Blog
Kaggleゼミ成果報告(Allen AI チャレンジ編)
Is your model smarter than an 8th grader?

こんにちは、CAリワード配属新卒2年目の阿部です。
KaggleゼミでAllen AIチャレンジに参加していたので、その成果と感想を紹介したいと思います。Kaggleを簡単に説明すると、「世界一のデータ解析コンペ」です(KaggleとアドテクスタジオKaggleゼミの詳細紹介はこちらの記事を御覧ください)。
今回私たちが参加したコンペティションは2015年10月7日から2016年2月13日の間に開催されていた 「The Allen AI Science Challenge」で、自然言語の質問を人工知能のコンピュータプログラムで回答するチャレンジです。人工知能、自然言語処理、情報検索の研究分野では、「質問応答」というセクションがありますが、古くから盛んに研究されており、様々な手法が提案されてきました。今回のコンペでは、この質問応答分野の知識を応用して、チャレンジしてみました。
結果は170チーム中41位で、ぎりぎり上位25%に入ることができました。残念ながら上位10%まではいけませんでしたが、Kaggleの中でも難易度の高いチャレンジだったので、なかなか健闘したかなと思っています。
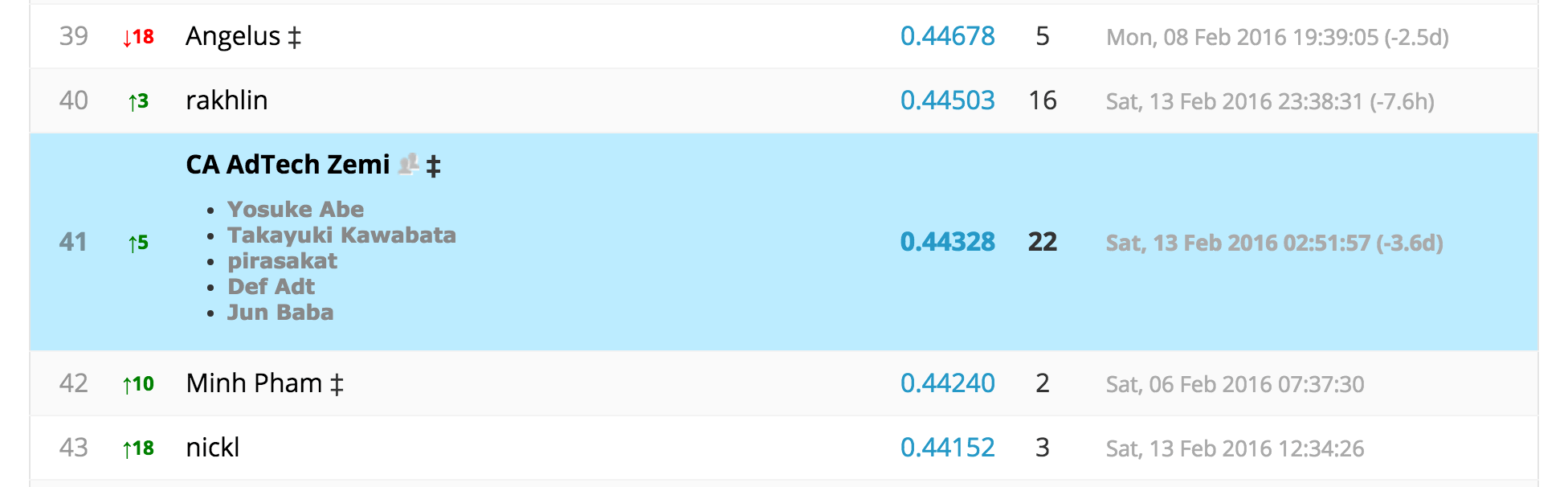
The Allen AI Science Challengeの紹介
The Allen AI Science チャレンジとは、マイクロソフト創業者の Paul Allen さんが作ったAllen 人工知能研究所 (Allen Institute for Artificial Intelligence)により提案されたKaggleコンペティションです。コンペティションのホームページはこちらにあります。この記事では、このAllen AI Science チャレンジを「AI2チャレンジ」または「AI2」で略記します。
AI2 では、中学校2年生の科学質問をコンピュータで回答するというのがタスクです。即ち、理科の質問と応答で、中学校2年生と同じぐらいの「知能」を持つコンピュータプログラムを作成する必要があります。この問題は人工知能の分野で大変重要な問題で、様々な研究がありましたが、まだ十分な精度に達成できる研究がありません。そこで、今回のチャレンジで人工知能の重要な問題の解決に貢献するというのが要旨だと思います。自然言語(英語)の質問をコンピュータで回答できるためには、最初にコンピュータに質問を「理解される」必要があります。そこで、この問題を解くために、自然言語処理がまず必要となります。次に、質問を回答するには、知識が必要であるため、知識表現、知識獲得や情報検索なども必要になります。従って、このAI2チャレンジに参加するためには、様々な人工知能、自然言語処理、情報検索に関する知識が必要となります。
データセット
AI2ではトレーニング用に2,500問、検証用に8,192問、テスト用に21,298問の問題が用意されており、それぞれの問題につき4つの回答候補が与えられます。例えば1問選ぶと、次のようなものがあります:
What is the main source of energy for the water cycle?
(水循環の主なエネルギー源はどれですか?)
A: electricity (電気)
B: erosion (侵食)
C: gravity (重力)
D: sunlight (太陽光)
このような、中学2年生向けの理科の問題となっています。
また、トレーニングセットには正解が含まれているため、作成したモデルによる解答と正解を直接比較することができます。AI2はステージ1とステージ2に分けられていて、合計およそ4ヶ月の開催期間のうち、最後の1週間がステージ2となっています。参加者はステージ1では検証用データを使い、ステージ2ではテスト用データに回答して結果をkaggleのサーバーにアップロードします。テスト用データはステージ2の期間に公開されました。
ステージ1には700を越えるチームが参加していましたが、本番であるステージ2に参加したのはそのうち170チームでした。ステージ1で思ったようにスコアが上がらなかったチームはステージ2に参加しない傾向があったので、ステージ2はスコアが上位層のチームによる決勝リーグのような形になりました。。
提案手法
上記で述べたように、AI2では、人工知能、自然言語処理の多くの技術が要求されています。私たちのチームでは、まず重要単語抽出、Word2Vecなどを利用して、複数の比較的に単純な手法(一つの手法は一つの学習アルゴリズムまたはExpertと言われています)で答えの候補を出します。次に、各々のExpertが出したスコアや重要な特徴量を組み合わせて、総合評価する分類器(Gradient Boost Decision Tree – GBDT)に入れ、最終の回答を決めました。
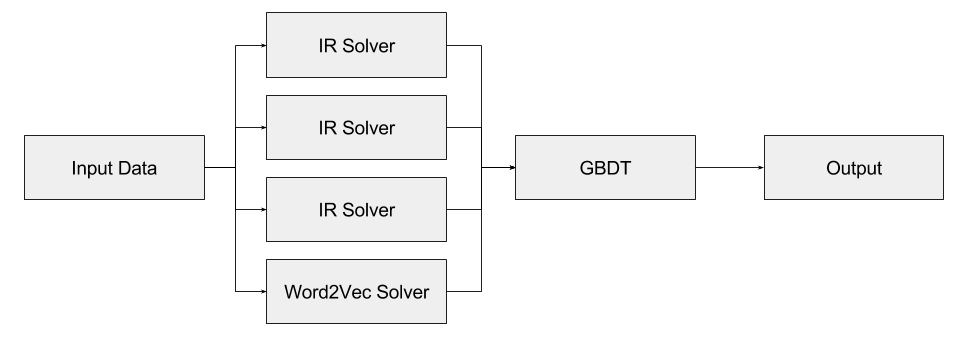
IR Solver (Information Retrieval based solver)
重要単語抽出による Expert として、情報検索に基づくソルバー (IR Solver) を考えました。IR Solver は Wikipedia と CK-12 の2種類のデータソースから、別々に作りました。1つ目のWikipediaのデータはXMLで公開されているため、記事のタイトルと文章を抽出するためのスクリプトを書いてElasticsearchにページ毎にデータを投入し、情報検索できるようにしました。2つ目のCK-12とは、CK-12 Foundationが無料で公開している教科書です。こちらはepubという電子書籍のために使われる形式で公開されていました。こちらも同様に文章を抽出するスクリプトを書いてElasticsearchに投入しました。
ElasticsearchはLuceneベースの検索エンジンです。Elasticsearchでは検索クエリを実行すると、登録したドキュメントに対するスコアが得られます。このスコアは類似度を表していて、スコアが高いほど類似度が高いということを意味します。
IR Solver の基本的な戦略は
- 問題文および回答候補からキーワード抽出
- 検索クエリの作成・実行
- 検索結果の評価および回答
となります。まず、キーワード抽出方法は発生頻度の低い単語がキーワードであるいう考えを基に抽出しました。具体的にはWikipedia、CK-12、問題文や解答候補の中から単語の発生頻度が小さい順に並べ、上位数件の単語をキーワードとしました。次にそのキーワードを用いて、検索クエリを作成します。検索クエリは各回答候補それぞれに対して作成します。そのため、1問につきクエリが4つ作成されます。Elasticsearchでは様々な条件で柔軟に検索クエリが作成できるため、いろいろなパターンを試みました。最後に、クエリを実行してドキュメント毎に得られるスコアを評価し、高いスコアが得られたクエリに対応する解答候補を最終的な回答として出力します。キーワード抽出手法や検索クエリの作成や評価手法などのパターンを変えながら、複数のIR Solverを作りました。
Word2Vec Solver
Word2Vec Solver では、まず膨大なコーパス(Wikipedia)で単語のベクトル表現を学習しました。次に、質問文と回答の候補となる文を単語に切り、各単語のベクトル表現を取り出します。文をベクトルで表現として、文の中の単語のベクトルの平均を取ります。このステップの後、質問文と回答候補文はベクトルで表現できるようになります。最後に、質問文と各回答候補文のコサイン類似度を計算して、一番類似度が高い回答文を回答として出力します。
このソルバーはすごい単純な類似度計算をしていますが、Word2Vecを利用することによって、単語間の関係を表現できるので、質問文と回答文で関連単語があるとよく働きます。
アンサンブル学習
最後に各Expertが出した解答候補やスコアなどを特徴量とし、GBDTを使って特徴量を総合評価して解答を決定しました。このような手法をアンサンブル学習と呼びますが、この手法により、単独のモデルのベストと比較して12%ほど正答率を向上できました。最終的な正答率は44%となりました。
結果改善のプロセス・工夫点
4択クイズに答えることは様々な手法を組み合わせることにより実現するため、改善するための選択肢も無数にあります。今回の提案手法について、最適化できそうなポイントを挙げてみると、
- IR Solver
- データソースの選定 (Wikipedia, CK-12など)
- 文章構造化の粒度
- 文章処理 (stemming, lemmatizationなど)
- キーワードの抽出方法
- 検索クエリ
- 検索結果の評価方法
- Word2Vec Solver
- 学習に使うデータソースの選定
- ハイパーパラメータのチューニング
- アンサンブル学習
- 分類器の選定
- ハイパーパラメータのチューニング
- 特徴量洗い出し・選定
などがあります。
始めのうちはIR SolverやWord2Vec Solverとは違った考え方のExpertが作ることに注力しました。しかし良さそうな方法が思いつかなかったり、思いついても実現がとても難しそうだったりで、結局、IR Solver と Word2Vec Solver の2種類だけのExpertを使うことになりました。
また、問題文は単語で答える形式や文章で答える形式、穴埋め形式などがあったので、そのパターンを分類して個別にExpertを作れないかということも試そうとしました。しかしこれも具体的な良いアイデアが浮かばず、挫折してしまいました。しかしAI2が終わったあとで勝利者のインタビューを見ていると、問題と解答のパターンをアンサンブルするときの特徴量の一つとして使っているようでした。せっかく分類まではできていたので、特徴量として使えば正答率が少し改善していたかもしれません。
AI2ではオープンデータを利用してよいので、まずはWikipediaを使ってみました。その理由はデータ量が多く、科学に関する記事も多いので最適と考えられたからです。ただデータサイズが50GB程度と大きく、扱いに苦労しました。stemmingなど文章の処理に時間がかかる上、Elasticsearchにデータを投入するのにも時間がかかります。Wikipedia以外にはCK-12教科書も使いました。これはWikipediaよりも文章量はかなり少ないですが、その割には結果に与える影響が大きかったです(教科書そのものなので当然といえば当然ですが・・)。
キーワードの抽出方法や検索クエリのパターンも無数に考えることができます。Elasticsearchでは様々な検索クエリをサポートしています。AND検索やOR検索はもちろん、単語の重み付けや、トークナイザを選べたりもします。そのため検索クエリの作り方を変えながら何回も試行錯誤しました。計算量が多く、トレーニングデータ2,500問処理するだけでも10分以上かかってしまうので、トライアンドエラーを繰り返すのが大変でした。
Elasticsearchでは検索クエリを実行することで、ドキュメント毎にスコアが返されます。検索結果の評価手法としては、スコアの上位何件まで使うのか、上位の平均を使うのか、重み付けするのか、などの選択肢があります。これは地道に少しずつ変えながら何回も試行錯誤し、良い結果のものを選びました。先程も述べたとおり、普通にやるとトレーニング用データを処理するのに10分以上かかってしまうため、検索結果をキャッシングできるようにしました。キャッシングにより数十秒で処理できるようになり、結果改善のプロセスを高速化できました。
感想
Kaggleのオフィシャルブログに、AI2で3位になったMosqueraさんのインタビュー記事が掲載されています。記事を読んでみると、IRやWord2Vecを使ったExpertなど、共通点も多い印象です。
面白いと思ったのは、各Expertが問題の回答としてAnswer A, Answer B, Otherのように3クラスに分類しているというところです。基本的にExpertの答えはあまり信用出来ないため、上位2つを回答させることでパフォーマンスが大幅に向上したと主張しています。大きく違うと思ったのは、MosqueraさんのモデルではWikipediaを使っていないところです。Wikipediaでは答えることができる問題は多いが、ノイズにもなりうるとのことです。データソースとして、 Quizlet API と CK-12 を使っていたそうです。
その他には、stemmingではなくlemmatization処理をしていることや、アンサンブルにリニアモデルを使っているなどの違いがありました。lemmatizationは処理が重いので諦めてしまいましたが、実は効果が大きかったのかもしれません。アンサンブルのときにはリニアモデル以外にもxgboostとRNNを試したと書いてありますが、意外にもシンプルなリニアモデルのほうが結果が良かったようです。
今回のチャレンジを通して、自然言語処理や機械学習、Elasticsearchを使用した情報検索などが学べました。チャレンジを始める前は質疑応答システムなどの知識はまったく無く、正直なところ正答率が25%(4択クイズなので)超えればすごいなとさえ思っていました。それが最終的には正答率が44%になり、順位でも上位25%以内になれたので、何でもとりあえずやってみることが大事だと思いました。
Author