Blog
[Strata + Hadoop World 2016 in New York] Day 4 – Session
それでは、イベント 4 日目(最終日)で聞いてきたセッションについて書いていきます。
※ 1 日目、2 日目はトレーニング等中心でセッションがないため参加していません。
Caravel: An open source data exploration and visualization platform
Maxime Beauchemin (Airbnb)
11:20am–12:00pm Thursday, 09/29/2016
Visualization & user experience
Location: 1 E 10/1 E11
Audience level: Intermediate
Caravel という Airbnb 製のオープンソースデータビジュアライゼーションプラットフォームの紹介セッション
例えば Tableau だと Presto & Druid に対応していなかったり、スケールしなかったりコストもかかる。
Airbnb is builders not buyers!
ここで、Tableau10 だと Presto 対応しているよって声が。確かに。でも Druid までは対応してないですね。
http://www.tableau.com/about/blog/2016/8/tableau-10-includes-even-more-data-source-options-57505
Caravel のデモ
ダッシュボードを見る感じオープンソースとは思えないほど良くできている。
Github の Readme.md 見てもらうだけでそのインパクトがわかると思う。
1table or view という制限はあるもののキャッシュ機構が付いていたり、Druid により高速に動作したり。
Tableau の代替となるものではないかもしれないけどデータ可視化ツールとしては凄いのが出てきたというイメージ。
帰ったらとりあえずインストールしてみようと思う。
Twitter’s real-time stack: Processing billions of events with Heron and DistributedLog
Karthik Ramasamy (Twitter)
1:15pm–1:55pm Thursday, 09/29/2016
IoT & real-time
Location: 3D 12
Tags: media, real-time, data_platform
https://twitter.com/karthikzhttps://twitter.com/karthikz
https://twitter.github.io/heron/
https://github.com/twitter/heron
Twitter のログプロセッシングについて。
この 3D という場所が全くわからず遅刻しちゃいました。。。迷路すぎる。。
リアルタイムとは?なぜリアルタイムである必要があるのか?
Real time analytics
Scribe オープンソースログアグリゲーションシステム ハイスループット&スケール
Event Bus(PubSub) & Distributed log
Distributed log
400TB /Day IN
10PB/Day Out
2Trilion Event
Twitter Heron
- コンテナベースアーキテクチャー
- モニタリングとスケジューリングが分かれている
- シンプルな実行モデル
- グッドパフォーマンス
Heron がプロダクションになって 2 年、使われる場所が増えてきている。
500 Billion Event/Day
Lambda Architecture
Data -> Scribe -> Event Bus -> Heron -> Result
Lessons learned running Hadoop and Spark in Docker
Thomas Phelan (BlueData)
2:05pm–2:45pm Thursday, 09/29/2016
Data innovations
Location: 3D 12
Audience level: Beginner
実は昨日Expoで見つけた良さそうなプロダクトのセッションがあったので来てみました。
現在アドテクスタジオでやっている OpenStack Sahara のようなマルチテナンシー対応の Hadoop クラスターをマネージメントするシステムで
それをコンテナで実現するプロダクトです。
結構広い会場なのですが始まった直後立ち見が出るほどの盛況で、レアな同じ悩みを抱えた人も世界で見ると多いんだなぁと思いました。
Bluedata というプロダクトを作る上で苦労したことなどを紹介するセッションで
Storage, Network, CPU, Memory のリソースなどでここはこうした的な話でした。
Swarm, Kubernetes, AWS ECS, Mesos などいろんなマネージメントがあるけど独自でやっているとのこと。
CircleCI のようにコンテナ使ったプロダクトではこの先どうなるかわからない管理ツールを使わず独自実装するしかないのかもしれないですね。
マルチテナンシーをやる上でネットワークとストレージセキュリティーが肝になる。
CPU はオーバーコミットしているがメモリはしていないとのこと。
ネットワークの分離に VxLAN つかっている。
標準的な Hadoop のサーバー環境でベンチマーク結果がでていたが、ほとんどオーバーヘットがないことが証明されていた。
LDAP/AD による認証機構がある。
Machine intelligence at Google scale
Kazunori Sato (Google)
2:55pm–3:35pm Thursday, 09/29/2016
Data science & advanced analytics
Location: 3D 08
Audience level: Intermediate
Tags: cloud, ai, deep_learning
おそらくこの Strata Hadoop で登壇している中で唯一日本人の Google 佐藤さんのセッション。
昨日ブースでセッションやるよって聞いて来てみました。
ちょうど CloudML も Public Beta になり、3D12 よりさらにわかりづらい部屋にもかかわらず、会場が埋まるほどの人気セッションでした。
まずはニューラルネットワークの説明。
赤と青のデータポイントがかさらないようにニューラルネットワークによるディープラーニングで計算を行うデモが行われました。
https://cloud.google.com/blog/big-data/2016/07/understanding-neural-networks-with-tensorflow-playground
※こんなやつ。
Inbox で返信文がディープラーニングでレコメンデーションされる例の紹介。10% がこれにより返信されているみたいです。
Cloud Vision API のデモの説明。
Cloud Speach API demo
TesorFlow につい
1 Pbps のキャパシティーをもつジュピーネットワークについて
TPU について
CloudMLについて
オークネットでのCloudMLの利用についての紹介
Apache Kudu: 1.0 and beyond
Todd Lipcon (Cloudera)
4:35pm–5:15pm Thursday, 09/29/2016
Hadoop internals & development
Location: River Pavilion
Audience level: Intermediate
http://kudu.apache.org/
昨年の Strata のときは 0.5 だった Kudu がいよいよ 1.0 になりました。
コミュニティーも Slack で 360 人以上いるとのこと。
新機能について
UPSERT Support
HBase cassandra でいう Put に相当する機能。
セキュリティのロードマップについての紹介なども。
Kerberos 認証や、LDAP, UNIX での Group/Role 設定など対応予定。
オペラビリティについてもスタビリティの向上やリカバリーツール、障害解析機能などが予定されている。
パフォーマンスについても向上や、IN や LIKE でのフィルターも実装予定
簡単に始める VM などもあるので試してみるには簡単そう
http://kudu.apache.org/docs/quickstart.html
Parquet performance tuning: The missing guide
Ryan Blue (Netflix)
11:20am–12:00pm Thursday, 09/29/2016
Data innovations
Location: 1 E 07/1 E 08
Audience level: Intermediate
Tags: performance
Netflix では 40 PB 以上のデータを S3 において分析をしている
1000 以上のテーブル 100 万以上のパーティション
Parquet フォーマットを利用する事で早くなった。
とはいえ、Parquet で気を付けることが多々あるので紹介
Directory Filter の話( encoding fallback を避けるには…)


Format Version 2 の話と Brotli compression( Google の作った圧縮 LZ77 ベース)のどのタイプが効率が良いかという話


Implementing streaming architecture with Apache Flink: Present and future
Kostas Tzoumas (data Artisans)
2:05pm–2:45pm Thursday, 09/29/2016
IoT & real-time
Location: 3D 08
Audience level: Intermediate
Tags: real-time
Eコマース、金融、IoT、Internet&Mobile で使われている
UBER、NETFLIX、Alibaba、King、ERICSSON など

Alibabaでは、1000 Node 以上 5000 Core 以上、秒間 100 万イベント
King では 30 Billion Event / day

各Serverから集めて Kafka を経由して Flink 、そこから各種分析
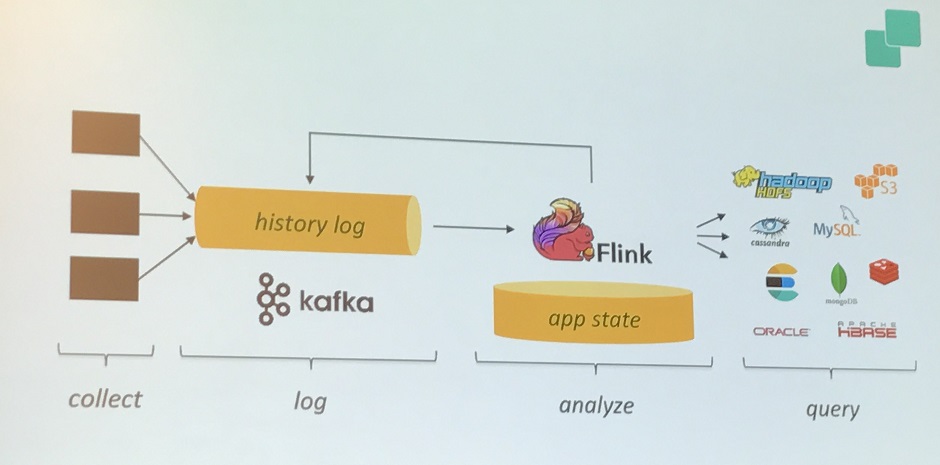
高パフォーマンス、低レイテンシ、対障害性に優れている
ステートフルアプリケーションでの秒間 1000 万以上のイベント処理
1 ケタ台の数ミリ秒で返すレイテンシ
障害時の挙動を説明
確実に1回だけ実行することが保証される

Flink v1.1
Operations Ecosystem BroaderAudience ApplicationFeatures ごとの機能一覧図

Dynamic Scalling

ステートフルであり、障害発生後も、前回処理した内容を保持し途中から処理を再開する
1オペレーションごとに数十 GB のステートサイズに対応

Strata + Hadoop 記事リンク
[Strata + Hadoop World 2016 in New York] Day 3 – Keynote
[Strata + Hadoop World 2016 in New York] Day 3 – Session
Author