Blog
EMNLP’20 WorkshopのNegative Result論文リストを読む
AI Labの大谷です。
先日、Workshop on Insights from Negative Results in NLPというワークショップのサイトで面白いnegative resultの論文リストがあったので2つ簡単に紹介します。
Negative resultの定義については、ここの解説がとりあえずカバーしています。例えば「Xは問題Yを解決していない」、「データセットAには欠点Bがある」など、否定的な結論を明らかにする試みです。
Metric Learning Reality Check
これはmetric learningの実験方法を整備し、主要な手法を再評価した論文です。arXivで公表されたときにSNSで話題になっていたので、いくつかの紹介記事も出ています。
metric learningはデータをある空間にマッピングする方法を学習する方法です。マッピング先の空間では、似ているデータはなるべく近くに、似ていないデータは離れた場所に配置するよう学習します。
ざっくりとしたmetric learningの例。AとBは似ているので、空間上でお互いの近くに、BとCはそれほど似てないので少し離れたところに位置するようマッピングを学習する。データ間の類似度を簡単に出せるのでzero-shot識別や検索に便利。 (A) Photo by Minh Pham on Unsplash (B) Photo by Vicky Ng on Unsplash (C)Photo by Colin Horn on Unsplash
この論文ではここ10数年の間に発表された論文を調査し、それらの手法の比較における問題点を指摘しています。新しい手法を提案する論文では、共通のベンチマークにおいて既存手法よりも高性能であることを示すことが重視されます。多くの論文が古典的な手法に比べ大幅な性能向上を主張していますが、実際に性能は正しく比較されているのだろうか?というのがこの論文の主題です。
まず結論をまとめると、出版されている比較結果は問題のある実験設定によるものであり、フェアな比較ができていないということを主張しています。さらに、最近の知見に基づいた実験設定で評価をやり直すと、多くの論文で性能に大きな差は出なかったということが報告されています。ここ10数年発表されてきた手法の発展は表面的なものであるということで、なかなか驚きの結果です。
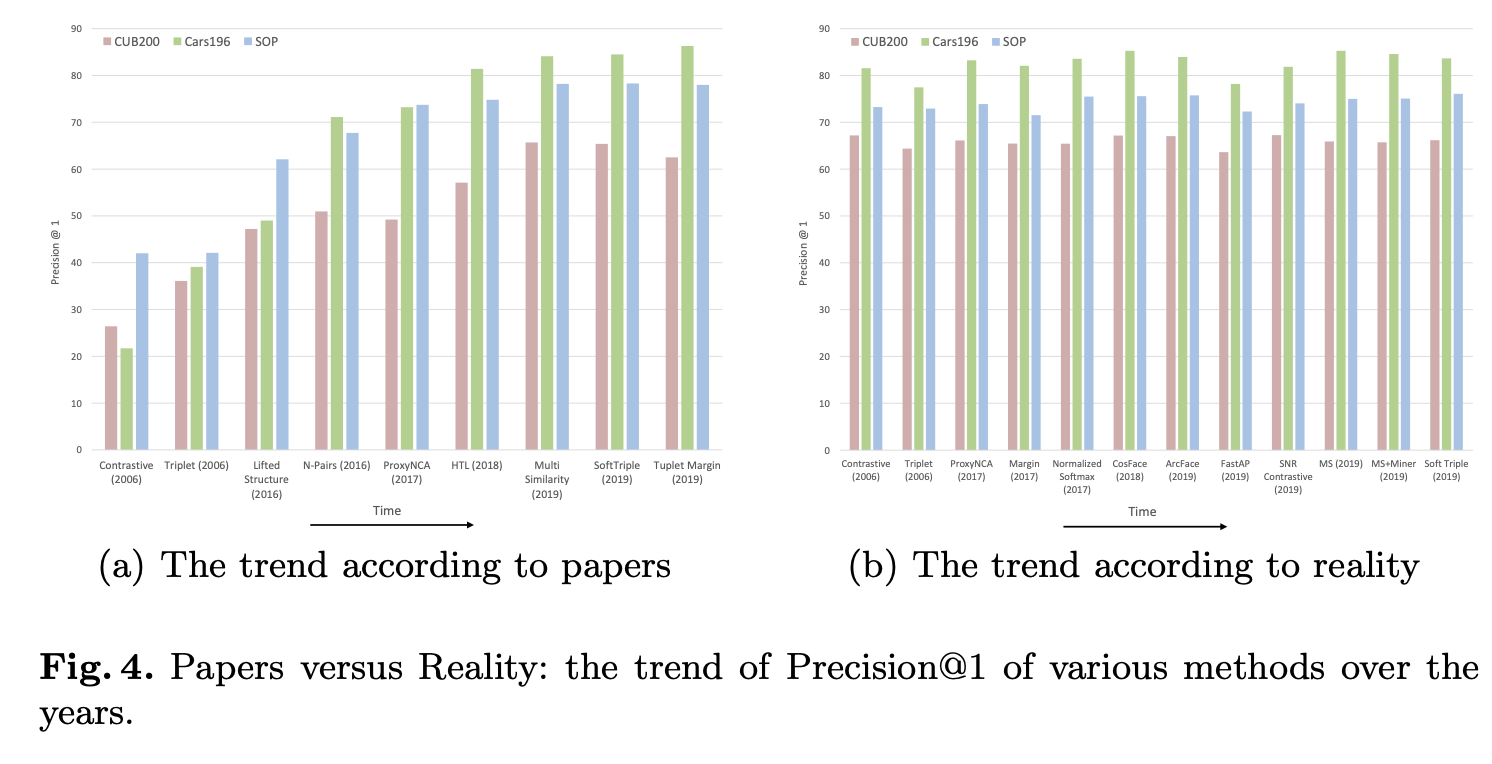
(論文より引用)申告されているスコア(左)によると、年々改良されているように見えますが、実験設定を揃えて再評価(右)すると各手法に大差がなかったことを示しています。
実験の誤った慣習として、異なるモデルアーキテクチャ、前処理、最適化手法を使った結果を単純に比較している点をあげています。ディープラーニングライブラリの充実もあり、この数年でdata augmentationやbatch normalizationをはじめ、より洗練された学習テクニックが広く使われるようになりました。最適化手法もSGDをはじめAdam、RMSProp、さらにそれぞれの発展系など、容易に試せる選択肢が増えています。当然、10数年前とはこれらのテクニックを含む実験設定の環境が大きく変わっているので、論文に記載されているスコアだけでは古い手法と新しい手法を比較することはできません。この論文ではフェアな比較をするために、これらの細かいテクニックを統一した条件で各手法を再評価しています。この比較実験のためにmetric learningで採用されている最近のdata augmentationのやり方など、学習テクニックを網羅的にまとめているので、現状のベストプラクティスの調査としても便利です。
もう一つの問題として、test data feedbackがあげられています。具体的には、学習時にtest setにおけるスコアのログをとり、最も高いスコアを報告する慣習がみられると指摘しています。これは評価用データを使ってハイパーパラメータの一つを決めており、機械学習プロジェクトの初歩的なタブーです。初歩的なタブーではあるのですが、この悪習はmetric learningに限らず、トップカンファレンスに採択された論文の実験コードで痕跡をみることもあります。またハイパーパラメータの調整にもtest setが使われてることがあるようです。よくないですね。
Adversarial Examples for Evaluating Reading Comprehension Systems
こちらは文書理解タスクで複雑なモデルの実際の振る舞いを実験的に調査した2017年の論文です。ここで調査されているのはSQuADというベンチマークです。SQuADは以下のような短い文章に関する質問と回答のデータセットです。
His translation of the Bible into the vernacular (instead of Latin) made it more accessible, which had a tremendous impact on the church and German culture. It fostered the development of a standard version of the German language, added several principles to the art of translation, and influenced the writing of an English translation, the Tyndale Bible. His hymns influenced the development of singing in churches. His marriage to Katharina von Bora set a model for the practice of clerical marriage, allowing Protestant clergy to marry.
Q. What version of the English translation of the Bible did Luther’s translation affect?
A. Tyndale Bible
文書理解の分野ではこのベンチマークで自然言語の文章を理解し、質問に答える能力を測定していました。2017年時点でディープなモデルを使うことで人間のスコアに近い性能が達成されています。
この論文では文章中に回答と関係ない文を追加することで容易にモデルを騙すことができることを示しています。またその結果から、高い性能を達成しているモデルであっても、本当に文章の意味理解を学習しているわけではなく、回答が文章中に出現するパターンを使っているらしいということを実験的に示しました。
以下の太字の部分がこの論文で提案されたモデルを騙すための文です。質問文中に含まれる単語を使ったダミー文でモデルをひっかけようとしています。
Article:Super Bowl 50Paragraph:“Peyton Manning became the first quarterback ever to lead two different teams to multiple SuperBowls. He is also the oldest quarterback ever to playin a Super Bowl at age 39. The past record was heldby John Elway, who led the Broncos to victory in SuperBowl XXXIII at age 38 and is currently Denver’s Execu-tive Vice President of Football Operations and GeneralManager. Quarterback Jeff Dean had jersey number 37in Champ Bowl XXXIV.”
Question:“What is the name of the quarterback whowas 38 in Super Bowl XXXIII?”
Original Prediction:John Elway
Prediction under adversary:Jeff Dean
SQuADでは回答が出現する位置に関して、特徴的なパターンがあることが指摘されていました。質問文に含まれるキーワードに近く、質問のタイプ(what, when, who, etc.)に対応するカテゴリの語は回答に対応する部分である可能性が高いという傾向があるようです。今回のダミー文はそのような単純なパターンを学習しがちなモデルとデータセットの隙をつくことに成功しているようです。ディープなモデルが一体何を学習しているのか理解することは困難ですが、シンプルなテストでモデルの問題を検証している点が面白い研究です。
SQuADベンチマークはその後さらに改良され、SQuAD2.0がリリースされました。
https://rajpurkar.github.io/SQuAD-explorer/
今年に入ってからも多数のモデルのベンチマークに使われているようですが、既にtransformer系モデルが人間のスコアを追い抜いていることが確認できます。しかしこのベンチマークの攻略を持って文章理解の問題が解決されたとするのはあまりにも楽観的でしょう。SQuAD2.0の役割も再度検討する必要がありそうです。
最後に
上記ワークショップのトップページでも言及されていますが、negative resultの論文が学会で採択されることはなかなか難しいと言われています。negative result論文は問題を解決するわけではないのですが、当該分野にとっては重要な知見です。今回はそのような研究のプレゼンス向上に多少なりとも貢献できればと思いブログに書いてみました。
今回紹介したワークショップだけでなく、コンピュータビジョン分野ではCVPR’17でnegative resultのワークショップが開かれています。プレゼン資料は公開されており、今見返しても面白い内容なのでこちらもおすすめです。
Author