Blog
[Strata Data Conference 2017 in New York] – Sessions Day2
アドテク本部の成尾と水野です。
引き続き、セッションの 2 日目について書いていきます。
水野からは1日目同様、興味深かったセッションのみ抜粋して紹介します.
Foundations of streaming SQL; or, How I learned to love stream and table theory
こちらのセッションは,現在進行中のStreaming SQLの仕様策定について解説しているセッションでした.
TableとStreamの概念,その中でのBeamの役割の解説があり,それを踏まえてStreaming SQLにどのような機能が組み込まれそうかが示唆されており,個人的には良セッションでした.

まずは,TableとStreamの関係性の部分から解説していきます.
Streamで流れてくる要素を時間ごとに集約して出来上がるものがTable,逆にTableの変化を時間ごとに観測したときの変化がStreamであると考えられます.

因みにStream処理では,データセット全体に対して一気に処理を適用するのではなく,一つ一つの要素(あるいは小さなグループ)に対する処理を記述するのが一般的です.このように記述することで,大きなメモリがなくても,大規模なデータや,事前に大きさのわかっていないデータに対してもロバストに処理を実行することができます.(Fileなどから全データセットをメモリに全乗せしなくても処理できるため)
発表中のものと違う例にはなりますが,SparkのDataFrameに対するmap処理で例を示します.最初データ集合はDataFrameの状態でTableに相当する状態です (ファイルなどからDataFrameを作る場合,この時点でデータがメモリに乗るわけではないです).これに対しmap処理は次のように記述します.
|
1 2 3 4 |
val df = ... // DataFrame (Tableに相当) val mappedDF = df.map { row => // mapの出力結果であるmappedDFもまたTableです. // some processing to a row // (ここでrowはstreamの1要素に相当) } |
このmapの中に渡ってくるrowがstreamに相当する部分で,記述しているのは1要素に対する処理です.
下の図の通り,最初はTableの状態のデータ集合に対し,map処理を適用している最中のデータはStreamの状態となり,その処理結果として再びTableで出力されるという関係になります.
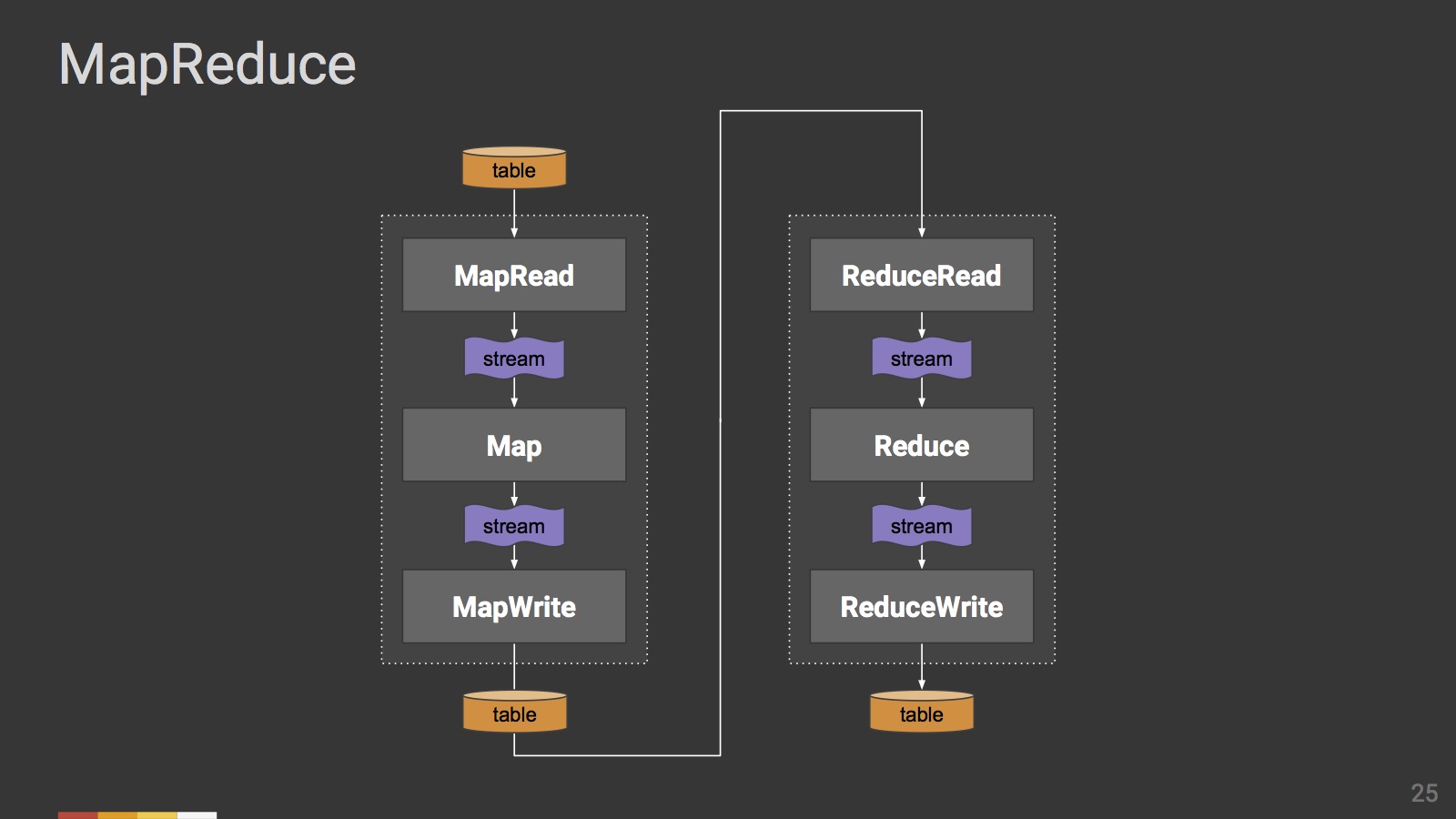
これらの定義の中で,BeamはStreamからどのようにTable生成を行うかを汎用的に記述するためのモデルと捉えることができます.他でもよく見る説明ですが,Beamでは以下の4つを規定できるようになっています.
| What | 各Stream要素から何を計算するか |
| Where | どのイベントタイムのデータを対象に計算を行うか |
| When | いつ計算結果をTableに反映するか |
| How | 出力されたTable同士をどう関連づけるか |
コード上では,以下のような記述になります.
|
1 2 3 4 5 6 7 8 9 |
PCollection<KV<User, Score>> input = IO.read(...) .apply(ParDo.of(new ParseFn()); // Whatに相当, 要素のparse .apply( Window.into(FixedWindows.of(Duration.standardMinutes(2)) // Whereに相当, 2分ごとの固定ウィンドウでイベントタイムごとに集計する .triggering(AtWatermark() // Whenに相当, Watermarkとして規定した条件を満たした時ににTableに反映する .withEarlyFirings(AtPeriod(Duration.standardMinutes(1))) .withLateFirings(AtCount(1)) ).accumulatingFiredPanes()) // Howに相当, 取り出したテーブルの値を累積する .apply(Sum.integersPerKey()); // Whatに相当, 特定のキーごとに要素の数値の合計を計算する |
因みにWhereとWhenは似ているように感じられるかもしれませんが,全く別物です.
Stream処理ではイベントタイム( ≒そのstream要素が発生した時刻)と処理時刻(≒そのstream要素がシステムに到着し,実際に処理される時刻)は明確に区別されます.Whereは前者のイベントタイムのグルーピング範囲を規定するもので,Whenは文字通りそれをいつTableに反映するかを規定するものです.(上の例だと処理時刻というよりは,条件ですが…)
これらのうちWhatだけを記述するものがBatch,WhatとWhereを記述したものがWindowed Batch,さらにWhenの記述を追加したものがStreamという扱いのようです.

さて,ここからが本題のStreaming SQLに関する内容です.(ここからは実際に資料の図を見た方がよりわかりやすいと思います,アニメーションでわかりやすく説明されているので)
従来のバッチ的なSQLでは,クエリ発行時刻1点のみに対し,その時点でのテーブルの状態が返されていました.しかし,Streamの概念が加わったことで,関係性は時事刻々と変化していきます.

このような変化を柔軟に捉えられるようにするために,Streaming SQLではいくつか構文の拡張が検討されているようです.
まず,Streaming SQLではTableに対するクエリとStreamに対するクエリを厳密に区別しています.
Tableに対するクエリは,従来のクエリと同様に,ある時刻における状態に対する問い合わせを記述するものですが,どの時点の状態を取得するかをクエリで指定できるようです.

少し見づらいと思いますが,SELECT TABLE …. FROMと明示的にTableだと指定している点.AS OF SYSTEM TIME ’12:01’と指定することで,実際の時刻は12:07なのに12:01時点での結果が得られているところに注目してください.
Streamに対するクエリの場合はTableの場合と異なり,継続的に各時点におけるクエリ結果が返されます.こちらはBeamモデルと同様に,What, Where, When, Howを記述するための構文が拡張されるようです.

Stream処理は大規模データをリアルタイムに観測するのに重要な技術で,カンファレンス全体でもまだまだ勢いのあるトピックでした.リアルタイムなメトリクスの可視化やデータの異常検知など,考えられる応用例はたくさんあると思います.
まだPreviewリリースですが,先日Streamに対するクエリエンジンの一つとしてKSQLもアナウンスされていましたし,BeamにもそのうちStreaming SQLの機能が組み込まれそうです.今後もこのあたりはウォッチしていきたいですね.
ちなみに現在仕様策定がどのように進んでいるかを知りたい方はこちらを見るとよさそうです.
The columnar roadmap: Apache Parquet and Apache Arrow
こちらはタイトルの通り,Apache ParquetとApache Arrowに関するセッションでした.
メインはApache Arrowの話で,Arrowがどういう目的のプロジェクトか,どのようなメリットをもたらすか,Parquetとの関係性はどうなっているかといった内容が紹介されていました.
本題のApache Arrowの説明に移る前に,Apache Parquetについて少し触れておきましょう.
Parquetは主にHadoop周りのシステムで良く使われているカラムナーのファイルフォーマットで,次のような特徴があります.
- カラムごとにデータ列がまとまっていることで,似たようなデータが近くに配置されるため圧縮効率が良い
- SQLのように選択的にカラムを読み出すようなワークロードでは,解凍およびスキャンする量が小さくなるので高速
- ネストした構造や,配列構造をカラム持つことができ,柔軟にスキーマを規定できる
実際に中身がどのようになっているのかというと,大まかには次の図の通りです.
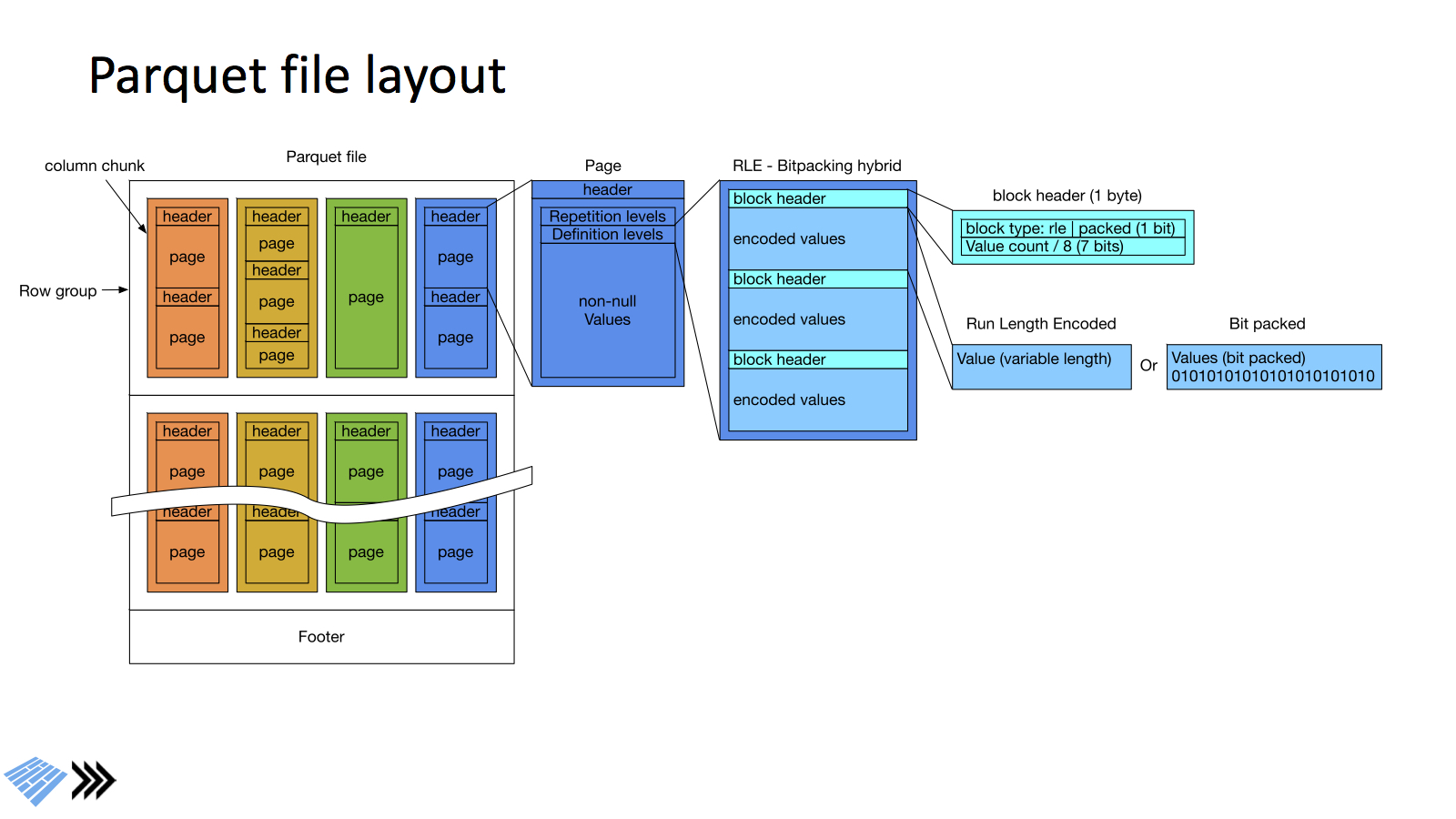
この辺りはDremelの論文の方が詳しく説明してくれているのでオススメです.(発表もDremelの論文を見てくれという感じでした)
ここでも論文中から例を借りて簡単に説明しようと思います.まず,下のようなデータがあると想定してください.

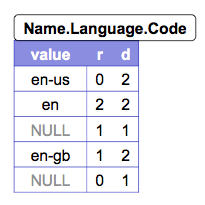
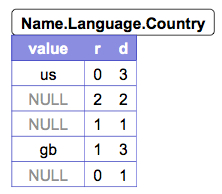
左の図が今回説明に使うデータです.図中の右上のものがデータのスキーマ,r1 , r2 がそのスキーマに沿って生成された実際のデータだと想定してください.真ん中の図,右の図は,それぞれName.Language下のCodeというカラム,Countryというカラムのデータ配置を表しています.レコードの再構築が可能な状態で配列やネスト構造を表現可能にするために,Parquetではデータの実部の他にRepetition level,Definition levelをカラム毎に保持しています (図中のr, d).
Repetition levelは,繰り返しが発生しているフィールドの深さを示す整数です.上記のスキーマだと,CodeというフィールドはName.Languageの配下に存在します.NameもLanguageもrepeatedなので,Nameフィールド,Languageフィールドいずれが繰りかえされることによってもCodeというフィールドは発生します.そのため,カラム毎にRepetition Levelを保持していないと,どちらの繰り返しによる値なのかがわからず,レコードの構造が一意に定まらなくなってしまいます.r1を例にとってRepetition levelを実際に計算すると,値が’en-us’のCodeフィールドは最初の出現なのでRepetition levelは0,値が’en’のCodeフィールドはLanguageフィールドが繰り返されたことによる発生なので,Languageフィールドの深さ2がRepetition levelとなります.同様に値が’en-gb’のCodeフィールドはNameフィールドが繰り返されたことによる発生なので,Repetition levelは1になります.
Definition levelは,そのカラムが属するフィールドのネスト構造で何階層目までがNULLでない値を持っているかを示す整数です.例えばr1において,Countryというフィールドは1度目のName.Languageの繰り返しでは’us’という値が存在しますが,2度目の繰り返しでは存在しません,すなわちNULLです.これを値のみでカラムにまとめてしまうと,NameがNULLなのか,LanguageからがNULLなのか,CountryだけがNULLなのかを判定できず,もとのレコードが再現できなくなってしまいます.Definition levelは,この曖昧性を解消するためのものです.r1を例にとって,Definition levelを実際に計算すると,値が’us’のCountryフィールドはName.Language.Countryと深さが3までの全てのフィールドが定義されているので,Definition levelは3です.2回目の繰り返しのCountryフィールドは値が存在しませんが,深さ2のName.Languageまでは定義されていた上で,Countryのみが存在しない状態です.よってDefinition levelはLanguageフィールドの深さである2になります.
Parquetでは,このように値を格納しておくことにより,ネストや配列を含むデータ構造をとれるようになっています.さらに,カラム毎にデータがまとめられているため,選択された特定のカラムのみスキャンし,レコードに構成した上で読みだせるようになっています.これらの特性から,HiveなどのSQL的なワークロードによく使われています.しかし,HiveやPandasなどのコンポーネントは,従来各々独自のデータフォーマットをもっており,データを読み出す際にはその形式に変換する必要がありました.こういった変換処理は無駄が大きいので,カラムナーのデータをカラムナーのまま,さらにシステム間でも統一的なフォーマットを利用することで,Diskからのデータロード,システム間におけるデータ連携のオーバヘッドを削減しようというアプローチを進めているのがApache Arrowというプロジェクトです.
それでは,いよいよ本題のApache Arrowについて説明しましょう.既に少し述べましたが,Apache Arrowはざっくり言うとメモリ上でのカラムナーフォーマットを定めるプロジェクトのことです.下記のような主要なオープンソースもこのプロジェクトに参加しようという動きがあります.
- Calcite
- Cassandra
- Deeplearning4j
- Drill
- Hadoop
- HBase
- Ibis
- Impala
- Kudu
- Pandas
- Parquet
- Phoenix
- Spark
- Storm
- R
こういったコンポーネントを跨いだデータの受け渡しの統一的なインタフェースとして,Plasmaというコンポーネントも提供されているようです.
また,Apache Arrowでは,最近のCPUで高いパフォーマンスが出せるようにメモリレイアウトが最適化されています.
ここでも公式ドキュメントの例を借りて,いくつか簡単にカラムの内部構造を紹介しましょう.
Primitive type
各カラムは64バイトごとの配列に区切られています.
例えば,Int32型の配列 [1, null, 2, 4, 8]だと次のようなバイト配列になります.
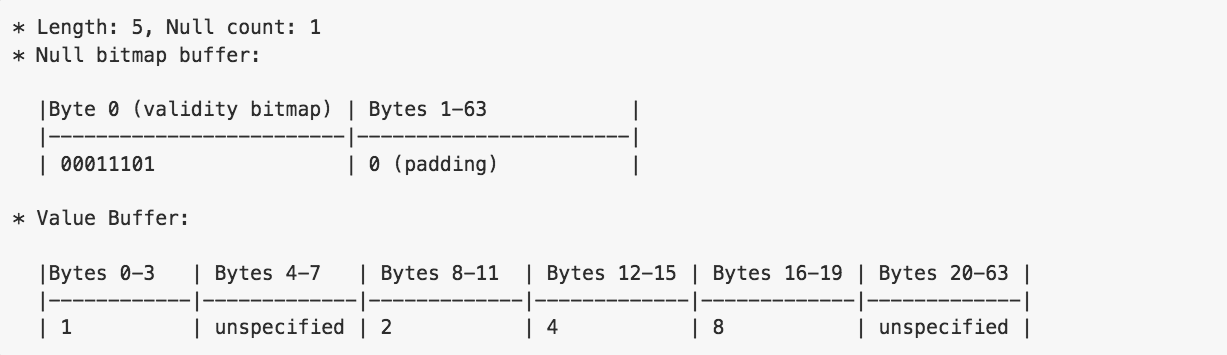
このようにPrimitive typeカラムの配列は,null bitmapとvalue bufferの組から成ります .
null bitmapには,value buffer中の対応する値がnullかどうかを表すビット列がLSB表記で格納されます.(つまり下位のビットがvalue bufferの上位インデックスに対応します)
この例だと値が [1, null, 2, 4, 8]で2番目のみがnullなので,bitmapはLSB表記で00011101となります.(最下位ビットから2番目が0)
64バイトに足りない部分は0パディングされます.
ちなみにこの64バイトというのは,cache lineに読み出すときにデータが中途半端に分割されてしまわないように調整しているようです.(こちらの記事を参照).この辺りは最近のCPUで高速にベストプラクティスに沿って設計されているんですね.
List type
List<Char>型の配列,[[‘j’, ‘o’, ‘e’], null, [‘m’, ‘a’, ‘r’, ‘k’], []]は次のような構造になります.
ちなみにList<Char>はString型の内部表現でもあります.

List型の場合,null bitmap,value bufferの他にoffset bufferが付随します.
これは各Listの先頭が,value bufferの何バイト目から始まっているかを表す整数列が格納されています.
上記の例だと,最初の要素であるJoeの先頭は0バイト目,その後のnullは3バイト目,markも3バイト目,空Listは7バイト目のスタートになるので,offset bufferには0, 3, 3, 7, 7という値が格納されます.null bitmapはPrimitive typeのときと同様に,2つ目のListのみnullなので00001101となります.
ここではPrimitiveな型とList型のみ紹介しましたが,他の型についても仕様が定められています.さらに詳細を知りたい方はこちらを読むとよさそうです.
ParquetとArrowはどちらもカラムナーでデータ構造が似ているので,メモリへの読み出し時のオーバヘッドも小さくなります.
発表の後半では,Parquetからメモリへの読み出し処理が紹介されていました.
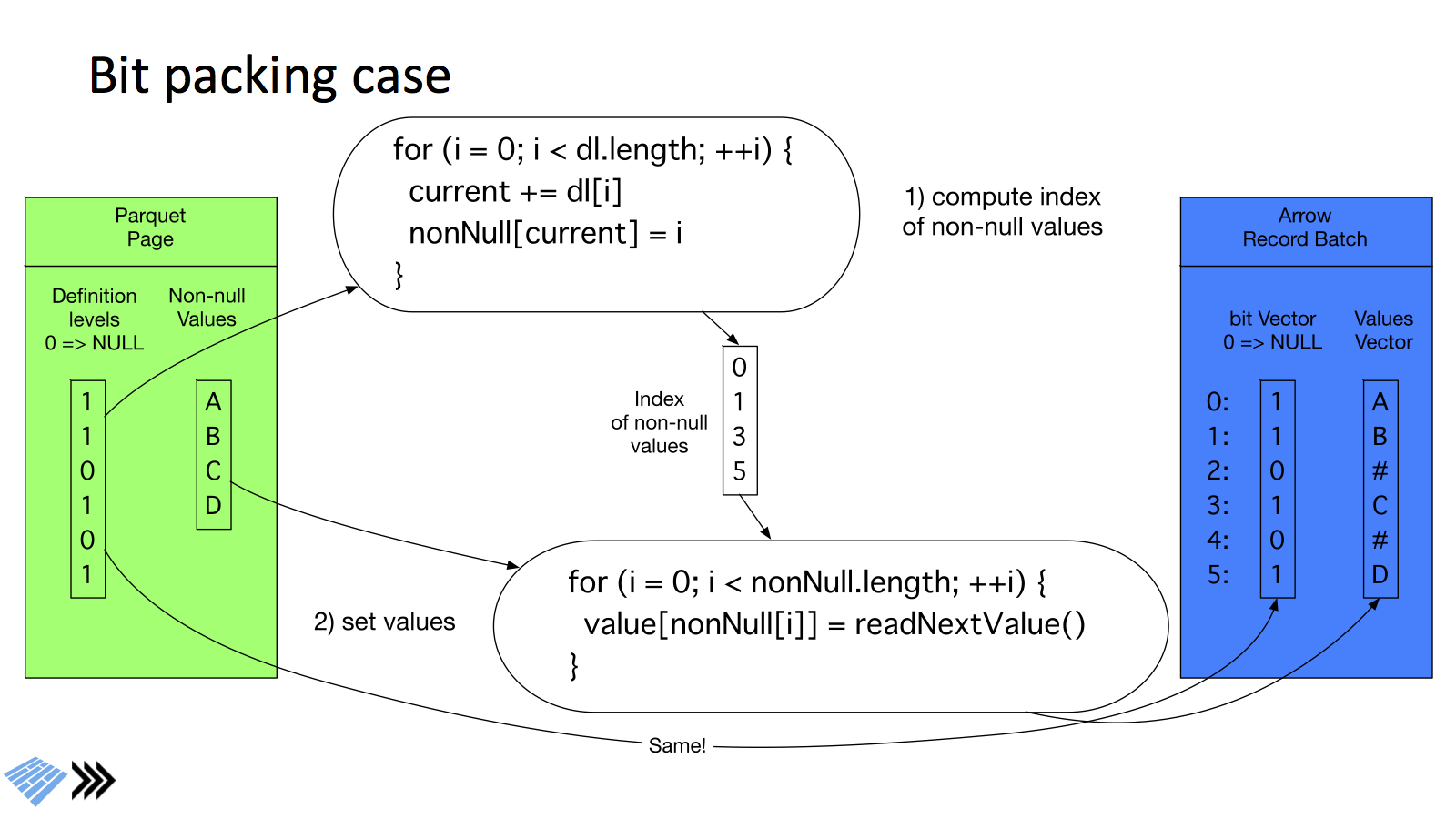
ネストのないスキーマのデータを考えると,parquet, arrowのデータフォーマットは次の図のようになります.

parquetとarrowでかなりデータ構造が似ているというのが,おわかりいただけるかと思います.
ParquetではDefinition levelとデータ列が存在し,Definition levelはDefinition level = そのカラムの深さのものは,値が存在することになります.(今回はネストがない構造を例にとっているので,0 or 1です).一方,arrowも前述の通り,null bitmapは値が存在すれば1,存在しなければ0になります.そのため,メモリに読み出す際に,データの構造を変形するような処理をほぼ必要としておらず,単にコピーするだけで済みます.そのためParquet => Arrowへのデータ読み出しは,従来と比べてかなり高速に動作するようです.
今までParquetはHadoop御用達フォーマットという認識が個人的には強かったのですが(完全に偏見です),今後はさらに利用シーンが広がりそうですね.単にPythonでJupyter Notebookなどを使って分析するという用途に対しても,Parquet形式でファイルに出力しておくとよさそうだなと感じました.
続いて成尾です。
この日は朝のKeynotsに興味深いものがいくつかありました。
Emotional arithmetic: How machine learning helps you understand customers in real time (sponsored by Google)
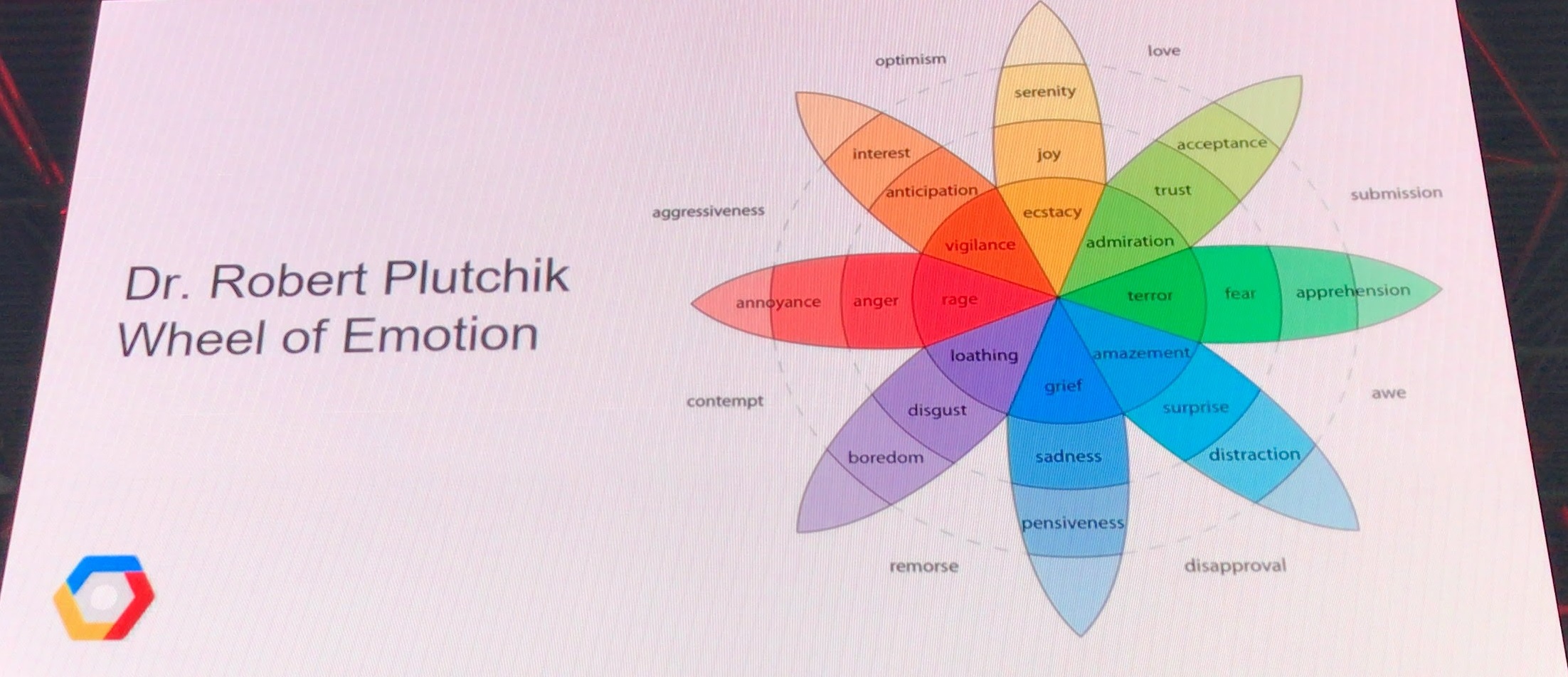
こちらは機械学習により、顧客から来るメールの文面からどのような感情なのか分析するというもので
まず色々な感情をカテゴライズしていました。
例えば Love = Trust + Joy など

その他詳細はこちら
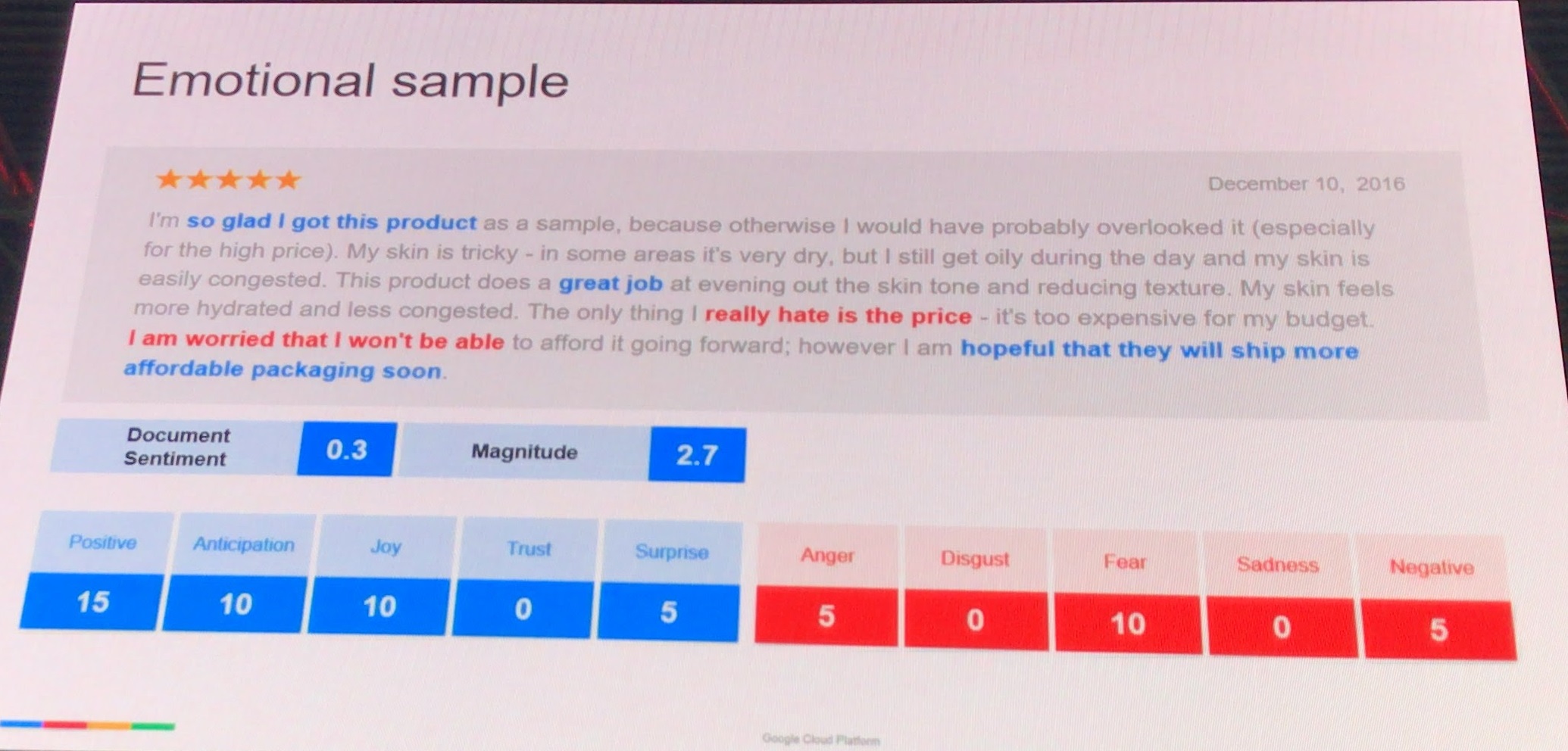
そして実際に届いたメールを分析すると以下のようになります。
アーキテクチャは以下
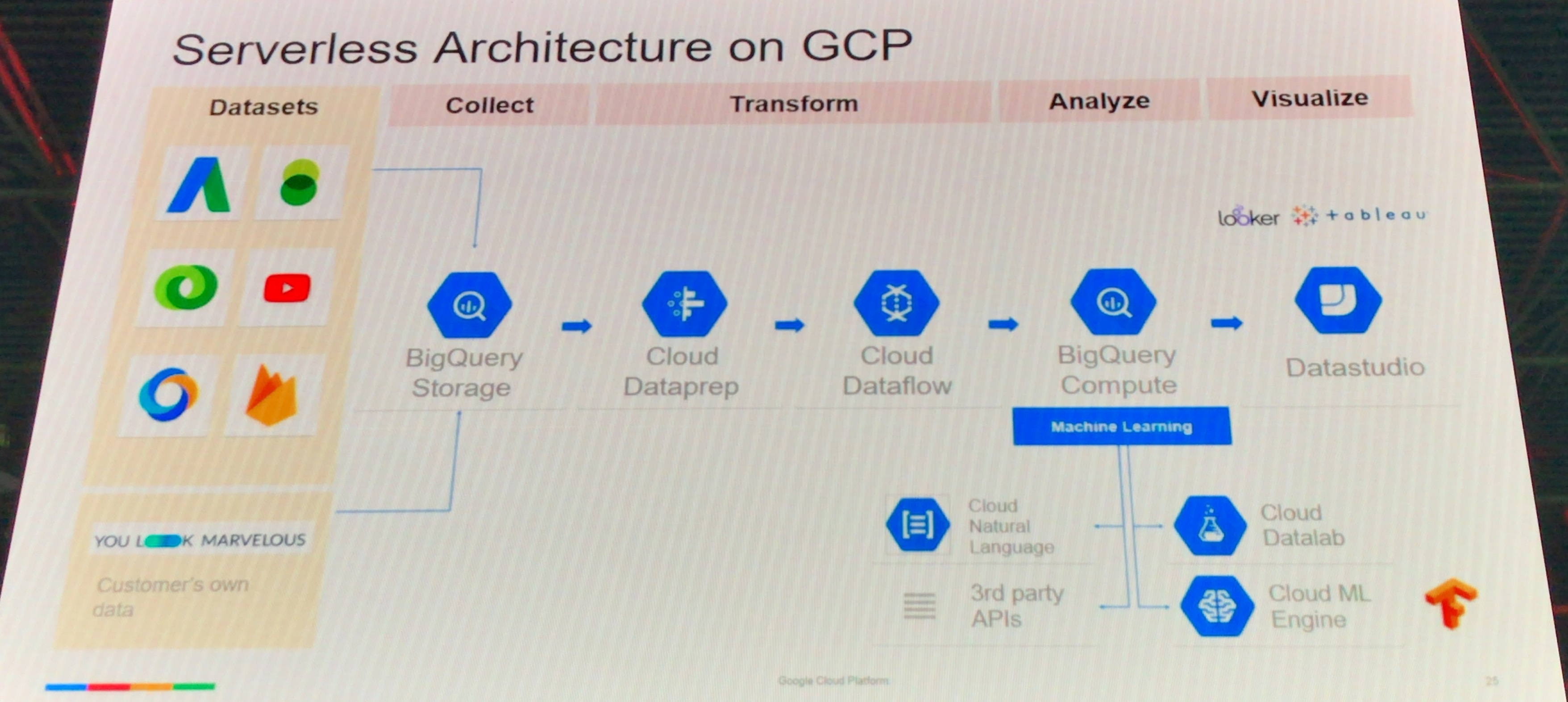
Harness the Power of AI and Deep Learning for Business (sponsored by NVIDIA)
こちらは写真撮り忘れたのですが
CPUの進化がほぼ止まっている中で、企業が持つデータの量は日々増え続け
GPUの進化が急成長している中、今後の分析はGPUを使ったものが増えるのでは、という話でした。
実際この後もGPUまわりのものをいくつか聞いてみたのですが
製品によっては注目度が高まっている(例えば、オープンソース化したMapDなど)のを感じましたが
まだまだ発展途上な領域で、デファクトスタンダードになりそうなものは見当たりませんでした。
GPGPU領域だとTensorFlowは、ますます伸びてくるのではと思っています。
以下はセッションです。
20 Netflix-style principles and practices to get the most out of your data platform
Netflix Data Platform の説明から
環境は AWS
S3 に 100 PB のデータ
kafka を 700 Billion イベントが日々流れる
Flink, Spark Streamingを使っている
d2.8xlが1000台以上
その他使っているもの
Presto, Redshift, GENIE, Metacat
※後半はNetflixが作っているものなのでリンクを張っています。
その後 Netflixでの原則など以下の項目について説明がありました。
#1 – North Star
#2 – Beware the local optimum
#3 – The recipe for the best solution!
#4 – Avoid analysis paralysis
#5 – Maybe you shouldn’t check that box
#6 – Question Everything
#7 – Articulate why and why not
#8 – Standardize when it makes sense
#9 – Paved Paths
#10 – The users own the platform
#11 – Visibility
#12 – You can’t have it all
#13 – Buy or Build
#14 – Beware of Icebergs
#15 – Grassroots innovation
#16 – Building Blocks
#17 – Polished Solutions
#18 – Set expectations
#19 – Tell vs. Ask
#20 – Safety Nets
#21 – Make it a shared decision
#22 – Some Bs and Cs are As
#23 – Put yourself in your uses’s shoes
#24 – Empower and trust people
パッと項目だけ見ても何の事かわからないものも多いとは思います。
例えば #12 だと例として以下のようなものがあげられてました。
何か選択するときに以下の3つのうち2つ以上または
バランスの取れたトレードオフ(全部成り立たないがバランスが取れている)ものを選ぶ

以下は2つ以上を満たすもの



過去話題に上ったこともありますが、「netflix culture」で検索してもらうと、膨大なスライドが見つかったります。
ここに書かれていることと同じよう内容が書かれているので、気になる方は一度検索して見てみてください。
Author