L. Li, K. Jamieson, A. Rostamizadeh, E. Gonina, M. Hardt, B. Recht, and A. Talwalkar: A System for Massively Parallel Hyperparameter Tuning. arXiv preprint arXiv:1810.05934, 2018.
- L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh and A. Talwalkar: Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. Journal of Machine Learning Research, 18, pp. 1-52, 2017.
謝辞
本記事はOptunaの開発チームのみなさんやスキルアップAI株式会社の斉藤さんにレビューしていただきました。この場でお礼をさせていただきます。ありがとうございました。
Author