Blog
Apache Kafkaのすゝめ Part 1

アドテクスタジオでは、Apache Kafkaを利用するケースがここ最近増えています。
Apache Kafkaは、2011/01/11 LinkedInから公開されたOpenSourceで分散コミットログを通してpub/sub型を実装
オンライン/オフライン処理に対応しzookeeperを利用したスケールアウトを備えたオープンソースプロジェクトです。
これまではキュー処理といえばActiveMQ等を利用する事が多かったのですが
冗長構成が組め、スケール可能で1台あたりのパフォーマンスが良く、Sparkとの連携を考えた結果、Apache Kafkaの採用を進めました。
必要な構成は以下です(Zookeeperは最小構成が3台となります。)
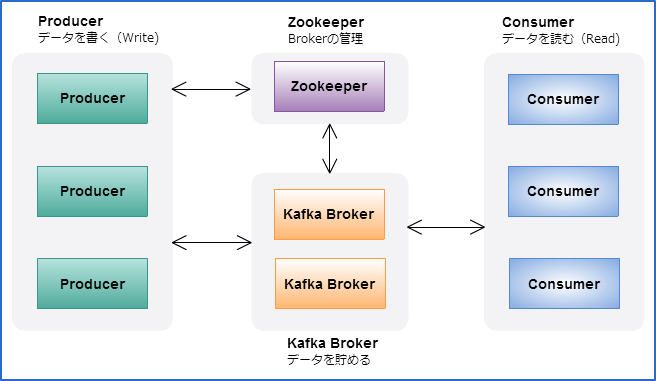
以前のバージョンではProducerもConsumerもZookeeperにアクセスする形をとっていましたが
現行のバージョンではConsumerはBrokerのListを保持しZookeeperではなくBrokerにアクセスする形になっています。
(弊社ではBrokerの増減に合わせて変更箇所を少なくするため、Virtual IPを持たせて運用しています。)
Push方式 BrokerがConsumerに送信しConsumerは受信待ちをする形態
Pull方式 ConsumerがBrokerにFetchリクエストを送りメッセージを受け取る
があるのでリアルタイムなキューイング処理からバッチ処理まで対応可能です。
またConsumer側を冗長構成にする場合にはハイレベルAPIを利用してConsumer Groupを作成する事で可能です。
ProducerからのメッセージはBroker側ではTopic内に保存します。(Topicは複数作成可能)
Topicはreplica, pertitionを指定できます。
kafka-create-topic.sh —partition 3 —replica 2 —topic test_topic–zookeeper zk_server1:2181,zk_server2:2181,zk_server3:2181
※上記だと二重化され(replica)3分割(pertition)され保存されます。
※弊社では、本番環境ではreplicaは3で運用しています。
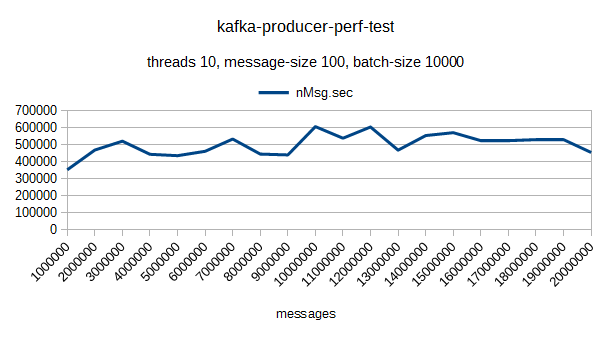
以下は弊社プライベートクラウド(CPU:4コア Memory:14GB SSD:128GB)1台環境でのベンチマーク結果です。
1台でも秒間にかなりの件数が処理できている事がわかるかと思います。
またBroker側でよく変更する設定を一部紹介します。
broker.id ID(ユニーク値)
log.dirs データが保持されるディレクトリ(複数,で指定可)
message.max.bytes (default:10000000) 受け取る最大サイズ(consumer側とも合わせる事)
num.io.threads(default:8) リクエストを処理するために使うI/Oスレッド(default:8)
default.replication.factor (default:1) 作成されたトピックのデフォルトレプリケーションファクター
num.pertitions (default: 1) トピック作成時に指定されなかった場合のパーティション数
log.cleanup.policy (default: delete) 古いセグメントファイルを削除(delete)するか圧縮(compact)するかの選択
log.retention.{ms, minutes, hours} (default: 7days) ログセグメントを削除するまでの時間(Topicのデフォルト保持期間)
その他同期送信や非同期送信、ペイロード圧縮についてや、パーティションの設計思想や
接続、再接続等のZookeeperやConsumerの挙動、Sparkとの連携などについては長くなるのでまたの機会に紹介させて頂きます。
Author