Blog
Coling 2016参加レポート – その2
こんにちは、AI Lab新卒の田中です。
大阪で開催されている自然言語処理の国際会議、COLING 2日目の参加レポートをお送りします。
2日目も初日同様にワークショップとチュートリアルが開催されました。
先輩の山本と共にWAT 2016 The 3rd Workshop on Asian Translationを聴講していたのでまとめます!
初日の夜は京橋駅付近にあるたこ焼き屋さんでたこ焼きを買って食べました。
やはりこっちのたこ焼きは美味しいです。
WAT 2016 The 3rd Workshop on Asian Translation
概要
アジア言語の翻訳ワークショップで今回で3回目です。
WATというと評価型ワークショップだと思いこんでいたのですが、今年からリサーチトラックもできたようです (前日に学生さんにツッコまれました![]() )。
)。
ちょっとだけ評価型ワークショップについて書いておきましょう。
まず昨年度のワークショップからの変更点としては以下が挙げられます。
翻訳サブタスクが増えました
- 英日特許翻訳
- インドネシア語-英語ニュース翻訳
- ヒンディー語-英語、ヒンディー語-日本語翻訳 (ドメインは色々混ざっています)
が追加されました。
評価尺度にAMFMが追加されました
BLEUとRIBESに加え、AMFM (Adepuacy-Fluency Metrics) (pdf) が追加されました。
この尺度は忠実さ(adequacy)と流暢さ(fluency)を1つの値で表すことができます。
人手での翻訳評価をプロに依頼するようになりました
一対比較の評価をクラウドソーシングからプロの翻訳会社に頼むようになりました。
あと、昨年度と比較してニューラル機械翻訳(Neural Machine Translation; NMT)を使用するチームが増えたようです。
時代の流れを感じました。
Invited talk
Google JapanのHideto Kazawaさんによる、Google翻訳が精度向上した裏側のはなしです。
概要
従来のフレーズベースの翻訳手法PBMTと比べ、Neural Networkを用いた手法GNMT (Google Neural Machine Translation) (arXiv) によって翻訳精度が飛躍的に向上しました。
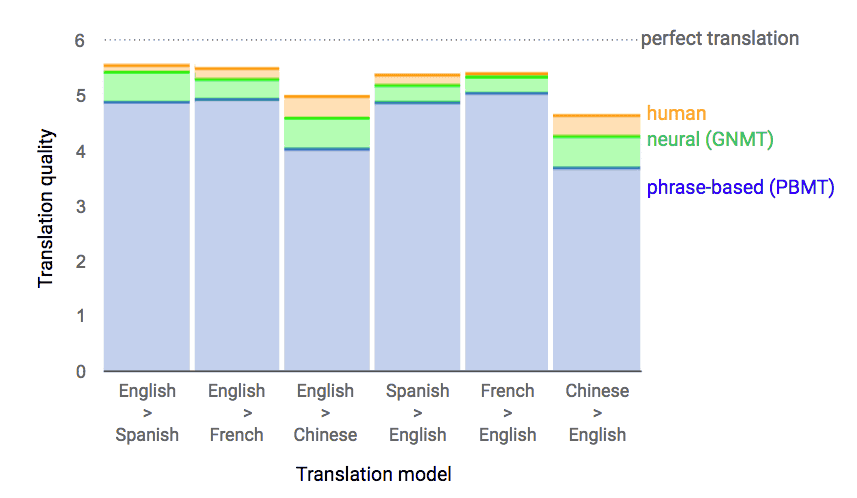
(図はGoogle Research BlogのA Neural Network for Machine Translation, at Production Scaleから引用)
このグラフを見る感じでは、従来のphrase-based (PBMT)に比べてneural (GNMT)がよくなっています。また、GNMTの結果は、人間の翻訳であるhumanに近づいてきていることもうかがえます。
なお、humanの翻訳も文脈に応じて翻訳が変わることもあるので、完璧な翻訳とならない場合があります。
例えば一般的な会話で「hello」といったときの日本語訳は「こんにちは」ですが、電話越しでのhelloは「もしもし」になるような感じです。
GNMTは、Bahdanauらの論文(arXiv)が元となっており、attentionベースのencoder-decoderモデルを用いています。
基本的には元のモデルに7層足しものだと考えればいいのですが、「寿司」みたくシンプルではあるものの入念にデザインされています。

次の4つのことに対処しようとすると、このようなデザインになったそうです。
Large Data、Open Vocabulary、Serving Latency、Many Languagesです。

Large Data
大量の学習データを扱うために、分散して機械学習を行う方法(pdf)を使用しています。
また、並列で計算できるようにResidualをLayer1個飛ばしにしたり、Decoderの最下部の層の出力結果をAttentionの入力にするといった工夫がなされています。
Open Vocabulary
ニューラル機械翻訳を使う場合、最初に(使う)語彙を決める必要があるため、語彙が制限されてしまいます。
制限をなくすにはどうすればよいでしょうか?
ニューラル機械翻訳では、トークン(入力、出力の最小単位)が何であるかを気にする必要はありません。
つまりトークンが文字であっても単語であっても文字バイグラムでもよいです。
(補足: トークンを文字単位にしてうまく翻訳できるなら語彙が制限される問題はなくなります。なぜなら、文字を連結させることで新しい言葉を作ることができるからです)。
ただし、トレードオフがあります。
文字のように細かい切るとするとにすると、デコードのステップ数が多なって計算時間がかかります(トークン数が多くなるため)。
一方で、単語のように長めにすると、1ステップあたりの計算時間が長くなってしまいます。
そこでサブワードをトークンとして使います。もともとはGoogle音声認識に使われていた手法(pdf)を転用したそうです。

Serving Latency
スピードはすごく重要です。
スピードを上げるためにTPU (Tensor Processing Unit)を使用してニューラルネットワークの計算を早くするという工夫をしています。
Many Languages
現在Google翻訳では103の言語で翻訳をできます。
これらの言語を新しい翻訳システムに切り替えたいのですが、単純に考えると日本語→英語で1つ、英語→日本語で1つ、というようにかなり多くのモデルを作らなければなりません。
Googleは、より少ないモデル数にする方法を見つけました。
複数の言語が混ざった対訳データに「何の言語に翻訳するか」という特殊なタグを追加してGNMTに投げるというやり方です。
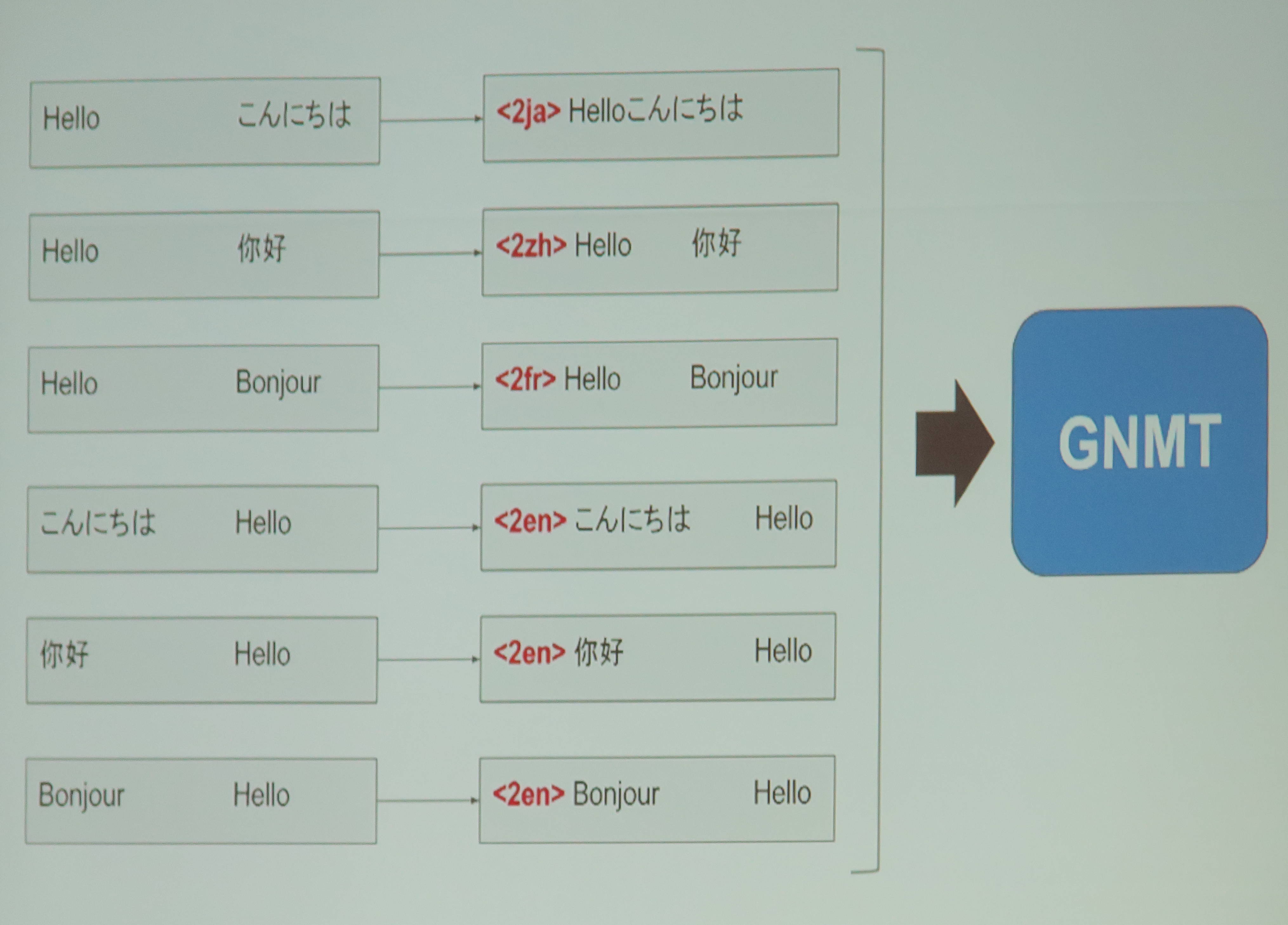
実際に私も論文をGoogle翻訳に貼り付けて試してみました。
感覚的にかなり精度向上していることがうかがえます。
Google翻訳のよりいっそうの発展に期待です。
面白かった発表
Neural Reordering Model Considering Phrase Translation and Word Alignment for Phrase-based Translation (pdf)
フレーズベース翻訳(PBSMT)のReordering Modelをニューラルネットで行うものです。
既存手法としてLiら (2014) (pdf)がありますが、フレーズペアの確率値や、単語アライメントの情報などを素性として組み入れる工夫をしています。
Kyoto University Participation to WAT 2016 (pdf)
WAT2016でShared Taskにおいてベストもしくはそれに近しい結果を収めた京都大学の翻訳システムの紹介です (下の図はPaperからの引用)。
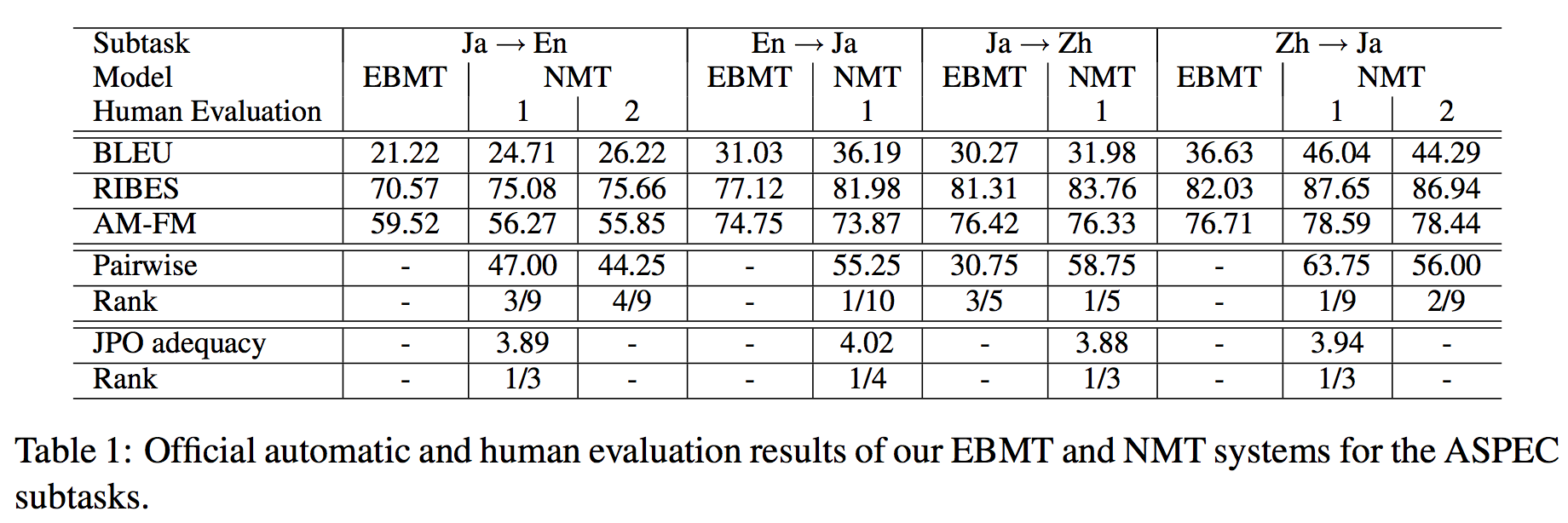
今年は、用例ベース機械翻訳(example-based MT; EBMT)とニューラル機械翻訳(neural MT; NMT)の2つの指向の異なる翻訳システムを使用したそうです。
興味深かったのはNMTのところです。
以下のようにこれまでのNMTの研究をうまく取り入れている印象を受けました。
- 2つのLSTMを重ねています (bi-directional LSTMになっている)。
- 層間にdropoutを入れています (arXiv)。
- 未知語タグは辞書ベースの翻訳で置換しています。
また、Decoder側にも以下のような工夫がなされています。
- 学習時にターゲット側の埋め込み層に正規分布のノイズを加える。こうすることでデコードのあるタイミングで誤訳をしても、その訳に引きずられてさらなる誤訳が発生するという状況を起こしにくくしています。
- ビームサーチに翻訳長の制限を加えています。
ちなみに、このNMTの翻訳システムはGPLライセンスで公開されています。
Author