Blog
Coling 2016参加レポート – その4
こんにちは。AI Labの山本です。
Coling 2016の本会議3日目と4日目のレポートをお送りします。
3日目と4日目は風邪を引いてしまってすっかりダウン気味でした。
面白かった発表
papago: A Machine Translation Service with Word Sense Disambiguation and Currency Conversion (pdf)
Naverが公開しているアプリ papago の紹介です。
これはモバイル端末向けの多言語機械翻訳です。対応言語は英語、日本語、中国語、韓国語です。
この発表では主に2つの新しい機能について紹介していました。ユーザフィードバックに基づく語義曖昧性解消と通貨換算機能です。
まず、ユーザフィードバックに基づく語義曖昧性解消機能です。これは同形異義語(同綴異義語)が含んでいる文を翻訳するときに「この言葉、この意味でいいのか?」と絵を使って問い返し、ユーザのフィードバックがあればそれに基づいて再翻訳するというものです(下図)。この機能は韓国語-英語、韓国語-中国語、韓国語-日本語でのみ提供しています。
日本語でいうなら「自決しました」という文を翻訳するときに ![]() or
or ![]() ? みたいな問いかけがある感じです。ちなみに実装としては辞書ベースのマッチングを行っているようです。
? みたいな問いかけがある感じです。ちなみに実装としては辞書ベースのマッチングを行っているようです。
次に通貨換算機能です。これは翻訳に金額表記がある場合にそれを現在の為替レートの基づいて通貨換算して表示するものです (下図)。私も papago を入れて英語から日本語の翻訳で通貨換算やってみたのですが、見慣れた日本円で表示されるのが予想以上に便利だと感じました。

ちなみに papago はAndroid版もiOS版もあります。個人的には会話例文集がオススメです。
FastHybrid: A Hybrid Model for Efficient Answer Selection (pdf)
質問応答システムでは、質問文から回答文を探す必要があります。
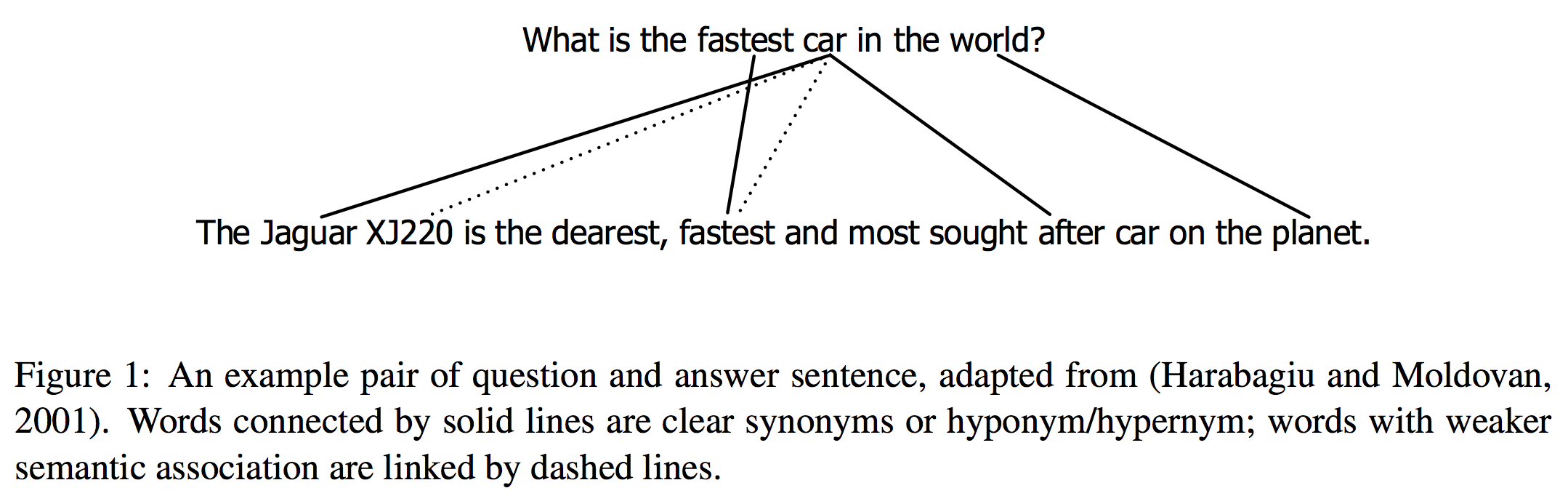
ちょっとわかりにくいので例を以下に示します。
これは Question Answering Using Enhanced Lexical Semantic Models (pdf) からの引用です。上の文が質問、下の文が回答になっています。
この例のように、質問文に対する回答が語彙的に類似している場合、ベクトル空間モデルを用いて質問文に類似する回答文を回答文集合から探し出すというのが最も単純な実装となります。
先ほどベクトル空間モデルについて単純な実装と書いたのは、最近ではもうちょっと工夫を凝らして、ディープラーニングを用いた教師あり学習が使われるようになってきたからです。
実際にそのようなやり方で優れた結果を出していたりします。
とは言えども大抵の場合、パラメータやハイパーパラメータがたくさんあったりで大規模なデータセットでは問題になったりします。
この発表ではFastHybridという教師なし学習のやり方を提案しました。
この方法で教師ありのディープラーニング手法と同等の正解率を出したそうです。
では具体的にFastHybridが何をやっているのかを簡単に見ていきましょう。
以降の図はFastHybridのPaperからの引用です。
全体の流れは以下のようになります。
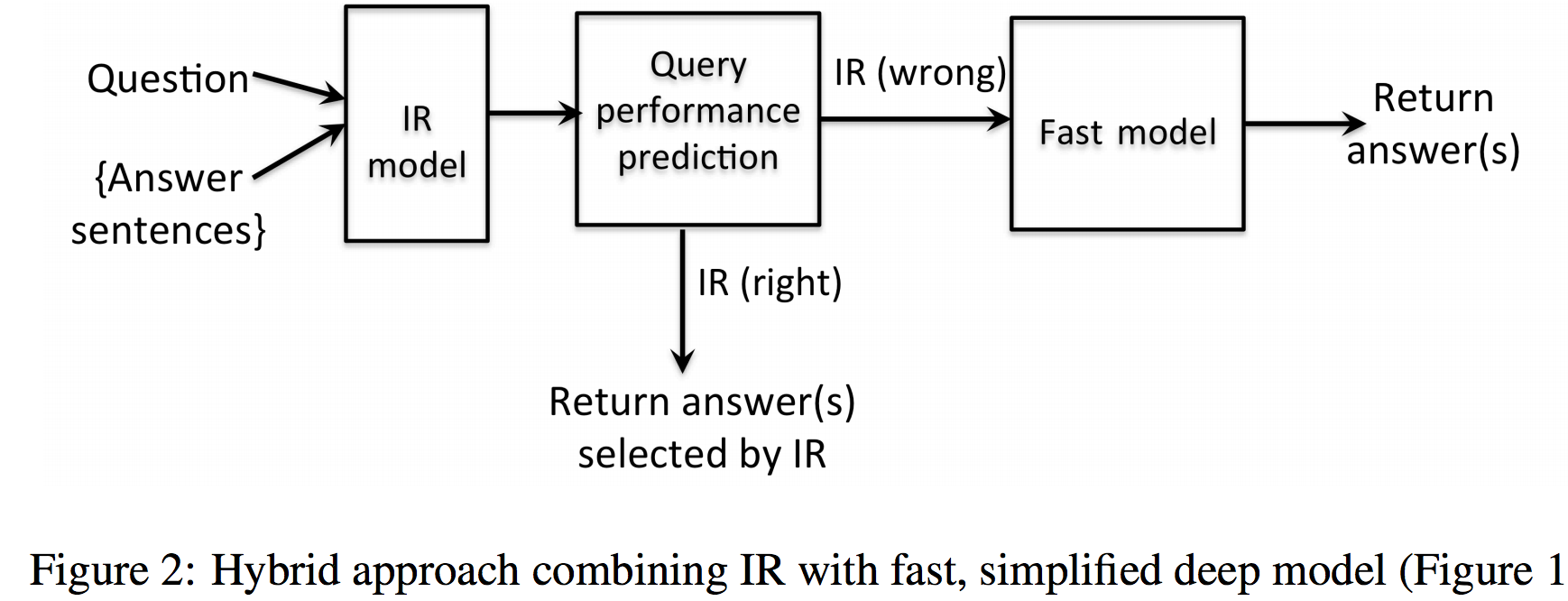
まず最初に普通の情報検索(IR; Information Retrieveal)を行います。
そして、検索結果が妥当なものであるかをQuery Performance Prediction (pdf)という手法で評価します。
これで正しいであろうと評価された場合は情報結果の結果をそのまま返します。
正しくないと評価された場合は、Fast modelという別の方法を使って回答を探します。
これは質問と回答の語彙を一旦word2vecなどを使って埋め込みベクトルにした上で、それらのベクトルにプーリング操作を加えてコサイン類似度を求めるというものです(下図)。
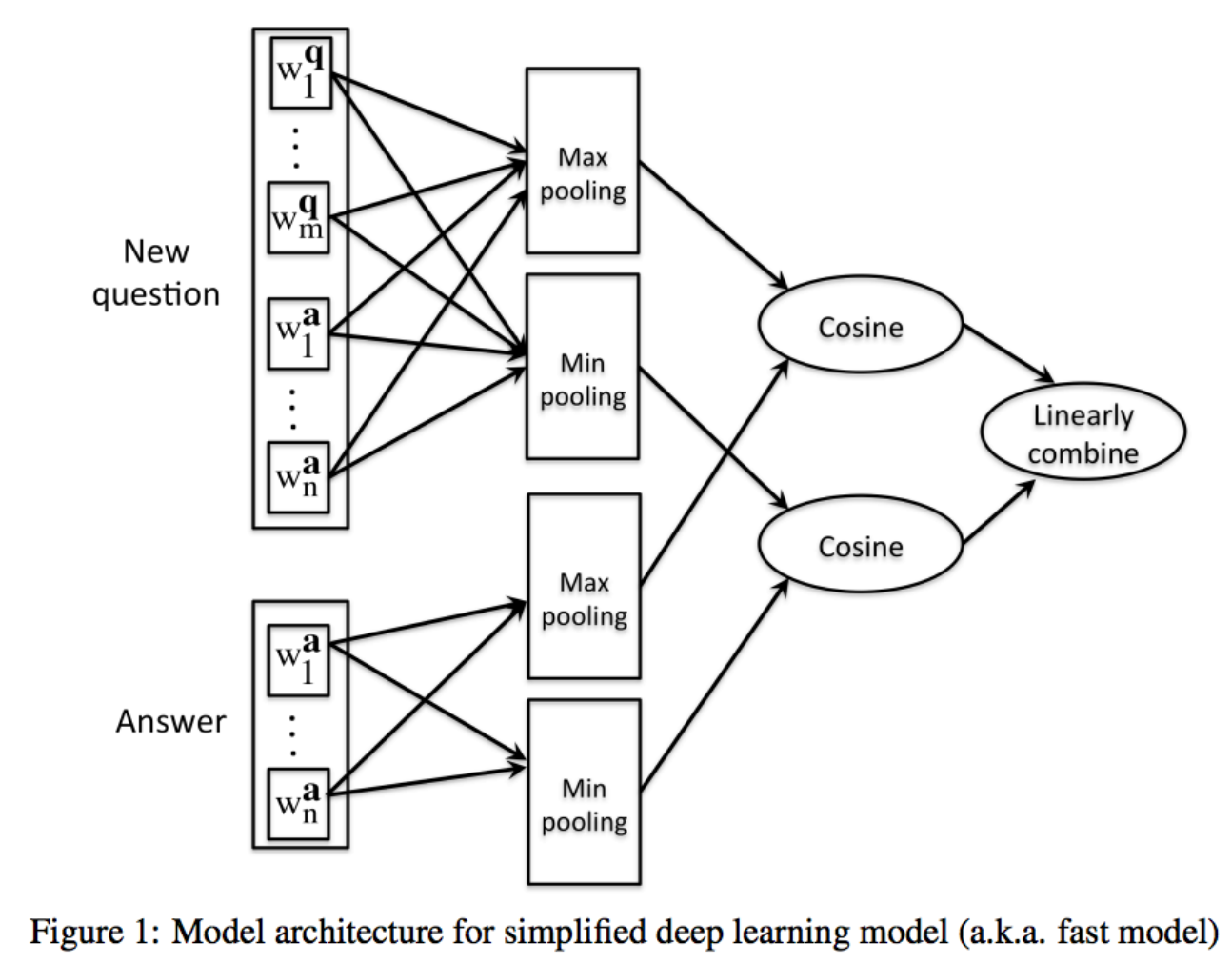
Query Performance Prediction部分の実装がちょっと面倒ですが、それ以外は簡単に実装できますので、質問応答タスクが来たらちょっと試してみるのもいいかもしれないなと思いました。
Non-sentential Question Resolution using Sequence to Sequence Learning (pdf)
対話式の質問応答システムの場合、文脈からわかることを端折ってユーザが質問することがあります。
以下の対話は文脈を端折って質問している例です。
最後の問いかけを補完するなら「日本で一番低い山は?」という質問文になるでしょう。
ユーザ: 日本で一番高い山は?
ボット: 富士山です。
ユーザ: 低い山は?
一方で質問応答システムを作る側としてはユーザの質問は一文で完結しているほうがうれしいです。
この発表では文脈とユーザの(端折った)質問を入力として、完結した質問文を作る方法を提案しています。
基本的にはEncoder-Decoderモデルを使って質問文生成を行っていますが、データ数が統計的機械翻訳とは異なり非常に少ないことから、それに伴うOOV (Out of vocabulary)への対処をどうするかが焦点となってきます。
提案手法ではSyntactic Sequence ModelとSemantic Sequence Modelという2つのやり方を示しています。
これらのモデルの違いはOOVによる未知語の扱いかたです。
結果としてこれらのモデルを組み合わせたものが一番性能がよかったそうです。
Neural Machine Translation with Supervised Attention (pdf)
私が初めてアテンションを知ったのは社内勉強会ででしたが、そのときに「GIZA++でアライメントとってNMTに突っ込むってやらないんですか?」と質問しました。
そして、この発表がそれに近いことをやっていました。
内容としては損失関数にアライメントとアテンションの不一致さについての項を設けて、アテンションをうまくアライメントに似せるというものです (下式)。
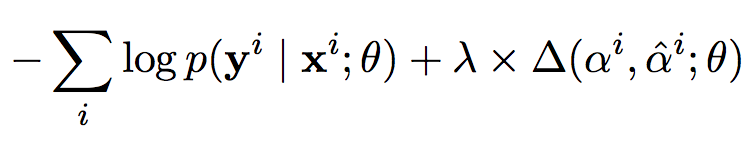
結果としていい具合にアテンションにアライメントを入れるとBLEUがよくなるようです (下図)。

パラメータλを増減させたときにBLEUがどのように変化するのかはちょっと気になりました。
もっともNMTの学習はものすごく時間がかかるので、簡単に調べることができるようなものではないですが・・・。
Author