Blog
[Strata + Hadoop World 2016 in New York] Day 3 – Session
それでは、イベント 3 日目に開催されたセッションについて書いていきます。
※ 1 日目、2 日目はトレーニング等中心でセッションがないため参加していません。
Powering real-time analytics on Xfinity using Kudu
Sridhar Alla (Comcast), Kiran Muglurmath (Comcast)
11:20am–12:00pm Wednesday, 09/28/2016
IoT & real-time
Location: 1 E 12/1 E 13
Audience level: Intermediate
Tags: media, real-time, iot, data_platform
スピーカーはコミュキャストのディレクター・ソリューションアーキテクトの Alla さんと
エグゼクティブディレクター・データサイエンティストの Muglurmath さん
コムキャストは米国では最大のケーブルテレビ会社です。
ケーブルテレビの会社というと地上波が主流な日本ではあまり考えられないかもしれませんが、
家でインターネットやテレビ・電話を使おうとするとマンションによってはコムキャストを引くしか選択肢がなかったり、
米国では有名な無くてはならないインフラ会社です。
Kudu
http://kudu.apache.org/releases/
Kuduの利用用途
- 月ごとの行動ログや新顧客情報の更新
- データのアップデートやリアルタイムデータのImpalaへのロードなど
- KuduはOLTPオペレーションをサポートしないのでトランザクションやロールバックは今回のユースケースには適応しない。
利用しているテクノロジー
- Hadoop MapReduce – Hadoop 2.6
- Hbase 1.2
- Hive 1.1
- Spark 1.6.2
- Impala 2.7
- Kudu 0.10
- Kafka 0.9
- BIツール Zoomdata and Tableau
Zoomdata が BI ソースとして Kudu に対応しているみたい。
Impala とは
- 基本 SQL が利用可能
- ミリセカンドレベルのハイスピードクエリをサポート
- Hadoop または Kudu からダイレクトに実行可能
- C++ で書かれたハイパフォーマンスエンジン
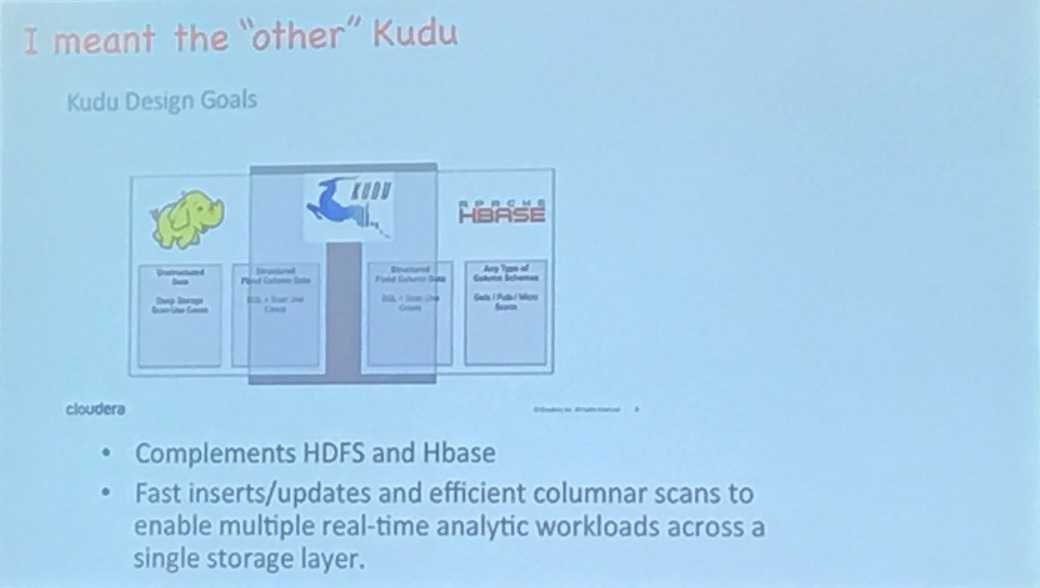
Kudu とは
- HDFS, HBase を補完するもの
- 高速な Insert, Update を可能とし、一つのストレージレイヤーでカラムナー Scans など複数のリアルタイム分析ワークロードを可能とする。
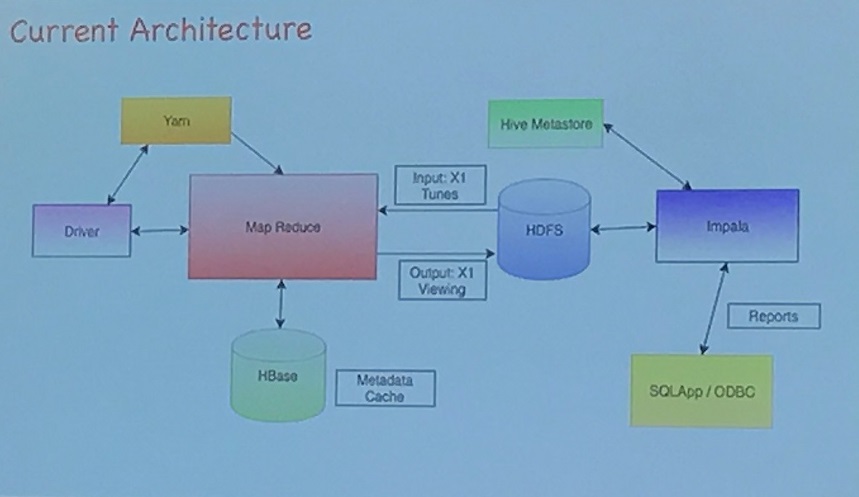
コムキャストの旧アーキテクチャはデータを MapReduce したあと HDFS にいれ Impala と連携
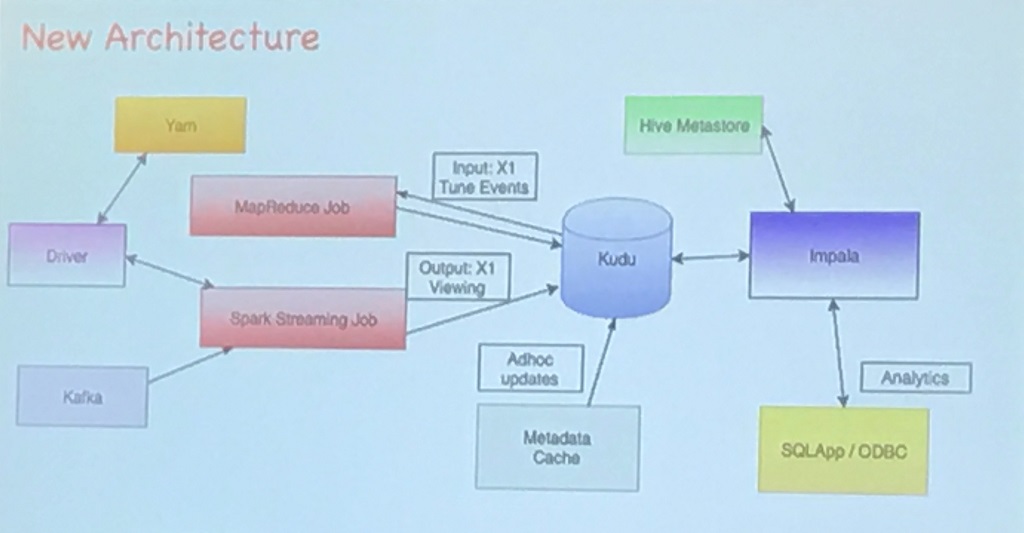
新アーキテクチャーでは Mapreduce や SparkJob で Kudu に書いたり読み込んだりし、最終的に Impala に入れるようにしたそう。
コムキャスト環境
- CDH5.7 300 Nodes 12PB
- memory_limit_hard_bytes is set to 4GB
- block_cache_capacity_mb is set to 512MB
- impala 2.7 running on the same 5nodes for data locality 96GB memory
向いている用途
- Time Series (stream market data, fraud detection & prevention, risk monitoring)
- Machine Data Analytics (Netweork threat detection)
- Online Reporting (ODS)
パフォーマンスについて
2 億行のデータの SCAN で 2 分ちょっととか。
sample table in kudu (4node + 1master, 1.06B rows)
40 columns of mixed datatypes
primary key (Long INT)
update 80 records by referring primary key : 0.25 seconds
update 600 records by referring non primary key columns: 12 seconds
drop 81 record by referring primary key:0.15 seconds
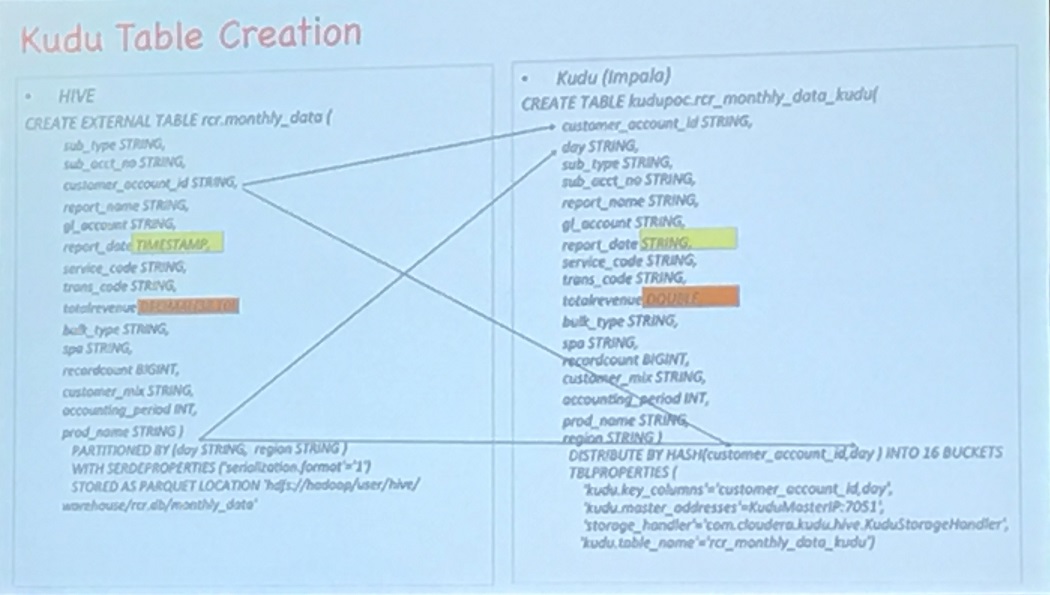
Hive から Kudu (impara) へのテーブルコンバートも使える型が違うためいくつか修正が必要だった。
たとえば TIMESTAMP がなくて STRING にしたり、DECIMAL を DOUBLE にしたり。
まとめ
Kudu について、9/19に Beta がとれて安定してきている。
高速なデータアップデート・インサート・ロードが可能で、まさに HDFS, HBase を補完すると言っていいもの。
BI にも対応しているということでどこかで使ってみたい感じもするが、
OLTPをサポートしているわけでは無いため、トランザクション機能などもなく、
おそらく分析用途として使っていくユースケースが増えるんじゃ無いかなと。
Zoomdata BIについてはあまり知らないので試してみようと思う。
Building data lakes in the cloud
Alex Bordei (Bigstep)
1:15pm–1:55pm Wednesday, 09/28/2016
Enterprise adoption
Location: River Pavilion
Audience level: Intermediate
Tags: cloud, architecture
クラウドにデータレイクを作るという名のセッション。
http://bigstep.com/services/data-lake
BIGSTEP 社の Alex さんによるセッションです。
まずはこのセッションなぜか席が円卓になってます。
この会場にたどり着くまでが大変で、行く途中に迷子になってしまいました。
このJavits Center は鬼のように広くて事前に会場のマップを頭に入れておくことをお勧めします。
アジェンダ
- なぜクラウドにデータレイクを作らないといけないのか?
- オンプレとクラウドのネットワークセキュリティーソリューション
infinite storage vs infinite compute
storage is economical
36$/TB/Month
compute not so much
16cores 64GB RAM
552$/month(1.1$/h)
コストでいうとオンプレミスとさほど変わらない
セキュリティについて
データレイクはハッカーの格好の的になりうる。
AD, HSMs, VPN, Firewall, SSO いろんなソリューションがあるが Cloud, On-premise を組み合わせて使う際の構成について考える。
暗号化について
KMS をつかっての Hadoop 暗号化
オンプレミスでの第三者暗号化(HSM)
クラウドでは CloudHSM などを AWS で出していたりする。
アクセスコントロールについて
Kerberos, LDAP や Hadoop HDFS の権限管理機能を使う。
リアルタイム=本番環境について
システムは下記の要件が必要になる
- パフォーマンス
- 安定性
- オンラインサービス
- 失敗時のトレース
Tuning Impala: The top five performance optimizations for the best BI and SQL analytics on Hadoop
Marcel Kornacker (Cloudera), Mostafa Mokhtar (Cloudera)
1:15pm–1:55pm Wednesday, 09/28/2016
Hadoop internals & development
Location: 3D 10Audience level: Intermediate
SparkSQL Impala と Sparkの比較
- Batchに向いているのがSpark
- BI、SQLでの分析に向いているのがImpala
- 手続き処理、開発に向いているのがSparkSQL
- ここ1年で5倍速くなった(TPC-DSベンチ)
ベンチ環境
Memory: 384GB
CPU: E5-2630L x 2 (12 Core)
Disk: 932GB (24 Disk)
Data: 3TB (Parquetフォーマット、256MB Block Size)
WorkLoad: 同時 8 User, Queryには8個のパラメータを使用(都度ランダム)
MiddleWare: Impara2.7 (CDH5.10), SparkSQL 2.0, Presto 0.148-1.1.2
結果
SparkSQL の9倍、Prestoの23倍速くなった
しかもImparaは100%Passしたが
Spark-SQLは45%, Prestoは66%Passに留まった

チューニングポイント
- ファイル数が少なすぎると並列処理ができなくなり遅くなります
- ファイル数が多すぎるとMetadata処理がボトルネックになります
- 定期的に適正な数になるよう、またスキャン効率をあげるために圧縮を行う
- パーティション数は20,000以下に保つ(システム上の限界ではないです)
- String 型は変換がいるがNumeric型は変換なしで直接計算されるのでNumeric型を使う
- 格納するデータに合わせて可能な限り小さい型を選ぶ
- ネスト構造を利用する
- Statics情報を活用する
- メモリサイズを調整する


まとめ
- 可能な限りスキーマセマンティックに近いデータ型を選ぶ
- 可能な限りワークロードに近いパーティションを作成する
- パーティションにあったクエリをかく
- 1:n のリレーションではネストテーブルを利用する
- Statics情報を利用する

Creating real-time, data-centric applications with Impala and Kudu
Marcel Kornacker (Cloudera), Todd Lipcon (Cloudera)
2:05pm–2:45pm Wednesday, 09/28/2016
Hadoop use cases
Location: 3D 08Audience level: Beginner
Tags: architecture, real-time
他のセッションとかぶってしまう部分もありますが
HDFS と HBase のギャップを埋める存在であること

おすすめ用途別構成
Real-time 分析に向いていてレポーティングであれば Kudu + Impala
ストリーミング処理であれば Kudu + Spark をお勧めしていました。

Impalaについて
ImpalaはC++実装のエンジンでパフォーマンスがよく
Kudu, HDFS, HBase, MetaStore といった Hadoop コンポーネントとの親和性も高い
ファイルフォーマットも Parquet, Avro など利用可能
標準 ANSI SQL、ネスト型対応、odbc/jdbc 接続、kerberos/LDAP 認証対応

Kuduについて
Kuduでは 275 Node, 3PB でのテストで
秒間 100 万 Read/Write 各 Node のスループットは、数GB/s
(デザイン上は 1000 Node 以上、数10PB可能)
LZ4, gzip, bzip2 圧縮対応
といった機能面の紹介から Kudu でのデータの持ち方の話と
Kudu + Impala での様々な SQLの書き方と実際、内部的にどのように実行されているのかといった解説までありました。
まとめ
- Kudu + Impala 構成は、RDBMSライクにBigDataを扱える(INSERT、UPDATE、DELETE)
- シンプルなアーキテクチャで分析用途にもリアルタイム処理にも向いている
- 複数のエンジンから同一のデータソースにアクセスできる(Impala,Spark etcから)
- 1つのSQLで複数のストレージからデータを取得し処理が可能
- スケーラビリティと高い同時処理が可能

Big data processing with Hadoop and Spark, the Uber way
Praveen Murugesan (Uber Technologies Inc)
2:55pm–3:35pm Wednesday, 09/28/2016
Hadoop use cases
Location: Hall 1BAudience level: Beginner
Tags: geospatial, real-time, data_platform
Uberのアーキテクチャに関するユースケースの紹介でした。
まず最初にUberは75以上の国、500以上の都市で利用されていて今も拡大を続けています
そのため1000以上の都市オペレーター(地上チーム、Uberネットワークを広げる)
100以上のデータサイエンティスト、10以上のエンジニアチームがあります。

アーキテクチャの今昔
2014年当時
Kafka のデータは S3 を経由して EMR 処理した上で
Key-Value DB, RDBMS のデータは直接、Vertica に入れ、そこから各チームが利用していたそうです。

現在
Kafka, Schemales DB, SOA DBs から HDFS に格納、Spark, Presto を用いて各チームが利用しているとの事です。

結果
Hadoop Data Lakeが構築され、Parquet や Avro が使えるようになり
厳格なスキーマを管理し、特定のツールにロックインされなく、位置情報処理ができるようなった
またデータツールとしては Spark UDK や Attis というのを使っているとの事でした。

Hadoop Data Lake ができたときに Virtica は早いがスケールさせるにはコストが高く
Hive はスケールはするが遅いというそれぞれの欠点を埋め
かつ Uber という特性上、位置情報処理により特化した Presto を採用しています。
この後は Spark UDK の 機能を含めた詳細な話や、今後の目指す方向などの話もありました。
Watermarks: Time and progress in Apache Beam (incubating) and beyond
Slava Chernyak (Google)
2:05pm–2:45pm Wednesday, 09/28/2016
IoT & real-time
Location: 1 E 12/1 E 13
Audience level: Intermediate
https://docs.google.com/presentation/d/1FodfKy0azRQr7xOCSsLRK2RkG36yBlUMZu5Ktb8eYOQ/present?slide=id.g860da9831_0_1549
実際のサンプルコードをつかって Apache Beam で簡単にストリーミングワークフローができる説明など。
たとえばデュレーションで 60 秒持たせるなども 1 行追加するだけで実現できてしまう。
今回タイトルのウォーターマークとは、ストリーミングを考える上で必須の概念。
詳しくは資料を見てもらう方がわかりやすいと思うんですが、ようはデータフロー上でどこまで処理が完了しているかを示すためのタイムスタンプ
イベントが発生した時のタイムのタイムスタンプを利用することで、どこまでの処理が終わっているかや、スタックしているかどうかなど可視性を上げる。
たとえば PubSub でのデータを使う場合、Publish した時間を基準にしてしまうと順序が保障されていないため、イベントが発生した時間を基準にすることでデータ処理の一貫性を定義する。
Triggers in Apache Beam (incubating)
Kenneth Knowles (Google)
2:55pm–3:35pm Wednesday, 09/28/2016
IoT & real-time
Location: 1 E 12/1 E 13
Audience level: Advanced
https://docs.google.com/presentation/d/1smGXb-0GGX_Fid1z3WWzZJWtyBjBA3Mo3t4oeRjJoZI/present?slide=id.g11f4f1a9ce_0_0
Apache Beamセッション 2 つ目。といっても 1 つ目はほとんど watermark の説明だったけど
今回のアジェンダはこちら。
・ビッグデータ:無限とアウトオブオーダー
・ビームのモデル
・ウォーターマークとトリガー
まとめ
Beamの活躍する場所
無限のボリューム
順序の一貫性が取れない
遅延
Beamモデルの分離を意味するのは
何をコンピューティングしているのか
何をイベントタイムにするのか
いつ結果を出すのか
どのように改良するのか
トリガーがバランスを制御する
正確性(ウォーターマークにより可視化)
レイテンシー
コスト
Beyond Hadoop at Yahoo: Interactive analytics with Druid
Himanshu Gupta (Yahoo)
4:35pm–5:15pm Wednesday, 09/28/2016
Data innovations
Location: 1 E 07/1 E 08
Audience level: Beginner
Tags: architecture, media, real-time, data_platform
Druid はハイパフォーマンスなカラムデータストアーで、
実は半年ぐらい前に行ったアドテクスタジオでのハッカソンで優勝チームが使っていた。
http://keens.github.io/blog/2016/02/27/druidtoiuriarutaimude_tabunsekitsu_ruwoshitta/
Druidについて検索するとアドテク社員のブログがよく引っかかる。
http://x1.inkenkun.com/archives/5251
今回は Yahoo がインタラクティブなアナリティクスに Druid を利用しているという話。
Hadoop, Pig, Oozie をつかって結果をRDBに入れていたものを Druid にしたという話。
新環境では Storm, Kafka からも Druid にデータを挿入している。
スケール
35 以上の Druid クラスター
2000 以上のホストと 1 クラスター 325 ノード
2.5 mn データクエリー/日
1 クラスター 325 ノードとは凄まじい規模ですね。
デプロイについて
DNSを切り替えてブルーグリーンデプロイもやってたりする。
カナリアデプロイも利用可能とのこと。
The Netflix data platform: Now and in the future
Kurt Brown (Netflix)
5:25pm–6:05pm Wednesday, 09/28/2016
Data innovations
Location: 1 E 07/1 E 08
Audience level: Intermediate
Tags: architecture, media, real-time, data_platform
https://drive.google.com/file/d/0B72kok3RkcZDLTl5aXpadkpNdEE/view
いよいよ本日最後のセッション。時差ぼけもあってそろそろ体力も限界です。
Netflix の次世代データプラットフォームについてのセッションなのですが、開始 5 分前から立ち見が出るほどの人気っぷり。
Netflix ほどのサービスの次世代データプラットフォームについてみんな関心があるのでしょう。
Manbang についていじってて面白かった
http://jp.techcrunch.com/2016/08/25/20160824north-korea-launches-a-netflix-style-streaming-service-called-manbang/
https://twitter.com/netflixdata/status/781247070833299456
Metacat について
https://github.com/Netflix/metacat
- コモンインターフェース
- 拡張メタデータ
- 最適化
- 標準データタイプ
- ノティフィケーション
Netflix big data portal
メモ
http://samza.apache.org/
http://gearpump.incubator.apache.org/overview.html
Strata + Hadoop 記事リンク
[Strata + Hadoop World 2016 in New York] Day 3 – Keynote
[Strata + Hadoop World 2016 in New York] Day 4 – Keynote
[Strata + Hadoop World 2016 in New York] Day 4 – Session
Author