Blog
EMNLP2017 参加報告
こんにちは。アドテク本部 ProFit-Xの押切です。
2017/09/07〜11にかけてコペンハーゲンで開催された、自然言語処理 (NLP) 分野のトップ国際会議 Conference on Empirical Methods in Natural Language Processing (EMNLP) に参加してきました。
この記事では、今回のEMNLPの概要と発表の一部について紹介します。
EMNLP2017 の概要
今回のEMNLPへの投稿数は、ロングペーパーとショートペーパーを合わせて過去最多となる1418件で、その中から約23%にあたる323件が採択されました。投稿された論文の統計情報を見ると、やはり「neural networks」「deep learning」がキーワードに入っている論文が特に多く、また「情報抽出、情報検索、質問応答」の分野に多くの論文が投稿されていることがわかります。
本会議の参加者数は、オープニングセッションの時点で1000人以上とのアナウンスがありました。また日本からは、少なくとも30人程度の参加者がいたと思われます。

本会議当日は、すべての招待講演と口頭発表が録画され、ライブ配信されていました。さらに会議終了後もすべての動画が視聴可能となっています(10/11現在)。気になった方はチェックしてみてください。
また本会議ポスターセッションでは、各ポスターに貼られたQRコードを通じて気に入ったポスターに投票できるという新しい取り組み(Poster Audience Award)が実施されました。しかし、一ヶ月経った10/11現在もなぜか結果が公開されておらず、結局どうなったのかよくわかりません……。

人が少ない時間帯のポスターセッションの様子
1日目のポスターセッションでは、私も学生時代の研究について発表しました。この研究では、新語や分野特有の固有名詞などを大量に含むようなテキストデータを使って単語ベクトルを作るのは一般に難しいという背景のもとに、このようなテキストデータを使って単語ベクトルをむりやり作る手法を提案しています。詳細が気になった方は論文をチェックしてみてください。
研究をいくつか紹介
Best paper award は、下記の4つの論文に与えられました。
- データセットに含まれるジェンダーバイアスを分析、データセットから学習する際に生じるバイアスの影響を軽減する論文 (pdf)
- 自傷行為の恐れのある Reddit ユーザーを検出するためのデータセットと手法に関する論文 (pdf)
- マルチエージェントシステムの実験(この研究では、ボット同士を協力・対話させて、一つのタスクを解かせるという設定)で得られる言語の性質を詳しく調べる論文 (pdf)
- 要約の目的で文書集合からコンセプトマップを生成するタスクの訓練データを作成する論文 (pdf)
以下、ベストペーパーと招待講演の中から特に気になった研究を2件紹介します。
Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints (pdf)
近年自然言語処理分野では、機械学習と大規模なデータセットを用いた手法が盛んに扱われていますが、この結果として得られる予測器や特徴量はデータセット由来の様々な “バイアス” の影響を受けてしまうことが、いくつかの既存研究で報告されています。ここでいう “バイアス” とは、例えば「画像とその画像を説明するようなタグのペアを集めたデータセットにおいて、cooking タグが付いている写真には男性よりも女性が写っていることが多い(ジェンダーバイアス)」というような社会的なバイアスのことを指します。こういったバイアスの影響を受けた予測器をそのままプロダクトに組み込んでしまうと様々な倫理的問題を起こしてしまうため、なにかしらの対策が必要です。
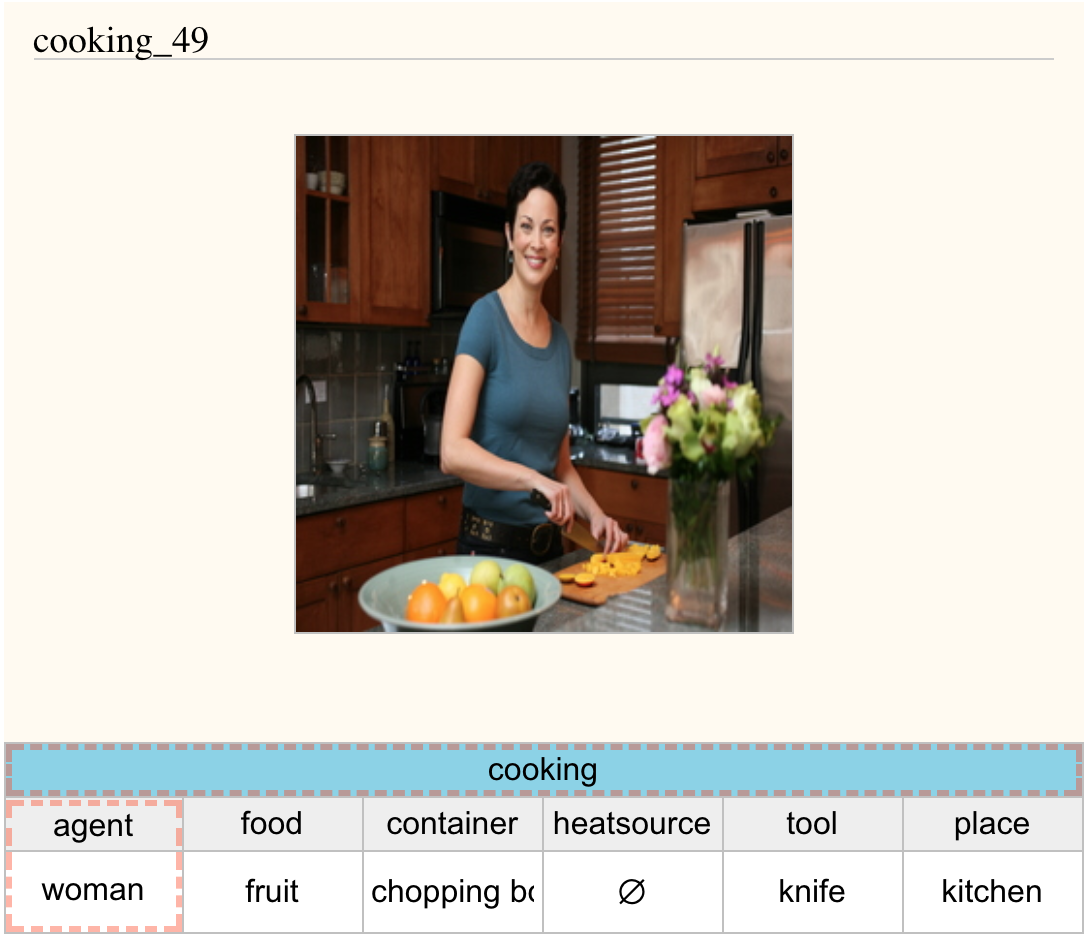
cooking, agent=woman のタグが付いている画像 (http://imsitu.org/browse/?verb=cooking&agent=woman より)
この研究ではまず、imSimu と MS-COCO と呼ばれるデータセットがジェンダーバイアスを含んでいることを、簡単な分析によって示しています。さらにこれらのデータセットを使って画像からタグを推定する(例えば、上の画像を入力すると cooking を出力する)予測器を学習する場合に、結果として得られた予測器のバイアスがデータセットのそれより強くなってしまう、という現象に着目しています。(この現象が、論文タイトルにある Gender Bias Amplification です。)この論文は、この Gender Bias Amplification を軽減しつつ予測器を学習する、一般的なフレームワークを提案しています。実験の結果、Gender Bias Amplification を軽減しつつ、かつ性能を大きく落とさずに予測器の学習を行うことができたと報告しています。
[招待講演] “Does This Vehicle Belong to You”? Processing the Language of Policing for Improving Police-Community Relations (link)
まず背景として、文章の politeness(礼儀正しさ)を定量化し、さらにこれをもとにして、文章を入力したときに politeness を出力する予測器を作るという研究があります(論文)。招待講演では、この politeness の予測器を応用して様々なデータセットを分析した結果を軽快な口調で紹介していました。
例えば、講演者らが今年発表した論文では、アメリカの警官と市民の会話ログのデータセットを分析したところ、話しかける相手である市民が白人の場合と黒人の場合で、(会話が発生した状況・場所や警察官の人種などで調整した上でも)警官側の発言の politeness に差があったと報告しています。
また 別の論文では、同様に Wikipedia と Stack Exchange のデータセットを使って、politeness と社会的な地位・属性の関係を調べています。この論文の中で、Stack Exchange において Python カテゴリより Ruby カテゴリの方が politeness が高い傾向があった、という分析結果が出ていたのが気になりました。
おわりに
上で書いた内容の他にも、word2vec で有名な Tomas Mikolov の講演など、興味深い発表を色々と聞くことができた5日間でした。
Author