Blog
Coling 2016参加レポート – その3
こんにちは。AI Labの山本です。
かなり日が空いてしまいましたが、Coling 2016の本会議1日目と2日目のレポートをお送りします。
面白かった発表
Frustratingly Easy Neural Domain Adaptation (pdf)
要素が二値(0/1)で表される疎な素性ベクトルではなくて、ニューラルネットワーク(で得られた分散表現)のような実数で密な素性ベクトルを入力とした場合のドメイン適用についての内容です。
ドメイン適用というのは、簡単にいうと、機械学習をする対象(ドメイン)が複数ある場合に、個々に独立したモデルを作るのではなく、ドメインまたぎの特性をうまく取り入れてモデルを作ることです。
例えば、系列ラベル付け問題でhomeという単語が来たときに、連絡ドメインでは「連絡先」、Xboxエンターテイメントドメインでは「ホーム画面」というラベルを付けることを考えます。どちらのドメインにしてもhomeが来たときに何かラベル振るという特徴があるのでドメイン適用が使えそうです。
この発表では、LSTMを用いた系列ラベル付けではどうやってドメイン適用すればよいのかを4つの手法を提案して比較実験を行っています。
一番安定してよい性能を出していたのはドメイン固有のLSTMと共有のLSTMで生成された出力ベクトルを連結させたものを新たな素性ベクトルとして使う方法でした。
これは二値(0/1)で表される疎な素性ベクトルを入力としたドメイン適用手法である Frustratingly Easy Domain Adaptation (pdf) をニューラル向けに拡張した形になっています。
Large-scale Multi-class and Hierarchical Product Categorization for an E-commerce Giant (pdf)
楽天の商品がどの商品カテゴリに属するかを分類するというものです。
楽天の商品カテゴリは最大5階層で約3万カテゴリあるそうです。
店舗側はそれぞれの商品に対して人手でカテゴリを付けないといけないので大変です。
そこで自動で商品カテゴリを推薦して不便なところを解消したいというのがモチベーションです。
ちなみに商品の分類には、商品名と商品詳細テキストを使用します。
このようなテキストをもとにしたカテゴリ付けは、テキスト分類と呼ばれていてかなり昔から色々な手法が提案されています。
特に最近ではディープラーニングを利用したアルゴリズムが使われるようになってきました。
その中でもこの発表は大規模データでもスケールすることを意識しています。
提案手法では、最初に商品の第1階層のカテゴリを分類し、次に第1階層以下にある詳細カテゴリを分類するという2段階の分類を行っています。
それぞれの分類でディープラーニング手法のDeep autoencoderとDeep belief netが用いられていますが、学習時にちょっとした工夫を行っています。
やっていることは、ちょっと自信がないのですが、ミニバッチ学習時に可視層について非ゼロな可視変数のみに限定して順伝搬・逆伝搬を行うことで行列計算を減らしているのだと思います。
Future workにも書かれていますが、商品の画像データも組み合わせられると面白いだろうなと思いました。
Chinese Poetry Generation with Planning based Neural Network (pdf)
中国語の詩(漢詩)を作るという内容です。
流れは、最初にユーザにキーワードを入れてもらい、コンピュータがそれに基づいて四行連句を作るというものです。
従来研究では、最初の一文はキーワードをもとにして詩のデータベースからすでにある文を選択し、残り3文は前の文を元に生成するということを通例行うようです。
ただ、このやり方ですと、残り3文が主題とかけ離れたものになったり、意味的に矛盾が起こったりしそうです。
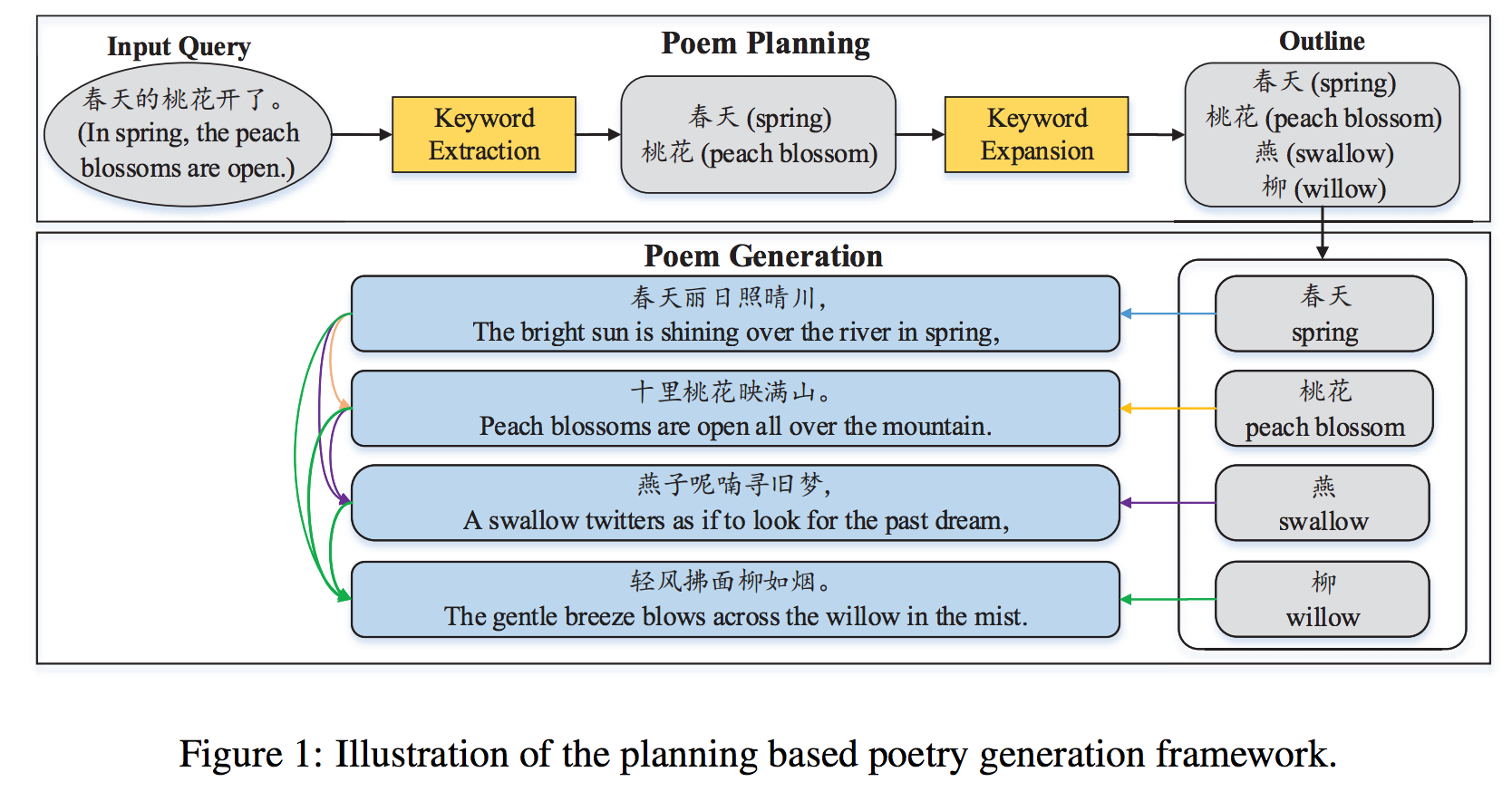
提案手法では、2段階の処理で詩を作るようにしています(下図) 。
最初に、入力されたキーワードを拡張して、四行連句に割り当てます。
その後、前の文とキーワードをもとに文を作ります。
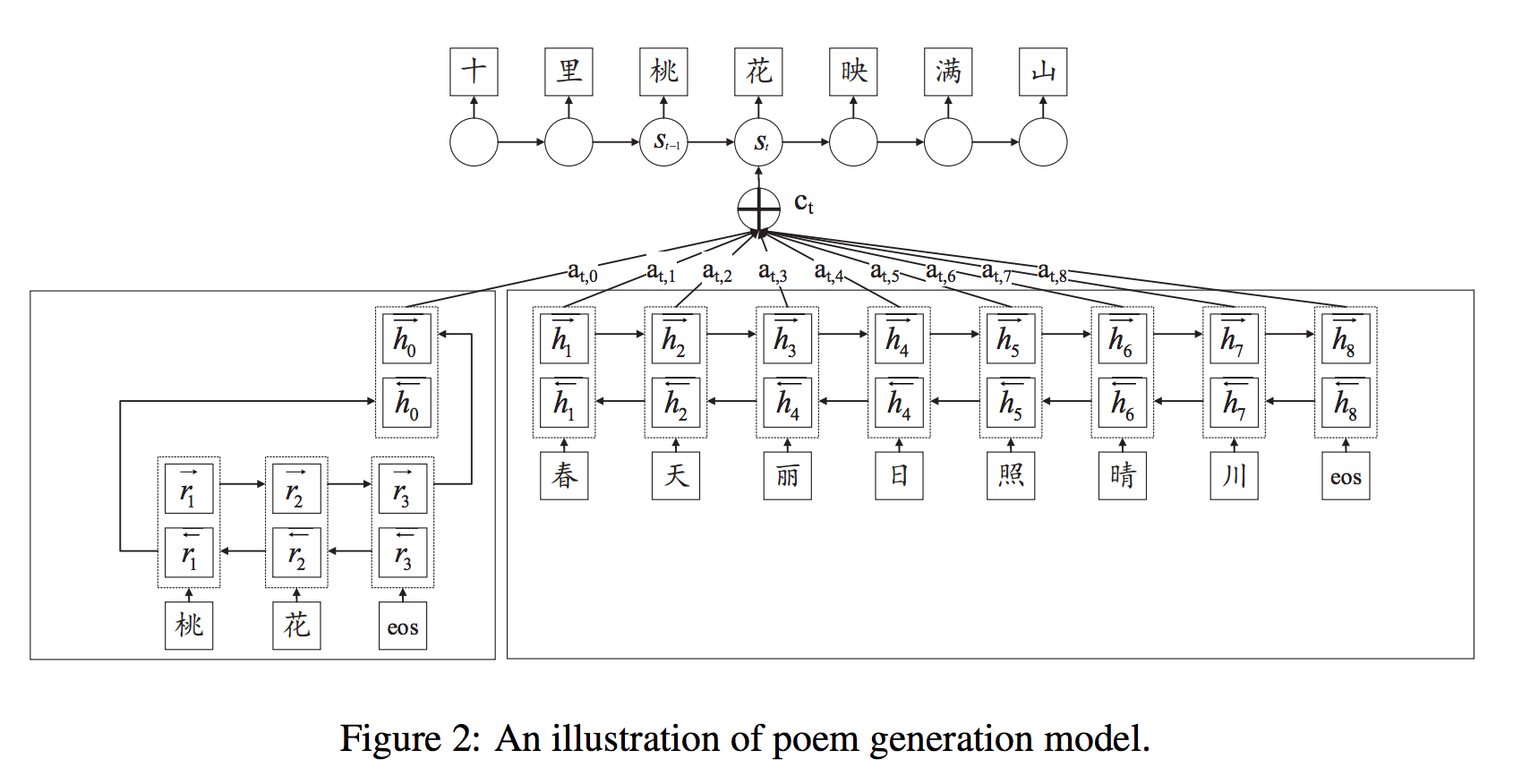
ちなみに文を作るところはEncoder-Decoderモデルを使っています(下図)。
コンピュータが作った詩を人手で評価した結果が以下になります。
5段階評価で一番下が提案手法です。
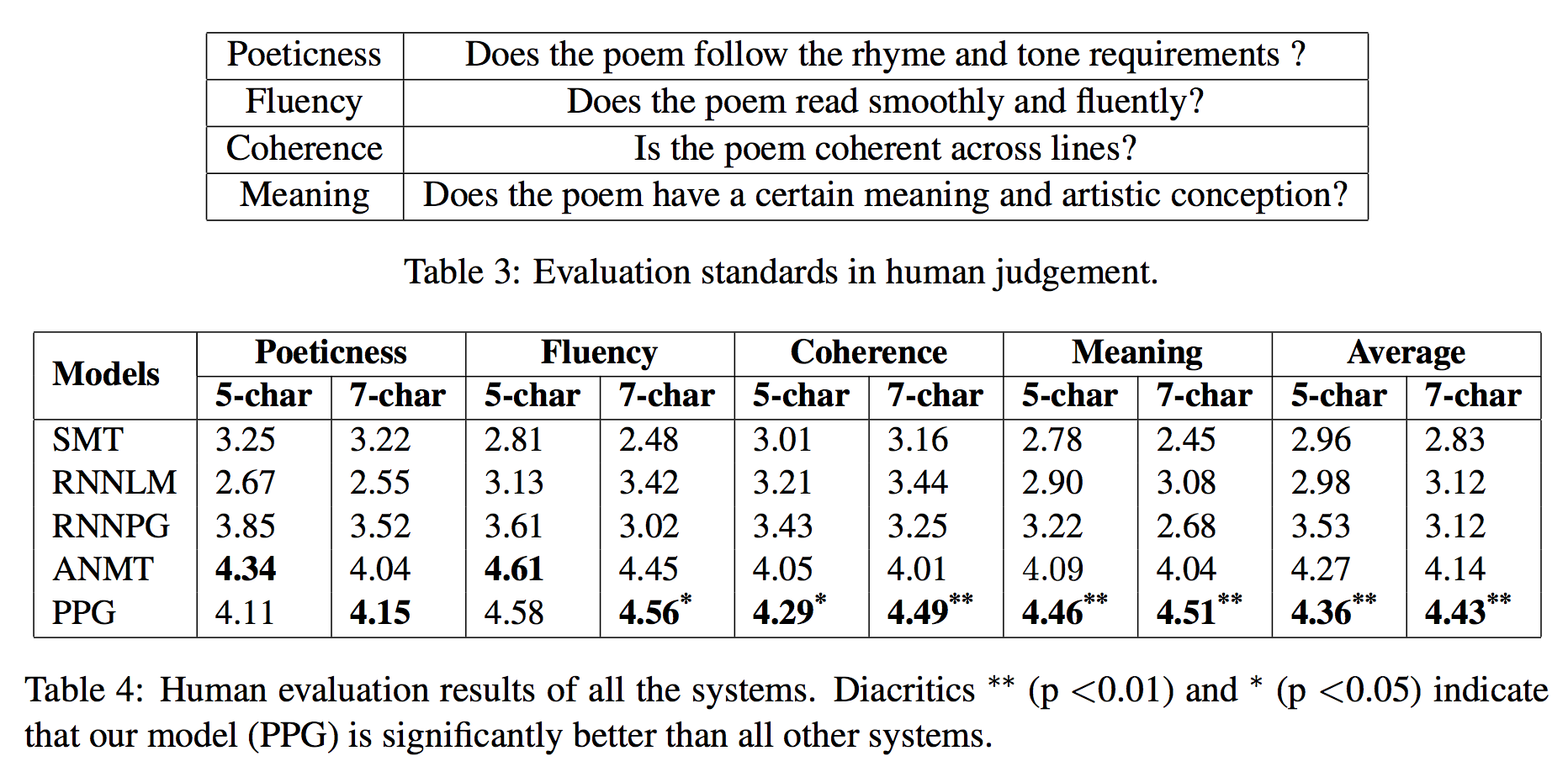
こんなに高い評価なら人間が作った詩と区別できないんじゃないの? と思いたくなります。
実はそんなブラインドテストもやっています。
被験者40人(うち4人は文学の専門家)に、人間が作った20の詩とコンピュータが作った20の詩を見せて、どっちがどっちか分けてもらうということやってもらったそうです。
結果は以下の表のとおりです。左から間違って分類した割合、見分けがつかなかった割合、正しく分けられた割合です。
ここからわかることは一般人(といっても学士以上の学位を持ってる人たちなので相当教養があると思いますが)にとってはかなり見分けがついていないようです。
一方で専門家にとっては機械が作った詩に不備があることを見出せているようです。

Author